
Token计算:下一个十年的成本战争
Token经济,正在成为AI行业近期最热的关键词之一
当OpenClaw(俗称“龙虾”)成为全民关注点,各大厂商纷纷加入“龙虾潮”时,一个现象变得尤为明显:Token的消耗开始呈现出指数级的增长趋势。
在开发者社区和社交平台上,各类对比表开始频繁出现,大家热衷于计算在不同模型上的Token消耗、输出质量差异,以及折算下来“每千Token成本”究竟谁最低。
然而,如果真的试图用Token来算一笔清晰的经济账,很快就会发现,事情已经没那么简单了。
前几天,一位做财务的朋友问了这样一个问题:他们公司的AI智能体每天有几十万次调用,一个月下来到底要花多少钱?
这听起来是个基础问题,似乎用“Token单价×调用次数”就能轻松得出答案。
但实际操作时,翻开Anthropic的价格页打算粗略估算,结果却让人犯了难。
Claude Managed Agents的会话运行时长按“每会话·小时”独立计费,缓存写入和缓存命中又各有不同的计价乘数,这些费用项与Token根本不在同一个计量维度上。
于是,将几家主流平台的价格页逐一翻看一遍后,发现这件事远不是一道“干净的算术题”。
例如,OpenAI的价格页更像一张资源总账。除了Token,联网搜索按千次调用收费,容器按会话时长收费,文件检索存储按GB/天收费,区域处理还要额外叠加10%的费用。
Google Gemini的收费项相对收敛一些,但搜索增强和上下文缓存也被单独列为独立的计价项目。
Anthropic则采用三档缓存乘数,再叠加会话运行时长的计费,又是另一套体系。三家巨头的计费方式已经无法用同一个公式算清了。
如果再往上一层看,商品边界本身甚至脱离了“模型”范畴。Salesforce用Flex Credits将动作配额写进了价格体系,Intercom则干脆绕开Token,直接按结果收费——每个“有效解决”收费0.99美元,并对此有白纸黑字的定义。
一番探究后,唯一能确定的是:大家根本不是在卖同一种东西。
2026年1月,OpenAI首席财务官Sarah Friar在官网发表的《A business that scales with the value of intelligence》一文中,同时点明了其三条商业化路径:订阅、广告支撑的免费层、按用量计费的API。她还补充道,未来将扩展到授权、IP协议和按结果定价。连平台方自己,都不再用单一的“按用量计费”来描述其商业模式了。
过去,在比较各大模型时,行业里经常讨论“谁的Token更便宜”,这默认了一个前提:行业已经存在一个被广泛接受的统一计量单位,大家比拼的只是价格。
但到了2026年4月,现实情况是——Token早已不是AI账单里唯一的计费单位。AI商品正在从单一计量项走向多单位并存,企业的预算语言也随之被改写。
因此,本文想探讨的不仅是Token本身,更是梳理一条完整的变化路径:从收费方式的变化,到成本结构的分化,再到预算体系的调整,看Token经济如何被重新定义。
AI收费,告别“单一Token时代”
AI收费,告别“单一Token时代”
如果今天仍有人只讨论“哪个模型每百万Token更贵”,那看到的仅仅是底层供给的一部分。
真实情况是,企业目前购买的是一段被组织过的智能劳动,裸模型只是其中的一小部分。
它可能同时包含模型推理、搜索、检索、缓存、上下文驻留、运行时、容器、团队席位、动作配额,乃至一个被明确定义的“完成件”。AI经济正在经历的,不是一场简单的价格战,而是计费对象的扩散。
这里最容易出现的误读,是把“计费单位变多”等同于“底层模型已经不重要”。
但事实恰恰相反:
模型仍是底层最核心的供给对象,只是它不再是企业成本解释框架里的唯一变量。
一旦系统进入真实工作流,采购者与运营者就必须同时处理搜索增强、批量调用、区域路由、运行时长与席位切换,这些项目在同一张对账单上争夺预算。于是,账单不再是一列Token的简单累加,而是一组互相叠加的价格对象。
AI底层大概率会像电力一样,最终被压成公用事业:便宜、可计量、不可或缺,但也不再是价值最终停留的地方。
经济史上反复出现的模式是:电带来的生产率跃升,远比“有电就更快”复杂。让美国制造业真正起飞的,是工厂围绕电力重写了生产组织方式,而不是电力本身变得便宜。
AI成本,从统一定价走向按任务分化
AI成本,从统一定价走向按任务分化
过去习惯用“每百万Token多少钱”来理解AI成本,但今天这个锚点已经失效——账单的主角是谁,完全取决于你在跑什么样的任务。
先看一个轻量、高频、以检索为主的企业问答任务。
以Google Gemini 2.5 Flash-Lite标准档估算,5000输入Token加1000输出Token,成本约0.0009美元;若同一次调用附带一次搜索增强,超出每日免费额度后,单次增强价格约为0.035美元,这几乎是Token成本的四十倍。
在这类工作负载里,主导账单的是搜索或增强这类外层能力,模型推理本身反而退居二线。
然而,如果换成更强的前沿模型,图景就完全不同。
以OpenAI GPT-5.4标准档为例,同样的5000输入加1000输出Token约0.0275美元;一次联网搜索的工具调用费为0.01美元(搜索内容Token另按模型费率计);一次1GB容器会话为0.03美元。此时,模型成本仍与工具调用处于同一数量级,在许多推理密集任务中甚至占大头。
再看Anthropic官方给出的Claude Managed Agents示例:一个一小时的Opus 4.6编码会话,5万输入加1.5万输出的Token成本是0.625美元,而会话运行时长费用仅0.08美元。运行时虽然进入了商品列表,但远未“压倒”模型成本。
三个例子合起来指向同一件事:成本的大头在哪,取决于你让AI干什么样的活。
通俗地理解,你让AI查资料,钱主要花在搜索上;让它动脑子,钱主要花在模型上;让它一直在后台干活,“开机时长”本身就是一笔账。所以,根本不存在一张能通用的“AI单位成本”表。AI经济的演变,不能被简化成“工具吃掉模型”或“模型吞噬一切”这种非黑即白的故事。
更准确的说法是:
买方必须开始按不同任务形态去理解总成本,不再假定存在一个统一的成本锚点。
这件事的后果,比“算术变复杂”要大得多。一旦计费单位裂变,原本用“每百万Token多少钱”就能对账的人,现在必须同时理解搜索成本、缓存命中率、运行时长度与区域溢价。
预算口径从一维变成多维,采购的比较轴也随之改写——从“谁的Token更便宜”,变成“在我的工作负载下,谁的综合成本更低”。计费单位的裂变,正在倒逼企业重写自己理解AI支出的方式。
中国市场提供了一个“反向参照”。例如,2024年国内大模型价格战打得异常惨烈,部分厂商降价超过97%,推理毛利一度跌至负数,但整场战争的叙事始终只围绕一件事:谁的百万Token更便宜。
运行时、搜索增强、按结果付费这些在美国价格页上已经独立成行的维度,目前在中国仍处于早期。当所有玩家都挤在同一个计量单位上竞争,负毛利就不是意外,而是结构性的终点。
价格页先变,企业的预算体系也需跟上
价格页先变,企业的预算体系也需跟上
计费单位的变化,最先出现在价格页上,最后才会反映到平台的营收盘子里。而夹在中间、最先被迫跟着调整的,是企业自己的预算表。
到目前为止,没有可靠的公开数据能证明OpenAI、Google或Anthropic的工具、存储、运行时营收已经超过模型或Token营收。
所以,一家公司在价格页上加了多少新收费项,不代表他们的钱真的就是从那些新项目里挣回来的,这两件事不能画等号,还需要进一步等数据说话。
当前真正能确认的是:卖方的定价语言已经先变了,买方的预算口径没办法继续停在Token这一列上。
这其中的道理也不言而喻:当官方价格页已经把工具调用、会话运行时长、结果各自独立定价,企业的对账单就不可能再维持成一列Token,否则卖方给的账单和买方的内部核算对不上。
Token不再是唯一的主角,它更像是底层的一种计量单位。真正影响账单的,是推理、搜索、缓存、运行时、席位、动作、结果这些叠在一起的成本。
文章开头Sarah Friar那句顺口提到的“未来还会扩展到授权、IP协议、按结果定价”,其实就是这件事在OpenAI自己眼里的翻译——他们比任何人都更清楚,自己正在卖的不只是Token。
一旦买方的预算框架跟着调整,一些原本被忽视的东西会重新浮出水面。比如:
模型路由不再只是“帮你挑哪个模型最合适”,而是在悄悄决定整张账单的结构——选错一层,预算的重心就会整体偏移;
Salesforce的Flex Credits卖的不是某一次具体调用,而是一份可以在不同动作、场景、团队之间自由调拨的“使用权”;
按结果定价的真正吸引力,在于它把预算直接绑在“完成件”上。企业第一次可以用结果,而不是过程,来和供应商对账。
新的计费单位或许还没改写卖方的收入结构,但它们已经在改写企业内部看待AI的方式。而一旦组织用新的语言理解自己的AI支出,预算最终流向哪一层、沉淀在哪一层,就不再是一张模型排行榜能决定的事了。
当计费单位裂变,价值开始分层
当计费单位裂变,价值开始分层
把视野再拉远一点,如果计费单位已经不只是Token,那“钱到底会沉淀在哪一层”这件事,就得分层去看。
一个有效的梳理方式,是把整个AI经济看成一套五层结算栈。当成一张正在成型的产业结构图来看,本系列接下来几篇会沿着这个框架逐层展开:
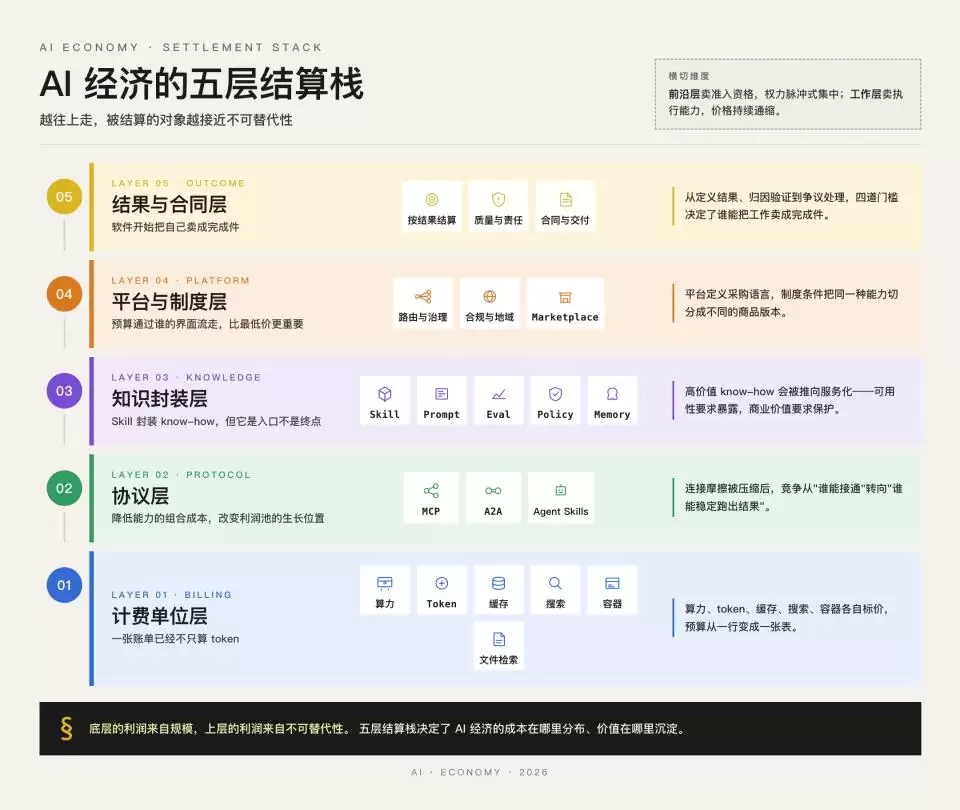
• 第一层 · 公用事业层:算力、Token、缓存、搜索、容器、文件检索,可计量、可路由的“认知吞吐量”
• 第二层 · 协议与能力层:MCP、A2A、Agent Skills 这类让模型、工具、数据源和智能体互操作的共同接口
• 第三层 · 知识封装层:技能、提示词、评估、策略、记忆,把行业知识序列化下来
• 第四层 · 执行交付层:被托管、观测、监控的“数字劳动力”,市场正把智能体从“下载”变成“调用”
• 第五层 · 结果与责任层:Intercom的“每次有效解决0.99美元”是最明确的公开信号之一,“被完成的工作”开始成为合同化的结算对象
如果把这五层放在一起看,会出现一个很清晰的分布规律:越靠下,越容易被单位化和路由化;越靠上,越深地嵌入上下文、验收和责任。
对应的商业模式也随之分化——底层依赖规模和效率,买方按成本比价;上层依赖不可替代性,买方按结果付费。这两种模式都可以成立,但它们的“价格锚”完全不同。前者锚定投入成本,后者锚定创造的价值。
Token经济,不再只关于Token
Token经济,不再只关于Token
总之,今天再谈Token经济学,不再是简单的“Token单价走势”,更值得研究的是:
Token作为底层计量颗粒,正在怎样与搜索、缓存、运行时、席位、结果这些更高层的单位一起
当然,这并不意味着Token不重要。
底层资源层依然可能是最大的利润池,甚至会出现高度集中的赢家。但到了2026年,如果想理解AI商业化的变化,只盯着Token,已经看不全了。问题从“Token多便宜”,变成了:整张账单是怎么被构成的。
那接下来应该看什么?比预测时间表更有意义的,是观察一些正在出现的信号:
第一,企业合同里,是否开始出现服务等级协议、数据驻留、缓存策略、责任边界这些条款,而不再只谈Token单价。这意味着,买卖双方开始围绕“系统”和“责任”对齐,而不是单一资源。
第二,市场上,是否开始出现带评估卡的智能体服务。也就是,“结果是否可被评估”,开始成为商品定义的一部分。
第三,是否出现第三方的审计、认证和争议处理服务。这是“按结果结算”走向合同化之前,必须补上的最后一块基础设施。
到2027年底,如果这三条里有两条以上落地,那么可以基本确认一件事:结算对象正在从Token向更高层上移。
Anthropic在4月7日以“邀请制”的方式发布了Mythos(预览版),而与此同时,工作层模型的价格仍在持续下降。
一边是前沿能力不断集中,一边是工作层持续商品化。
成本在下沉,价值在上移。
这两条看似相反的变化,其实指向同一个方向:AI的价格正在走向分层,而价值也在随之重新分配。
当Token不再是唯一的计量单位,当账单被拆分成多种成本结构,企业最终为哪一层买单,就会决定价值沉淀在哪一层。
至于这种“成本下沉、价值上移”的结构,是如何在同一个体系中同时成立的,我们将在后续的解读中再逐一展开。




