
Anthropic 公告里最刺眼的 3 个名字,有 1 家中国模型
每周都能从Anthropic那边翻出新乐子看,这几乎成了最近一个月科技圈的保留节目。
故事还得从6月初说起。Anthropic秘密递交IPO文件后,转头就发了一篇万字长文,警告自家的最新模型Claude Fable 5/Mythos 5能力强到应该被限制使用。
几乎同一时间,大客户AWS也跟上节奏,给美国政府递了一份秘密报告:没错,Fable 5发现和利用零日漏洞的速度,已经远超人类的修补速度,会引发严重网络安全风险。
结果,这一唱一和之间,两份原本打算用来炫耀的报告,倒是成了美国政府强制封禁Anthropic新模型全球访问的投名状。不过这一次,不只是其他国家用户没法用,连Anthropic内部的外籍员工也被一起禁了。
PR做过了头的Anthropic赶紧改口,表示AWS说的那个漏洞发现能力,GPT-5.5也能做到,这才换来美国政府的有限松绑。
但故事还没完,6月30日,Anthropic又发新文,说AWS说的那个问题,其实Claude Opus 4.8、GPT-5.5、Kimi K2.7也都能实现。

有意思的是,Anthropic这回不仅拉上了老对手OpenAI,连国内的Kimi也被一并带上了。
01 国产模型,这次真的不一样了
01 国产模型,这次真的不一样了
过去两年,如果你问一个国内AI从业者什么是“中转站”,答案清一色:那是帮国内用户连接海外Claude和GPT的灰色通道。
那时候,围绕中国大模型,标签特别固定:便宜、能用、但上限不高,做聊天机器人还行,但复杂任务的表现嘛,差强人意。
但这个叙事,从今年年初开始,悄悄翻转了。
一批中转站开始反向操作:把K2.6、DeepSeek V4这些国产模型的API中转出去,销往全球。
当然,我们不推荐也不提倡这个行为,毕竟转售、出租、分销API Token或账号是官方明文禁止的。但这足以说明,全球客户采购中国模型的原因,已经从“便宜”变成了“性价比+技术领先”。
《经济学人》在盘点2026年AI市场时,特地花了不少篇幅分析这个转变:中国模型在海外的认知,正从“廉价替代品”向“可被严肃采用的技术供给”迁移。
判断起来有点抽象,但用户确实在用脚投票。
Coinbase首席执行官Brian Armstrong不久前在X平台发文盛赞GLM 5.2和Kimi K2.7:
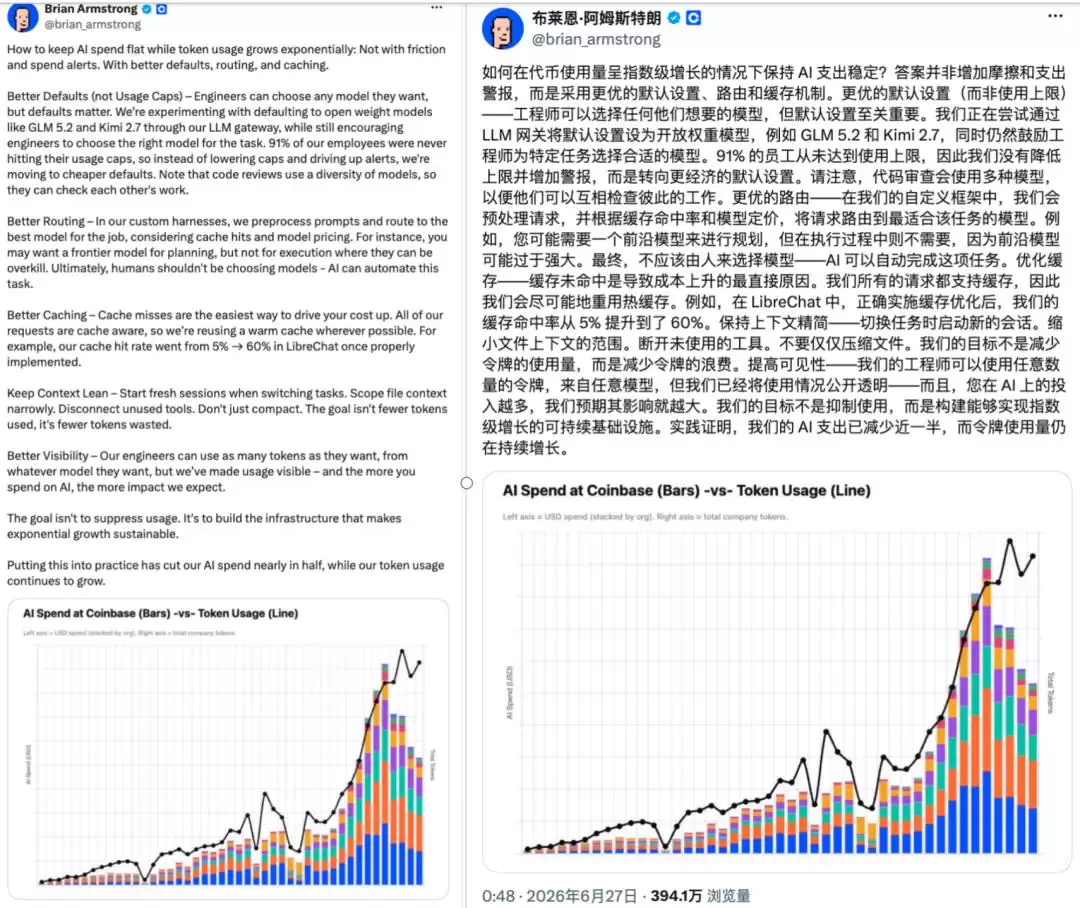
91%的员工根本不需要所谓的极限模型能力。与其限制他们用AI,不如把默认模型切成GLM 5.2、Kimi 2.7这类高性价比选手;再通过LLM网关按任务自动路由,缓存命中率就能从5%提到60%。
最终效果很明显——借助国产模型,Coinbase的AI支出削减近一半,token使用量却仍在指数级增长。
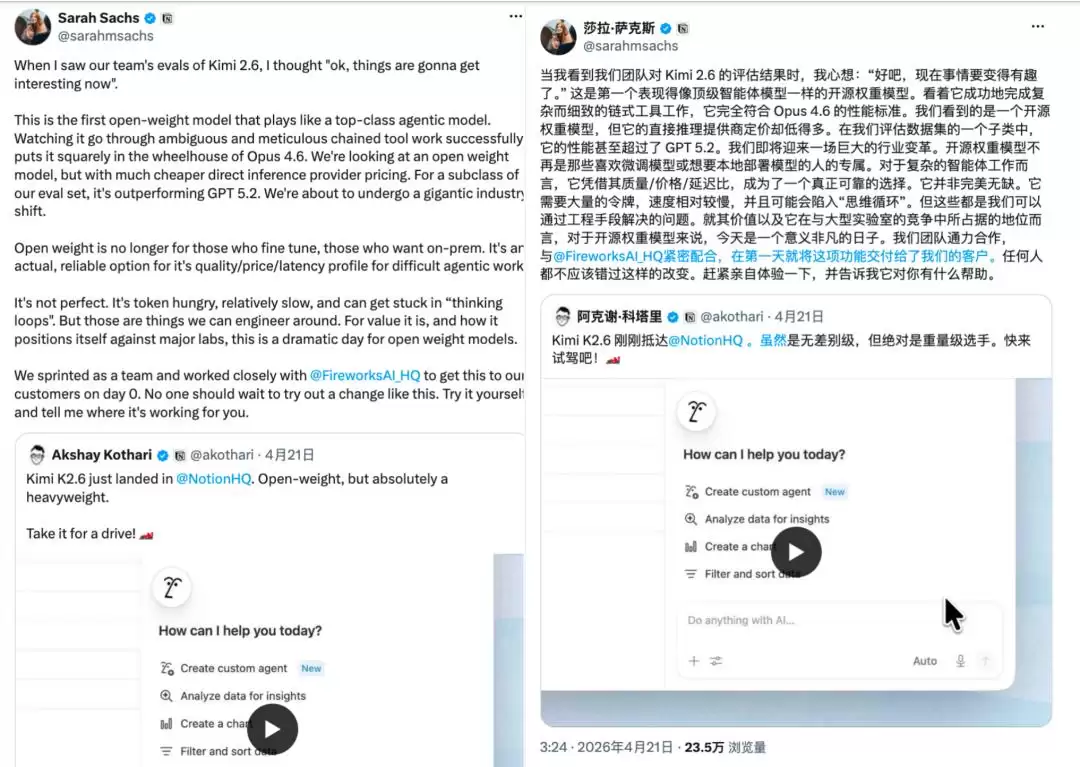
这还真不是个例。过去一年,光是公开发生的国际大厂切换国产模型案例就包括:Airbnb将主力客服模型从GPT切换至千问;AI公司Lindy从Anthropic Claude迁移至DeepSeek V4;查马斯・帕里哈皮蒂亚旗下公司把核心业务从Anthropic Claude迁移至Kimi K2;Cloudflare把AI安全Agent等生产任务从自研与海外闭源模型切换为Kimi K2.5;HolySheep客服中台从单一OpenAI切换为Claude与Kimi混合架构;Notion团队的AI负责人也公开官宣接入Kimi K2.6,并表示K2.6是首款具备顶级智能体能力的开源模型,部分任务性能对标Claude Opus 4.6,超越GPT 5.2……
02 到底哪里不一样?
02 到底哪里不一样?
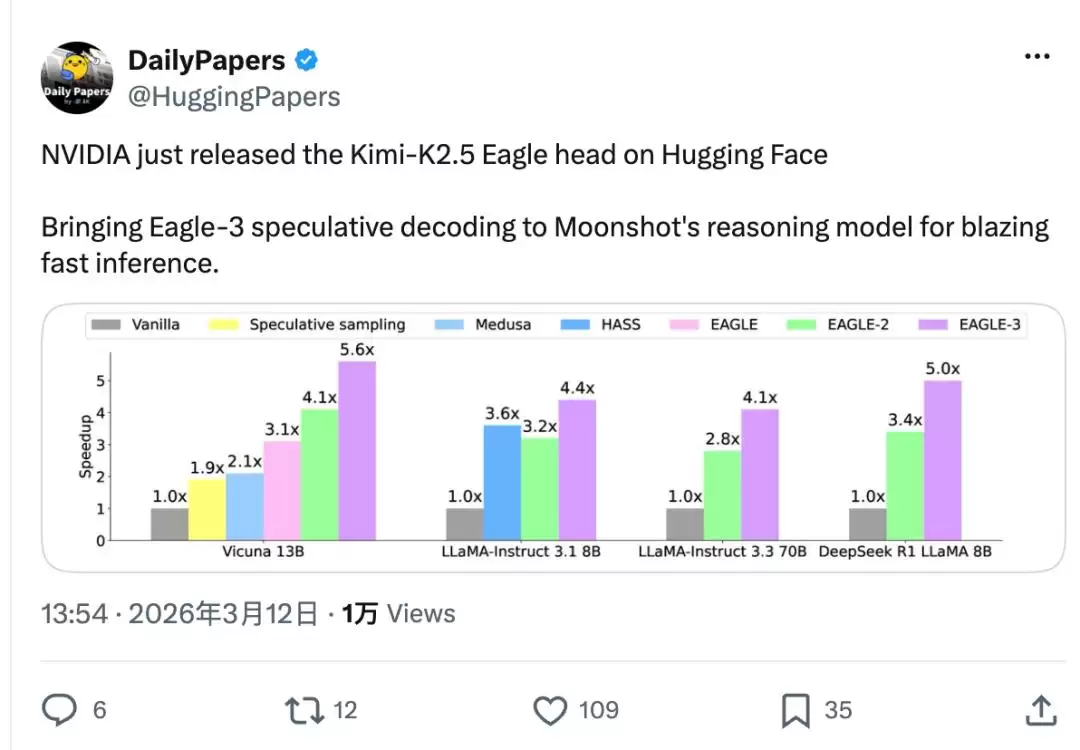
前不久的GTC 2026上,英伟达用来展示最新芯片推理性能的中国模型,只有DeepSeek和Kimi两家。

更早的时候,英伟达不仅第一时间适配Kimi,还抢先发布了针对Kimi-K2.5的Eagle speculative decoding方案——把第三代Eagle投机解码技术搭载到Kimi推理大模型上,实现极速推理。
技术层面,Kimi是最早押注MoBA改造Transformer注意力机制的玩家,同时也是最早把Muon系优化器推到万亿参数级训练并系统公开经验的团队之一。它这个思路后来也被DeepSeek V4借鉴,用来提升收敛效率和训练稳定性。
认知层面,早在2025年下半年,大多数同行还在聊天机器人赛道上卷上下文长度、拼榜单分数时,Kimi已经把Agent定为核心战略方向。9月发布“OK Computer”,让AI真正为人类完成任务;同期在预训练阶段加入大量工具使用和多轮规划的轨迹数据,直接用真实Agent场景数据训练。11月,K2 Thinking模型发布,原生掌握“边思考边使用工具”的能力,在“人类最后的考试”中拿下44.9%的成绩。到今年年初K2.5发布时,Kimi的Agent能力已经进化到集群级别——能根据任务需求现场调度多达100个分身,并行处理1500个步骤。
不一样,就源于国产模型在认知上的领先和技术上的突破。
03 Anthropic 让中国模型又爱又恨
03 Anthropic 让中国模型又爱又恨
从业务结构上看,哪个中国模型公司更像Anthropic?带着这个问题,我们请教了几位行业大佬和投资人,答案惊人一致——
Kimi。
这种相似,不只是表面上的技术路线,也包括了商业内核的高度趋同。
首先是增速的相似。
尽管全球AI市场仍处于早期阶段,Kimi的营收在全球企业AI支出中占比依然极小。但从增速来看,Kimi确实在走Anthropic的老路。
Anthropic 2026年2月ARR达140亿美元,3月升至190亿,4月突破300亿并反超OpenAI,5月进一步飙升至440–470亿美元,半年内增长超3倍。
Kimi的轨迹几乎复刻:2026年1月K2.5发布之后,公司20天收入就超过2025年全年;并在3月初达到1亿美元ARR;截止6月底,相较3月初又实现连续3倍加速增长。
其次是收入结构的相似。
在开发者群体中,经常被拿来与Anthropic对比的国内模型一般有三家:DeepSeek、GLM、Kimi。其中智谱的营收中,到2025年约有73.7%来自定制化收入,DeepSeek与Kimi的营收则主要来自API收入,和Anthropic高度相似。
关于Kimi,目前有内部信息显示,Kimi的API收入占比已达70%左右,团队规模却只有约300人。
翻译一下:几乎没有定制化项目,没有重人力的交付团队,完全是产品主导的高毛利增长模式。
Anthropic那套毛利率很高所以估值合理的叙事,Kimi同样可以讲,而且讲得更轻。
甚至,Anthropic在Coding场景的崛起路线,也在大客户的助攻下,被Kimi半被动地复刻了。
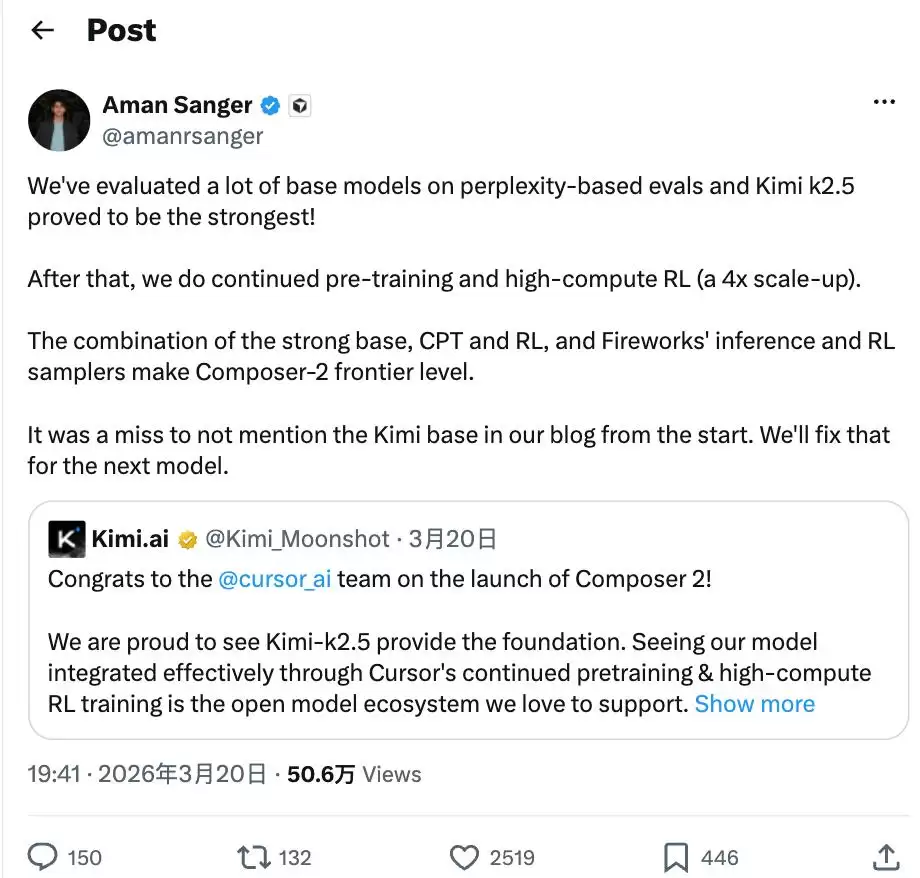
图源:Cursor公司创始人Aman Sanger的X截图
众所周知,Anthropic营收超越OpenAI的核心在于coding场景:用户刚需强、付费能力也强悍。而巅峰时期,Cursor贡献了Anthropic约40%至50%的收入。
但2025年5月,Anthropic发布了Claude Code,仅用半年多时间,Claude Code年化营收就冲到25亿美元,抢走了大量Cursor用户。再到2026年初,Anthropic宣布收紧第三方访问权限,又给Cursor补了一记重击。
按理说,Cursor应该一蹶不振了。
但Cursor不仅没死,还在同一时间拿出了Composer 2还击。
作为一款用Kimi 2.5训练出来的编程模型,官方数据显示,它在多项编程基准测试中甚至超过了Claude Opus。
再后来,马斯克出手了。SpaceX以约600亿美元全股票交易收购Cursor。
左手是Kimi贡献的基模能力,右边是SpaceX数十万张顶级AI芯片组成的超算集群提供海量算力,再加上自身数年积累的优质数据——
颓势边缘的Cursor,又靠着国产模型奇迹般地复活了。
而这某种程度上也意味着,Kimi不仅是海外各大应用厂商讲述性能、成本和资本市场能力的最佳叙事组成,还成了Anthropic在上市前夕讲述其独一性故事的绊脚石之一。
毕竟,同样是API收入主导的高毛利模式,同样是借助coding逆袭超车,截止目前,Anthropic上市前的最后一轮投后估值达到了9650亿美元,但Kimi新一轮投前估值也达到了315亿美元。




