
刚刚,Anthropic发布Sonnet 5,性能接近Opus 4.8,但不一定更便宜
Anthropic 刚刚放出了新模型
Claude Sonnet 5
话说从基准数据看,Sonnet 5 在推理、工具使用、编程和知识工作这些核心维度上,相比上一代 Sonnet 4.6 提升相当明显,已经接近 Opus 4.8 的水平,但价格却低了一截。也就是说,你花更少的钱,能拿到几乎跟旗舰级 Opus 一样强的 Agent 能力。
Anthropic 还特意回顾了一下:Agent 时代其实是从 Sonnet 级模型开始的——Claude Sonnet 3.5、3.6 和 3.7 最早在编程和工具使用上做出了亮眼表现。只是最近一段时间,最强的 Agent 能力主要出现在 Opus 级模型上。而这次 Sonnet 5 明显把差距拉近了。具体对比如下:
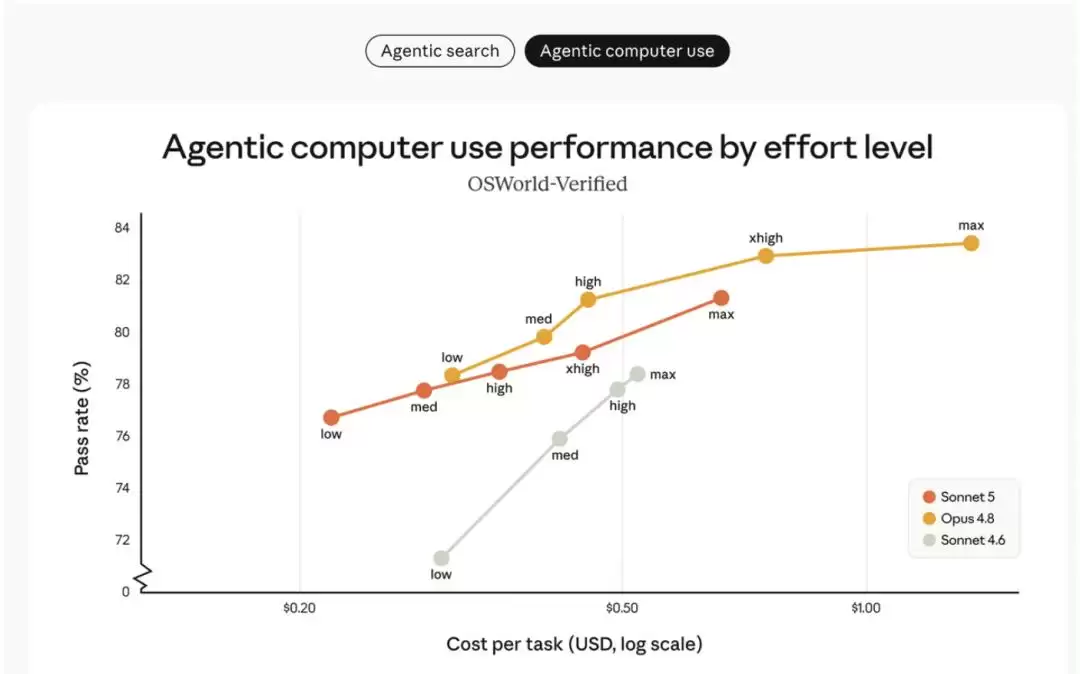
再看智能体搜索评测 BrowseComp 和 computer use 评测 OSWorld‑Verified 的表现,不同「努力程度」下 Sonnet 5 的曲线很有意思:
- 橙色线(Sonnet 5)相比灰色线(Sonnet 4.6)有明确提升,而且覆盖的成本‑性能选项范围比黄色线(Opus 4.8)更广。
- 在中等努力程度下,Sonnet 5 的成本效率显著优化;往高努力程度走,某些任务甚至能媲美 Opus 4.8。
- 用户可以根据具体任务灵活调整努力程度,在 Sonnet 5 和 Opus 4.8 之间找到最适合自己的平衡点。
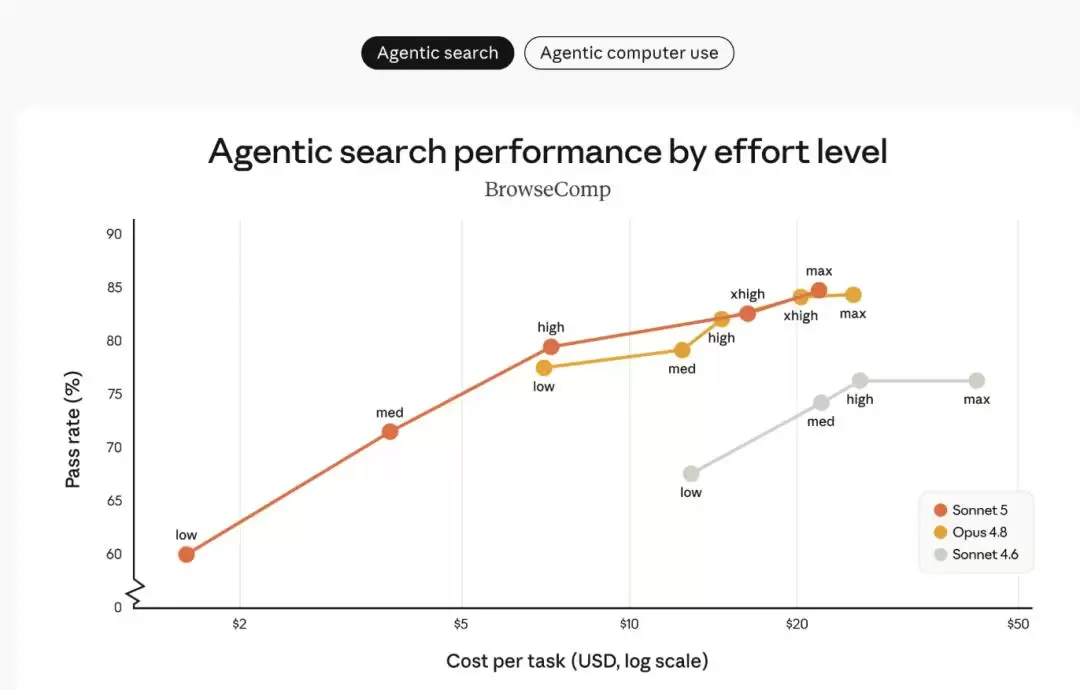
这里多说一句定价:Sonnet 5 标准价格是输入 $3/百万 token、输出 $15/百万 token。但直到 8 月 31 日有尝鲜价——输入 $2、输出 $10,这样一来实际成本比图上显示的更低。而 Opus 4.8 的定价是输入 $5、输出 $25,差距一目了然。
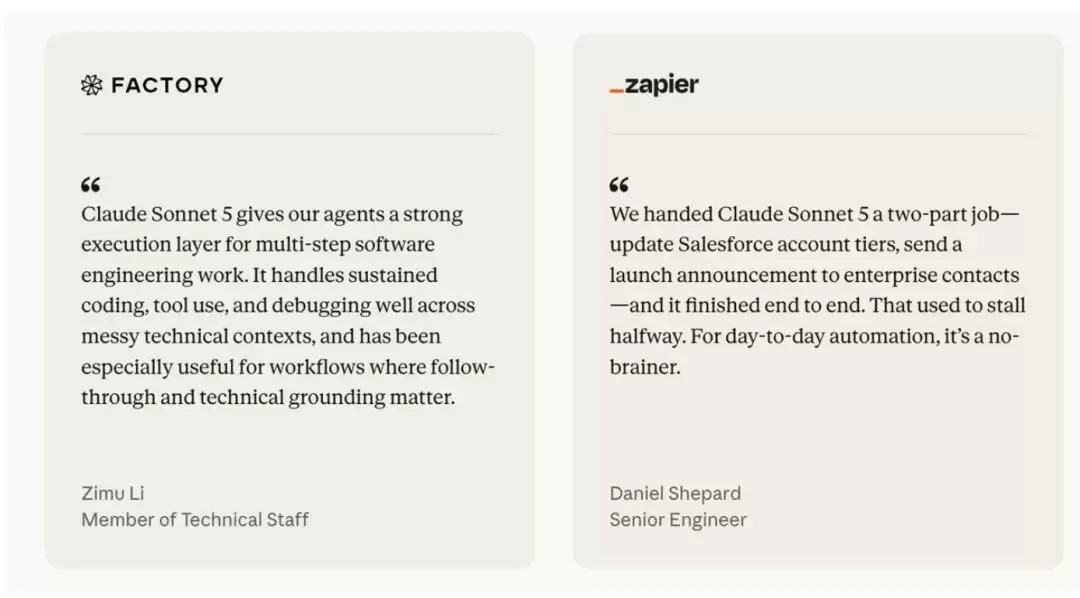
来自早期访问合作伙伴的反馈也很一致:Sonnet 5 比前代模型更具自主智能体能力。测试者说它能完成那些之前 Sonnet 模型做到一半就卡住的复杂任务,会主动检查自己的输出,而且价格非常有吸引力。
安全评估
安全评估
部署前安全评估显示,Sonnet 5 整体安全性比 Sonnet 4.6 有所改善——在拒绝恶意请求、抵御提示注入攻击方面表现更好,幻觉率和谄媚行为率也降低了。自动化行为审计中,Sonnet 5 的失当行为率整体更低。
不过必须指出的是,相比能力更强的 Opus 4.8 和 Claude Mythos Preview,它在某些维度上失当行为率仍然略高。
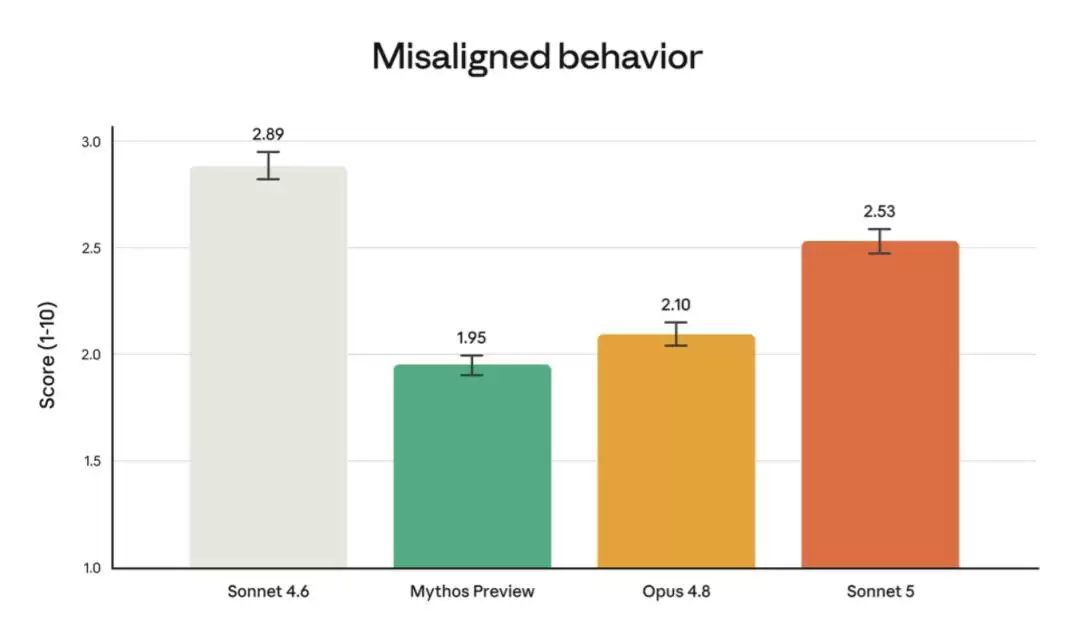
Anthropic 还特意强调:他们并没有针对网络安全任务训练 Sonnet 5。模型能执行一些常规的无害网络任务,但在评估危险网络技能(比如开发软件漏洞利用程序)时,表现显著弱于 Opus 4.8 和 Mythos 5。下图展示了针对 Firefox 漏洞的评估结果:
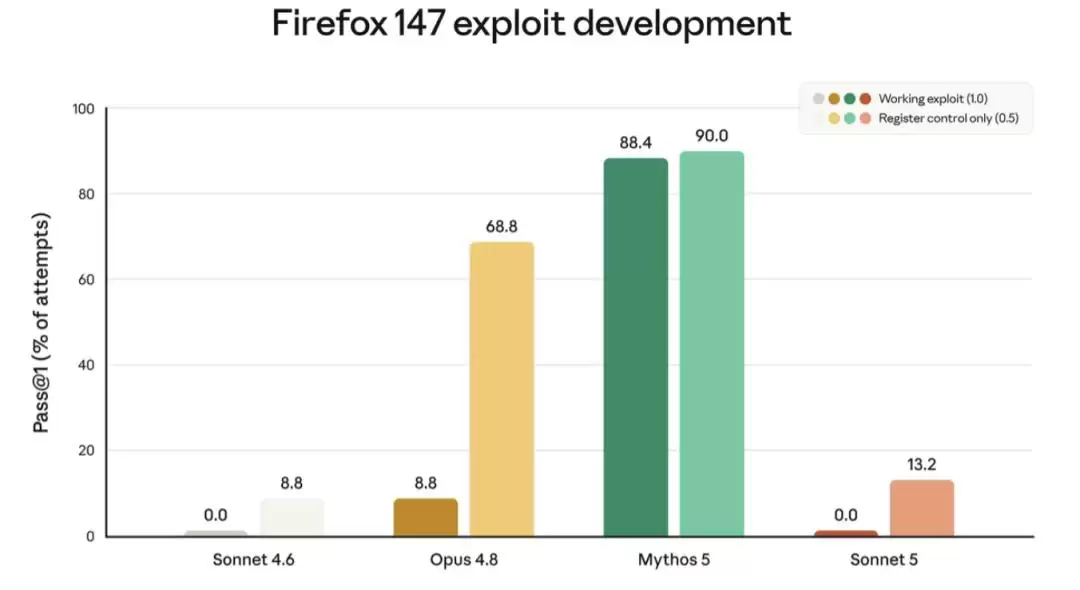
两款 Sonnet 模型都未能成功开发出可利用程序(得分 0.0%),Sonnet 5 的部分成功率略高于 Sonnet 4.6。因此 Anthropic 默认开启了与 Opus 4.7/4.8 相同的网络安全护栏,但严格程度低于 Fable 5 那种更激进的拦截方案。
完整评估报告可参考《Claude Sonnet 5 系统卡》。
定价
定价
今天起,Claude Sonnet 5 已在所有渠道可用。限时优惠首发价到 2026 年 8 月 31 日截止:输入 $2/百万 token,输出 $10/百万 token。之后恢复标准价:输入 $3、输出 $15。
同时,Chat、Cowork、Claude Code 及 Claude 平台的速率限制也全面上调,以适配更高「努力程度」模式带来的更大 token 消耗。
注意事项
注意事项
网络安全验证
网络安全验证
Sonnet 5 已纳入 Anthropic 的「网络安全验证计划」。该计划现已在 Claude 原生平台、AWS 上的 Claude 平台、Microsoft Foundry 中的 Claude 开放使用。Google Vertex 上的 Claude 也将很快支持。已加入该计划的组织自动获得访问权限,无需重新申请。
tokenizer 更新与定价说明
tokenizer 更新与定价说明
Sonnet 5 采用了全新 tokenizer,与 Opus 4.7 类似的优化。带来的直接变化是:相同输入内容现在会映射为更多 token,增幅约 1.0~1.35 倍。所以 Anthropic 特意给出了尝鲜价,让用户过渡时整体使用成本大致保持不变。
速率限制调整说明
速率限制调整说明
早在 2026 年 4 月 26 日,Anthropic 已针对 Sonnet 和 Haiku 模型上调了速率限制,并将原生 Claude 平台套餐简化为三个层级:Start、Build、Scale。这次更新进一步上调了 Chat、Cowork 等服务的限制,以配合更高努力程度模式的 token 消耗。具体可在 Claude Console 查看。
评测分数更正说明
评测分数更正说明
- 更新评分模型后,Sonnet 4.6 分数修正为 34.6%(无工具)和 46.8%(有工具)。
Humanity’s Last Exam:
- 优化运行方式后,Sonnet 4.6 分数修正为 78.5%。
OSWorld‑Verified:
开发者上手反馈
开发者上手反馈
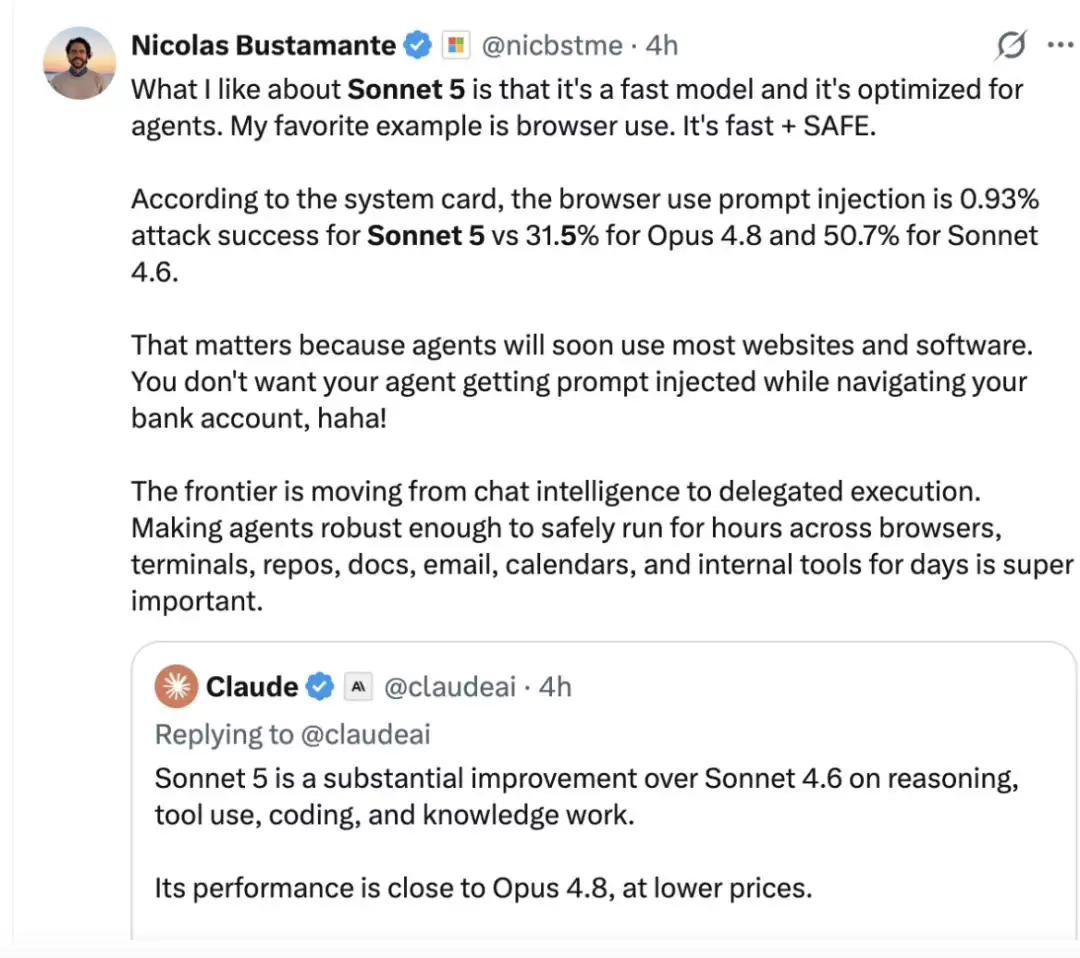
Claude Sonnet 5 一发布,社区立刻开始上手体验。网友 Nicolas Bustamante 很喜欢它的速度和 Agent 优化,尤其提到浏览器使用:又快又安全。系统卡数据显示,浏览器使用场景下的提示注入攻击成功率,Sonnet 5 只有 0.93%,而 Opus 4.8 是 31.5%,Sonnet 4.6 是 50.7%。
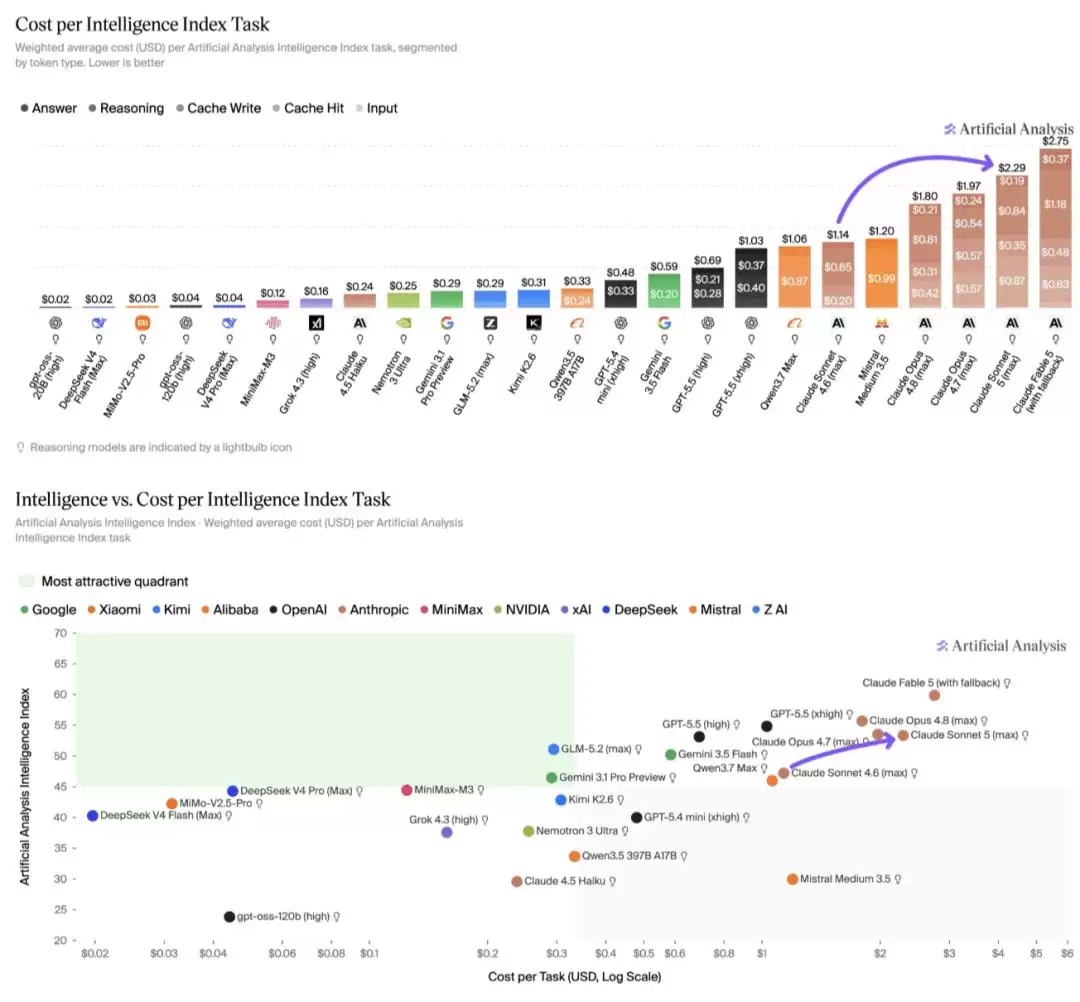
当然也有吐槽——「太贵了。」根据 Artificial Analysis 的分析,Claude Sonnet 5 在 Intelligence Index 上的运行成本为每项任务 2.29 美元,相比 Sonnet 4.6 增加约 2 倍,甚至比 Claude Opus 4.8 还高出约 15%。这一成本上升主要来自 token 使用量的增加,使其成为运行成本最高的模型之一,仅次于 Claude Fable 5。
那么,新模型到底值不值得入手?从性能提升和定价策略来看,Sonnet 5 明显瞄准了那些想要旗舰级 Agent 能力又不想花大价钱的开发者。不过 token 消耗的增加也不容忽视。具体怎么选,还得看实际场景和预算。各位怎么看?




