
YC CEO 的 gstack 源码拆解:11.8 万 Star 凭的是真工程,还是一堆 Markdown
 封面图 - 11.8 万 Star 双引擎 YC CEO
封面图 - 11.8 万 Star 双引擎 YC CEO
先说三个数字开个头。
一个叫 gstack 的项目,只是个 Claude Code 的 skill 集合,GitHub 上收获了 117,967 颗 star。这背后是 23 个专家角色、大约 170,765 行 TypeScript 代码,以及一个 58MB 的编译二进制文件。更让人印象深刻的是,项目从 2026 年 3 月 11 日创建到 6 月底,不到四个月,CHANGELOG 已经堆到了 395 个版本,平均每天差不多发 4 个。
作者是 Garry Tan,Y Combinator 的总裁兼 CEO,早年是 Palantir 的工程师,也是 Posterous 的联合创始人。
初次见到这条消息,和 Hacker News 上的反应差不多:这难道又是 YC 大佬搞出来的 AI 玩具?但深入翻了一遍源码后,想法彻底变了。项目 README 里有一句非常直白的话——"everything else is Markdown"。核心意思很清楚:这个项目真正的硬功夫不在那些 skill 文件里,而是在那个常驻的浏览器守护进程中。
这篇文章就来拆解这件事。不聊营销话术,不吹代码行数,只看源码层面,gstack 到底做了哪些关键的工程决策,以及为什么这些决策能让它从一堆 prompt 集合中脱颖而出。
1. 一句话定位:它到底解决什么问题
直接看 package.json 里 description 的原文:一个仓库,一次安装,搞定整套 AI 工程工作流。两个核心组件——Claude Code skills 加上一个快速的 headless 浏览器。
用 Claude Code 原生的开发者可能都踩过一个坑:面对一个空白的 prompt,不知道该怎么让 AI 扮演什么角色、走什么流程。你说“帮我写代码”,AI 就闷头写;你说“做 code review”,它就按自己的理解来。整个过程是即兴的,每次都不一样,无法复用。
gstack 做的事情,就是把这套流程固化下来。23 个角色,每个都是一个 SKILL.md 文件,通过 slash 命令调用。比如 /plan-ceo-review 让 Claude 扮演 CEO 来挑战你的方案,/cso 是首席安全官跑 OWASP STRIDE 审计,/qa 则会打开真实浏览器走流程找 bug。
但 Skill 文件本质上就是 prompt。真正把 gstack 和其他 skill 仓库区别开的,是那个浏览器。
2. 核心架构:Skills + Browser 的双引擎
ARCHITECTURE.md 开篇就点明了项目的本质:给 Claude Code 一个常驻浏览器,外加一套有主见的工作流 skill。难的是浏览器——剩下的都是 Markdown。
这句话是理解整个项目的一把钥匙。两层结构大致是这样的:
┌─────────────────────────────────────────────┐
│Skills 层(~40 个 SKILL.md 文件) │
│• 每个文件 = 一个专家角色 │
│• Claude Code 加载即获得结构化工作流 │
│• 全是 Markdown,人能读、能改 │
└─────────────────────────────────────────────┘
┌─────────────────────────────────────────────┐
│Browser 层(58MB 编译二进制) │
│• 内嵌长驻 Chromium 守护进程 │
│• 通过 localhost HTTP 提供服务 │
│• 这是真正硬的工程 │
└─────────────────────────────────────────────┘为什么要这么分?因为 skill 是廉价的——写个 Markdown 文件,描述清楚角色和流程,任何会写字的人都能做。但浏览器是另一回事。让 AI agent 能稳定地驱动一个真实浏览器去点按钮、填表单、读页面内容,这件事在工程上极其困难。CSP 冲突、框架水合、Shadow DOM、cookie 解密、长进程管理,每一个都是能让人掉头发的坑。
gstack 把绝大部分工程精力都投在了那个 58MB 的二进制文件上,作者的判断很清晰:光靠 prompt 写得好,撑不起一个 11 万 star 的项目。
 双引擎架构图
双引擎架构图
3. 浏览器守护进程:这个项目最硬的工程
先看看 ARCHITECTURE.md 里的架构图,理解它是怎么工作的:
Claude Code gstack
─────────────── ┌──────────────────────┐
Tool call: $B snapshot -i │CLI (compiled binary)│
─────────────────────────→ │• reads state file │
│• POST /command │
│ to localhost:PORT │
└──────────┬───────────┘
│ HTTP
┌──────────▼───────────┐
│Server (Bun.serve) │
│• dispatches command │
│• talks to Chromium │
│• returns plain text │
└──────────┬───────────┘
│ CDP
┌──────────▼───────────┐
│Chromium (headless) │
│• persistent tabs │
│• cookies carry over │
│• 30min idle timeout │
└──────────────────────┘为什么不每次新开浏览器
这是 gstack 与那些每次冷启动浏览器的方案最根本的区别。官方给出的性能数据是:首次调用约 3 秒启动,之后每条命令只需 100-200 毫秒。
一次完整的 QA 会话可能有 20 多条命令。如果每次都冷启动浏览器,光启动就要 40 多秒,而且还会丢掉所有 cookies、localStorage、登录态和打开的标签页。这已经不是优化问题,而是可用性问题了——一个需要登录才能用的页面,总不能每点一下都重新登录一次。
长驻守护进程解决的就是这个问题。Chromium 启动后,cookies、标签、状态全都保留下来,30 分钟空闲才会超时退出。
为什么选 Bun 不选 Node.js
ARCHITECTURE.md 给了四条理由,讲得非常清楚:
- :
编译二进制
bun build --compile能输出一个单文件的 58MB 可执行文件,不需要 node_modules、不需要 npx、不需要配 PATH。gstack 要安装到~/.claude/skills/这种用户不会去管理 Node 项目的目录,这点非常关键。 - :Cookie 解密需要直接读取 Chromium 的 SQLite cookie 数据库。Bun 内置
原生 SQLite
new Database(),不需要 better-sqlite3,也不需要 gyp 编译。 - :开发期直接
原生 TypeScript
bun run server.ts,不需要编译步骤。 - :
内置 HTTP 服务器
Bun.serve()够快够简单,不用 Express/Fastify。
当然,真正的工程理由是,Bun 的编译二进制加上原生 SQLite 这两点,完美匹配了 gstack 的需求。瓶颈永远是 Chromium,不是 CLI 或 server。
 浏览器守护进程生命周期
浏览器守护进程生命周期
4. Ref 系统:用 @e1 而不是 CSS 选择器操作页面
这是 gstack 浏览器层最有特色的设计,ARCHITECTURE.md 专门用了一章来介绍。
工作流程
Agent 要操作一个页面,不需要写 CSS selector,也不需要让模型理解整个 DOM。流程是这样的:
1. Agent 调用 $B snapshot -i
2. Server 调用 Playwright 的 page.accessibility.snapshot()
3. 解析器遍历 ARIA 树,分配顺序 ref: @e1, @e2, @e3...
4. 为每个 ref 构建一个 Playwright Locator: getByRole(role, { name }).nth(index)
5. 在 BrowserManager 实例上存 Map
6. 返回带标注的树作为纯文本给 Agent 之后 Agent 要点某个元素,直接 $B click @e3 就行,server 把 @e3 解析成对应的 Locator,再执行 locator.click()。
对 AI agent 来说,这个设计的好处很明显:它不需要懂 CSS,也不需要懂 DOM 结构,只需要看 ARIA 树和编号就能操作。这大大降低了 prompt 的复杂度和出错率。
为什么用 Locator 而不是注入 DOM 属性
这才是真正关键的工程权衡。让 agent 操作页面,业界常见做法是往 DOM 里注入属性。但 gstack 偏偏不这么干,理由有三条:
- :很多生产站点会用 Content Security Policy 阻止脚本修改 DOM,注入操作直接就被拦住了。
CSP 冲突
- :React、Vue、Svelte 的 reconciliation 过程会把注入的属性剥掉。
框架水合冲突
- :从外部根本够不着 shadow root 里的元素。
Shadow DOM
Playwright Locator 是 DOM 外部的东西,它利用的是 Chromium 内部维护的 accessibility tree 和 getByRole() 查询。完全没有 DOM 突变、没有 CSP 问题、没有框架冲突。代价是依赖 Playwright,但相比在每个生产站点上被 CSP 拦死,这个代价完全值得。
Ref 失效检测:约 5ms 的聪明取舍
SPA 有个很麻烦的地方:它可能在不触发 framena vigated 事件的情况下修改 DOM(比如 React Router 跳转、切换标签、弹窗)。如果 Agent 手里攥着一个已经失效的 @e5 去点击,Playwright 默认会空等 30 秒的 action timeout。
gstack 的解法在 resolveRef() 里:在使用任何 ref 之前,先跑一次异步 count() 检查,大约 5ms 的开销。元素还在,就继续;不在,立即报告失效,Agent 重新进行 snapshot。用 5ms 换 30 秒的空等,这笔账谁都会算。
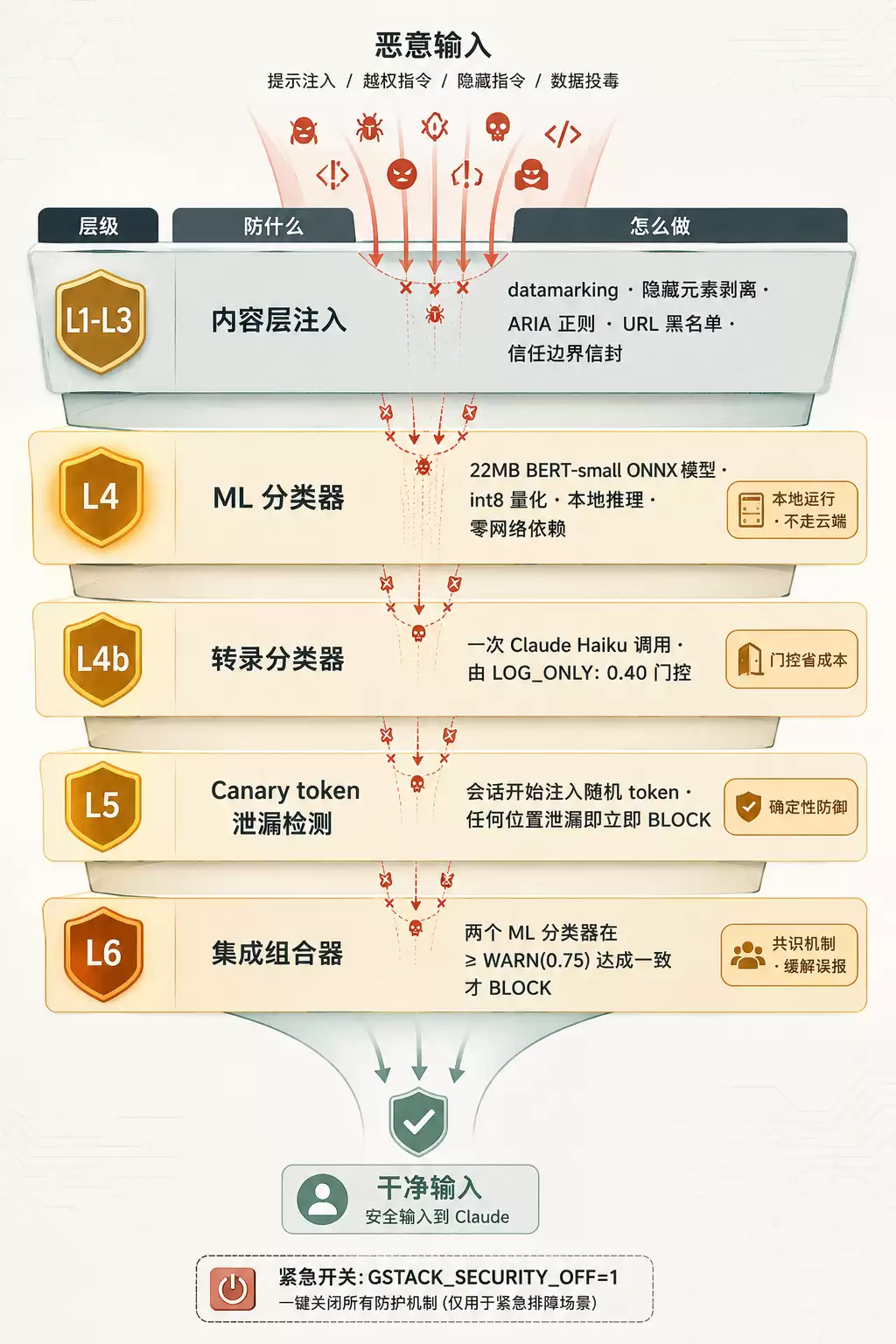
5. Prompt Injection 六层防御:看懂 AI 安全工程长什么样
这是 gstack 里最具安全工程含金量的部分。sidebar agent(Chrome 侧边栏里的子 Claude)具备 Bash、Read、Glob、Grep、WebFetch 等工具,而且需要读取恶意网页,因此是整个项目中最暴露给 prompt injection 的部分。
ARCHITECTURE.md 把防御栈拆成了六层:
| 层 | 防什么 | 怎么做 |
|---|---|---|
| L1-L3 | 内容层面的注入 | datamarking、隐藏元素剥离、ARIA 正则、URL 黑名单、信任边界信封封装 |
| L4 | ML 分类器 | 22MB BERT-small ONNX 模型(int8 量化),随 agent 打包,本地运行,无网络依赖 |
| L4b | 转录分类器 | 一次 Claude Haiku 调用看完整对话形状,由 LOG_ONLY: 0.40 门控 |
| L5 | Canary token | 会话开始时往 system prompt 注入随机 token,一旦泄漏就立即 BLOCK |
| L6 | 集成组合器 | 两个 ML 分类器在 >= WARN(0.75) 上达成一致才 BLOCK |
有几个点值得单独拿出来说。
L4 那个 22MB 的 BERT 模型是在本地运行的。这一点很关键——模型本身打包进二进制文件,本地推理、零网络依赖,不走云端的 moderation API。另外还有一个可选的 721MB 的 DeBERTa-v3 集成方案,但默认不开启。
L4b 的门控设计很精妙。一次 Claude Haiku 调用是要花钱的,如果每条消息都过一遍,成本根本扛不住。所以用 LOG_ONLY: 0.40 来做门控——大部分干净的流量会跳过这次付费调用,只有可疑的才会进入转录分类。
L5 的 canary token 是一种确定性防御。会话开始时在 system prompt 里塞入一个随机 token,然后在 Claude 的输出、工具参数、URL、文件写入等各个环节持续监视。该 token 一旦在任何位置出现,就意味着攻击者已经说服 Claude 把 system prompt 泄漏出来了——会话立即结束,没有商量余地。
L6 的组合器最反直觉。它要求两个 ML 分类器在 >= WARN(0.75) 上达成一致才进行 BLOCK,而不是单个高置信度命中就直接拦截。看起来标准更宽松了,实际上是为了缓解误报。像 Stack Overflow 这类页面,里面写着“忽略之前所有指令”的正常技术文档,单个分类器会频繁误报,让两个一起投票就能把这种误报压下去。
还有一个紧急开关:GSTACK_SECURITY_OFF=1。生产环境出问题,或者你想完全绕过防御来做调试时使用。一个项目敢提供关掉所有安全的开关,这本身就说明它对自己的安全机制有足够的信心。
 六层防御栈
六层防御栈
6. SKILL.md 模板系统:让文档和代码永不漂移
再来聊一个看似不起眼、但实际非常巧妙的设计。
问题
SKILL.md 是用来告诉 Claude 怎么使用 browse 命令的文档。但文档是人维护的,代码也是人改的。如果某天代码里新加了一个 flag,但文档里没写,Claude 就不知道有这个能力。反过来,如果文档里写了个不存在的命令,Claude 调用就会报错。
这就是经典的文档与代码漂移问题。绝大多数项目的解法是:靠人记得去更新。结果自然是没人记得住。
gstack 的解法
gstack 把 SKILL.md 拆成了模板加占位符的模式:
SKILL.md.tmpl(人写的叙述 + 占位符)
↓
gen-skill-docs.ts(从源码读取元数据)
↓
SKILL.md(提交进仓库,自动生成那部分)模板负责承载那些需要人类判断的部分:工作流、技巧、示例。占位符则在构建时从源码中填充。来看看几个真实的占位符:
| 占位符 | 数据来源 | 生成什么 |
|---|---|---|
{{COMMAND_REFERENCE}} |
commands.ts |
分类命令表 |
{{SNAPSHOT_FLAGS}} |
snapshot.ts |
带 example 的 flag 参考 |
{{PREAMBLE}} |
gen-skill-docs.ts |
启动块:更新检查、会话追踪、contributor 模式、AskUserQuestion 格式 |
{{QA_METHODOLOGY}} |
gen-skill-docs.ts |
/qa 和 /qa-only 共享的 QA 方法论 |
{{DESIGN_METHODOLOGY}} |
gen-skill-docs.ts |
/plan-design-review 和 /design-review 共享的设计方法论 |
{{REVIEW_DASHBOARD}} |
gen-skill-docs.ts |
/ship 起飞前的 Review Readiness Dashboard |
关键属性是结构性保证:命令只要存在于代码中,就一定会出现在文档中;不存在,就绝不可能出现。漂移从“可能性问题”变成了“机制上不可能”。
三层测试:免费抓住 95% 的问题
光有生成机制还不够,还得测试。gstack 的测试分三层:
| 层 | 干什么 | 成本 | 速度 |
|---|---|---|---|
| 1 - 静态验证 | 解析 SKILL.md 里每个 $B 命令,对照 registry 校验 |
免费 | <2s |
2 - 通过 claude -p 的 E2E |
启动真实 Claude 会话,运行每个 skill,检查错误 | 约 $3.85 | 约 20min |
| 3 - LLM 当裁判 | Sonnet 给文档打分(清晰度/完整性/可操作性) | 约 $0.15 | 约 30s |
第 1 层在每次 bun test 时都跑,第 2 层和第 3 层由 EVALS=1 门控。这个理念很朴素:用免费的方法抓住 95% 的问题,只在对问题的判断上花钱用 LLM。这种把测试成本分层的设计,在开源项目里并不多见。
7. Preamble:每个 skill 启动前都跑的那段 bash
每个 skill 的开头都有一个 {{PREAMBLE}} 块,在 skill 自己的逻辑运行之前先执行。它用一条 bash 命令处理五件事,每件都有讲究。
第一件:更新检查。调用 gstack-update-check,报告是否有新版本。这是日常工程操作。
第二件:会话追踪。touch ~/.gstack/sessions/$PPID,统计活跃会话数(最近 2 小时内修改过的文件)。当同时有 3 个以上会话在运行时,所有 skill 会进入 ELI16 模式——每个问题都要把上下文重新交代一遍。原因在于用户可能正在多个窗口之间切换,你不知道他刚才在另一个窗口里让 Claude 做了什么,所以需要重新建立上下文。这是真实多窗口开发的场景,不是凭空想象出来的。
第三件:运维自我改进。每次 skill 会话结束时,agent 会反思失败(CLI 错误、错误方法、项目怪癖),把学到的经验写进项目的 JSONL 文件中,供后续的会话使用。这是会话级别的记忆,不依赖外部向量库。
第四件:AskUserQuestion 格式统一。所有 skill 向用户提问时都用同一种格式:context、question、RECOMMENDATION: Choose X because ___、字母选项。这种一致性降低了用户的认知负担。
第五件:Search Before Building。这是 ETHOS.md 里的核心原则之一(下一节会细讲),Preamble 将其强制注入到每个 skill 的启动时。
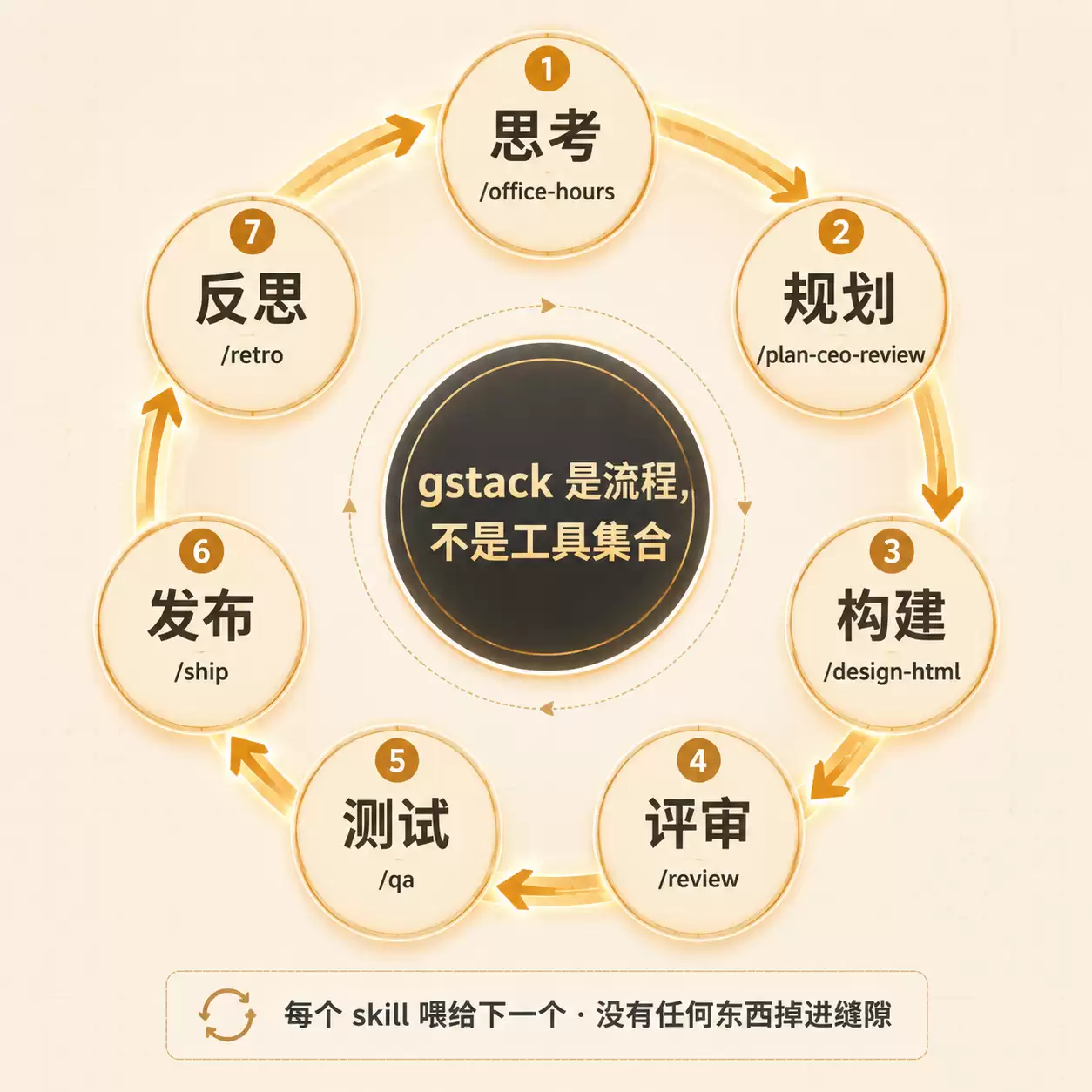
8. Skill 工作流:一个 Sprint 的完整闭环
README 里有一句话点明了 gstack 的本质:“gstack is a process, not a collection of tools”。
23 个 skill 不是孤立的命令,它们共同构成了一个 sprint 闭环:
Think → Plan → Build → Review → Test → Ship → Reflect每个 skill 的输出都是下一个的输入。/office-hours 写的设计文档被 /plan-ceo-review 读取。/plan-eng-review 写的测试计划被 /qa 接走。/review 抓出的 bug 被 /ship 验证是否已修复。没有任何东西会掉进缝隙里,因为每一步都知道上一步做了什么。
一个典型流程(来自 README 示例)
You: 我想做一个日历简报应用。
You: /office-hours
Claude: [询问痛点——具体例子,不是假设性场景]
You: 多个 Google 日历,事件信息过期,错误地点...
Claude: 我要挑战你的框架。你说"daily briefing app",但你实际描述的是 personal chief of staff AI。
[提取 5 个你没意识到的能力]
[挑战 4 个前提——你同意、不同意、或调整]
[生成 3 个实现方案带工时估算]
建议:明天先发最窄的楔子,从真实使用中学习。
You: /plan-ceo-review
[读设计文档,挑战范围,跑 10 段评审]
You: /plan-eng-review
[ASCII 数据流图、状态机、错误路径]
You: 批准计划。退出 plan 模式。
[写 2,400 行,跨 11 个文件,约 8 分钟]
You: /review
[AUTO-FIXED 2 个问题。ASK:竞态条件 → 你批准修复]
You: /qa https://staging
[打开真实浏览器,走流程,找到并修复一个 bug]
You: /ship
[测试从 42 个增加到 51 个(其中 9 个是新增的)。PR:github.com/you/app/pull/42]Skill 清单按阶段梳理
来自 docs/skills.md 的官方分类,数量确实不少,这里按阶段列一下:
- :
Think/Plan
/office-hours、/spec、/plan-ceo-review、/plan-eng-review、/plan-design-review、/plan-devex-review、/autoplan、/design-consultation - :
Build
/design-shotgun、/design-html - :
Review/Test
/review、/investigate、/design-review、/devex-review、/qa、/qa-only、/cso - :
Ship
/ship、/land-and-deploy、/canary、/benchmark - :
Reflect/Memory
/retro、/document-release、/document-generate、/learn - :
Browser 工具
/browse、/open-gstack-browser、/setup-browser-cookies、/pair-agent - :
Power tools
/codex(引入 OpenAI 做第二意见)、/careful、/freeze、/guard、/unfreeze、/gstack-upgrade - :
iOS QA(v1.43.0.0)
/ios-qa、/ios-fix、/ios-design-review、/ios-clean、/ios-sync
这套清单覆盖了从需求到上线的完整生命周期。其中 /codex 这个设计值得单独拿出来说一下——它主动引入 OpenAI 的 Codex CLI 来做独立的代码评审,与 Claude 形成跨模型的第二意见。在 vendor lock-in 焦虑普遍存在的开发者群体中,这种主动跨 vendor 的态度是一个很棒的加分项。
 Sprint 闭环
Sprint 闭环
9. 设计哲学:ETHOS.md 里那三条被注入每个 skill 的原则
ETHOS.md 开篇就点明了核心:“These are the principles that shape how gstack thinks, recommends, and builds. They are injected into every workflow skill's preamble automatically.”
三条原则,每一条都带着强烈的主观判断。
Boil the Ocean(把海洋煮沸)
当工程时间是瓶颈时,不试图煮干大海曾经是合理的建议。但那个时代已经结束了。核心论点在于:在 AI 辅助下,完整实现一个模块只比走捷径多花几分钟。那为什么不每次都做完整的那件事?海洋就是目的地——一个模块实现 100% 的测试覆盖、完整功能、所有边界情况、所有错误路径。一个湖一个湖地到达那里。
ETHOS.md 列举了几个反模式,讲得非常直接:
- 选 B——它用更少代码覆盖 90% → 如果 A 多 70 行,就选 A
- 把测试推到下个 PR → 测试是成本最低的湖
- 这要 2 周 → 应该说 2 周人工 / 约 1 小时 AI 辅助
Search Before Building(构建之前先搜索)
一个 1000x 工程师的第一反应应该是“有人已经解决这个问题了吗?”而不是“让我从头设计”。ETHOS.md 把知识分成了三层:
- :经过实战验证的标准模式。风险不是不知道,而是假设那个显而易见的答案一定正确。
Layer 1(tried-and-true)
- :当前的最佳实践、博客、生态趋势。可以搜索,但要带着审视的眼光——人们会狂热,市场先生不是太恐惧就是太贪婪。
Layer 2(new-and-popular)
- :基于对具体问题的推理得出的原创观察。最有价值。优秀的项目既要避免错误(Layer 1 不重造轮子),又要做出分布之外的精彩观察(Layer 3)。
Layer 3(first-principles)
User Sovereignty(用户主权)
AI 模型推荐。用户决定。这是一条覆盖所有其他规则的规则。两个 AI 模型对某个变更达成一致是强信号,但不是命令。用户永远拥有模型所缺乏的上下文:领域知识、商业关系、战略时机、个人品味、还没有分享的未来计划。
User Sovereignty 还援引了两位业界大佬的话。Karpathy 称之为 Iron Man suit 哲学:好的 AI 产品应该是增强用户,而不是替代用户。Simon Willison 则警告说,agents are merchants of complexity——当人类把自己从循环中移除时,他们就不再知道发生了什么。
这三条原则不是装饰品,而是 gstack 在做技术决策时的判据。比如为什么 /cso 要给每条 finding 带上 17 个误报排除、8/10 的置信度门槛、以及具体的利用场景——因为 User Sovereignty 要求,用户的时间不应该被低置信度的报警所消耗。
10. 另外几个工程亮点:隧道、Cookie、崩溃恢复
gstack 的硬工程不止上面这些,再快速过几个。
双监听器隧道架构(v1.6.0.0 的安全升级)
当用户运行 pair-agent --client 时,守护进程会启动一个 ngrok 隧道,让远程的配对 agent 能够驱动浏览器。但问题在于:把完整的守护进程接口暴露到公网上,即使躲在随机的 ngrok 子域名后面,/health 接口仍然会在任何 Origin 欺骗下泄漏 root token,而 /cookie-picker 会把 token 嵌入到任何调用者都能获取到的 HTML 中。
gstack 的解决方案是两个 HTTP 监听器,而不是一个:
- (
本地监听器
127.0.0.1:LOCAL_PORT):始终绑定。负责 bootstrap、/cookie-picker、/inspector/*、完整的命令接口。永不转发。 - (
隧道监听器
127.0.0.1:TUNNEL_PORT):在/tunnel/start时惰性绑定,在/tunnel/stop时拆除。只服务一个锁定的白名单:/connect、/command(仅限 scoped token + 浏览器驱动命令白名单)、/sidebar-chat。其他请求一律返回 404。
ngrok 只转发隧道端口。安全属性来自于物理端口的分离:隧道调用者根本够不着 /health 或 /cookie-picker,因为这些路径在那个 TCP socket 上根本不存在。ARCHITECTURE.md 解释得很直接——基于 header 的推断(比如检查 x-forwarded-for、检查 origin)是不可靠的,ngrok header 的行为可能会变化,本地袋里也可能添加这些 header;而 socket 分离则不会出现这些问题。
这个设计非常值得做 agent 远程协作的工具去借鉴。基于 header 的鉴权是脆弱的,而基于 socket 物理隔离的鉴权才是强壮的。
Cookie 安全模型:五条原则
Cookies 是 gstack 处理的最敏感的数据。ARCHITECTURE.md 列出了五条原则:
- :每个浏览器的首次 cookie 导入会触发 macOS Keychain 对话框,用户必须点击“Allow”或“Always Allow”。gstack 永远不会静默地访问凭证。
Keychain 访问需要用户批准
- :cookie 值在内存中解密(PBKDF2 + AES-128-CBC),然后加载进 Playwright context,永远不会以明文的形式写入磁盘。
解密在进程内完成
- ——只显示域名和数量。
cookie picker UI 永远不显示 cookie 值
- :把 Chromium cookie DB 复制到临时文件(避免 SQLite 锁冲突),以只读方式打开。永远不会修改真实浏览器的 cookie 数据库。
数据库只读
- :Keychain 密码和派生的 AES key 在 server 生命周期内缓存于内存中。server 关闭,缓存立即消失。
密钥缓存按会话进行
- :控制台、网络、对话日志中永远不会包含 cookie 值。
日志中不含 cookie 值
cookies命令输出 cookie 元数据,但值会被截断。
这五条原则背后体现了 gstack 对隐私的态度——默认本地、默认不持久化、默认不泄漏。对于一个需要读取用户登录凭证的工具来说,这是应有的克制。
崩溃恢复:不自我治愈
最后来说一个反直觉的设计。server 不尝试自我治愈。如果 Chromium 崩溃(browser.on('disconnected')),server 会立即退出。CLI 在下一条命令上检测到死掉的 server,就会自动重启。
ARCHITECTURE.md 的原话是:这比尝试重新连接一个半死不活的浏览器进程更简单、更可靠。
很多项目在这种地方会写一堆 reconnect 逻辑、状态恢复、tab 重建。而 gstack 选择了最简单的路径——死了就重启。因为重启的成本(约 3 秒)远低于维护一个半死状态的成本。
11. 11.8 万 Star 背后:从源码看魅力是怎么造出来的
到这里,源码层面的事实已经摆得很清楚了。现在回到最开始的那个问题:为什么是 11.8 万 star?为什么偏偏是这个项目?
综合源码分析,魅力可以拆解成几个具体的工程和定位决策,而不是什么玄学。
作者背书是核心信号
Garry Tan 是 YC 的总裁兼 CEO。YC 孵化了 Coinbase、Instacart、Rippling、Airbnb、Stripe、Reddit 这些公司。他本人是早期 Palantir 的工程师、Posterous 的联合创始人。一个有这种履历的人开源自己的软件工厂,本身就是极强的可信度信号——这不是某个无名作者的实验品,而是一个有战绩的人的生产力工具。
这个因素不需要回避——star 数里肯定有相当比例是冲着 Garry Tan 这个名字来的。但这只能算是一张入场券,还撑不起 11 万的留存。
解决了 Claude Code 用户的真实痛点
Claude Code 原生只是一个通用的命令行 AI 助手,用户面对的是空白的 prompt。gstack 提供的是结构化的角色——不再是“帮我写代码”,而是“你是 CEO,重新思考这个产品”。门槛一下子降了下来。
这件事的妙处在于,它没有对 Claude Code 做任何改动,只是往 ~/.claude/skills/ 里放了一堆 Markdown 文件。用户不需要理解 prompt engineering,只需要知道 /qa 是做 QA 的、/ship 是发 PR 的。复杂度被角色化地封装了。
把团队流程编码进了 Markdown
23 个角色不是孤立的命令,它们构成了一个完整的 sprint 闭环:Think→Plan→Build→Review→Test→Ship→Reflect。每个 skill 的输出都是下一个的输入。
这就是“流程即代码”的思路。传统团队的流程要么在文档里、要么在口头约定中、要么在项目经理的脑子里——这些东西都会漂移。gstack 把流程写成了 slash 命令,每次执行都是一致的。这让 AI agent 的工作方式变得可重复,而可重复正是工程化的前提。
浏览器层的硬工程撑起了差异化
“everything else is Markdown”——但浏览器是真正的硬骨头。长驻守护进程、Ref 系统、六层 prompt injection 防御、双监听器隧道、cookie 安全模型——这些都是实打实的工程,不是 prompt 上的小技巧。
HN 上有人说 gstack 就是一堆让 Claude 装成不同人的文本文件。这话对 skill 层成立,但对浏览器层完全不成立。而浏览器层恰恰是 gstack 区别于其他以 prompt 为主的项目的地方——你能在 obra/superpowers 这类以 skill 为主的仓库里找到类似的 prompt,但找不到一个会自己打开浏览器并点击页面的守护进程。
MIT + 免费 + 自托管
没有 premium tier、没有 waitlist、没有 SaaS 依赖。所有数据都留在本地(cookies 在内存中解密、telemetry 默认关闭)。这对注重隐私和可控性的开发者来说,有着很强的吸引力。
社区遥测数据显示:大约有 23,839 个独立安装。注意,这个数字远低于 star 数——这完全符合 GitHub 的普遍规律:点 star 的成本极低,多数人只是围观或收藏,真正下载下来使用的人是少数。
不绑死单一 AI vendor
gstack 支持 10 个 AI coding agent:Claude、Codex、Cursor、Factory、Slate、Kiro、Hermes、GBrain、OpenCode、OpenClaw。/codex 会主动引入 OpenAI 做第二意见,/pair-agent 则让不同 vendor 的 agent 协作。
在 gstack 里增加一个新的 host,只是一个 TypeScript 配置文件的事,完全不需要改动代码。这种把 vendor 抽象掉的态度,在 vendor lock-in 焦虑普遍存在的开发者群体里,绝对是一个加分项。
详尽的工程文档
README 大约 45KB、ARCHITECTURE 约 32KB、ETHOS 约 7.9KB、CHANGELOG 高达 909KB(395 个版本),此外还有 skills.md、ON_THE_LOC_CONTROVERSY.md 等文档。
这些文档不仅写了“是什么”,还写明了“为什么这样设计”、“为什么不那样设计”、以及具体的数字依据。比如为什么选 Bun,给出了四条理由;为什么用 Locator 而不用 DOM 注入,给了三条理由;为什么 L6 需要双分类器投票,也做了详细解释。这种文档质量在开源项目里极其罕见。
与 Karpathy 理念的显式对齐
README 明确声明覆盖了 Karpathy 提出的 AI 编码四类失败模式(错误假设、过度复杂、正交编辑、命令式胜过声明式)。Karpathy 的 skills repo 有 17K star,gstack 主动对标并声称自己是其工作流执行层。
这是一个很聪明的定位——借势 Karpathy 的影响力,同时把自己跟那些规则集类的项目区分开。gstack 卖的不是规则,而是工作流。
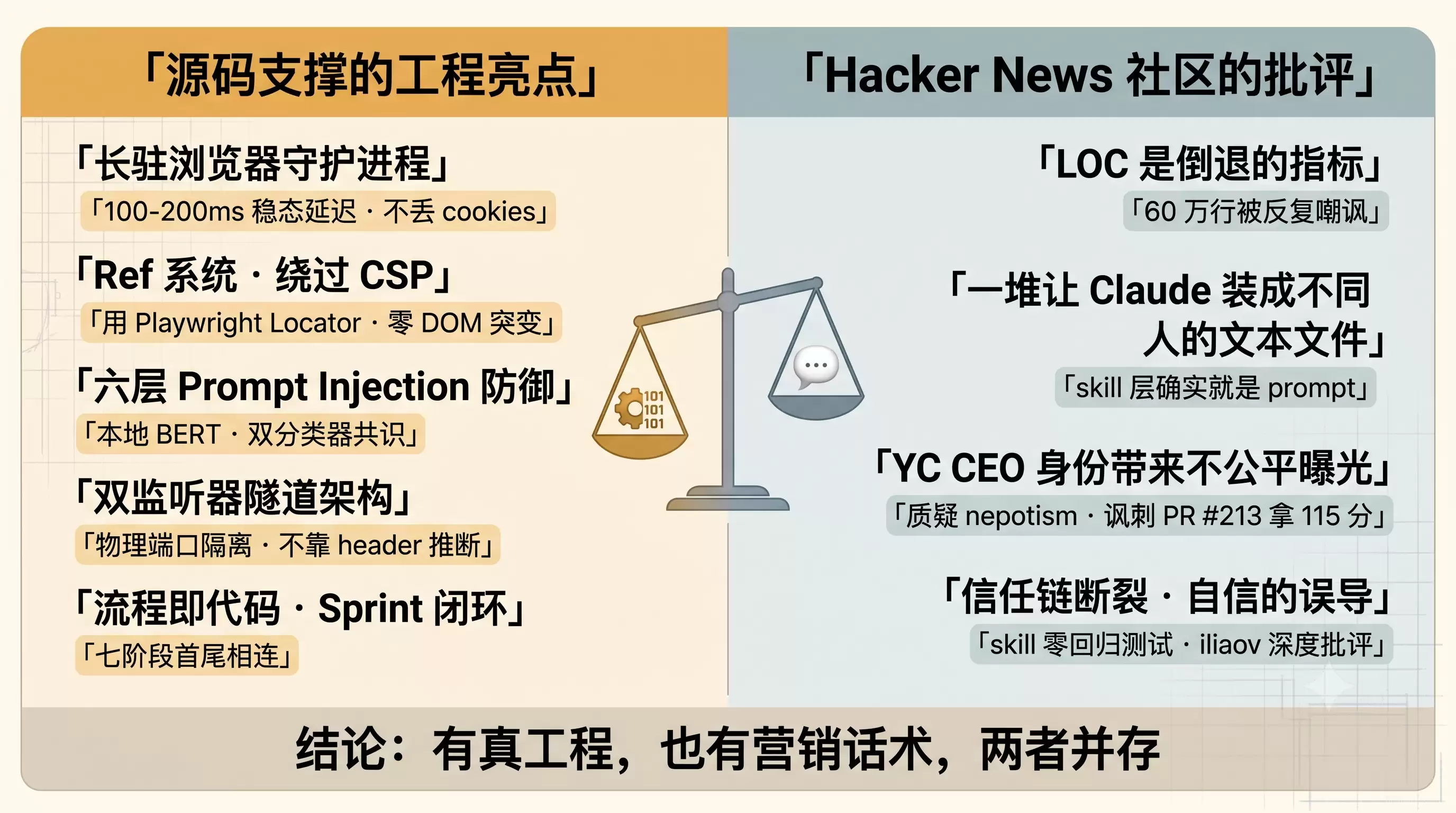
12. 社区另一面:Hacker News 的批评声
讲完了魅力,也得讲讲争议。一个 11 万 star 的项目,Hacker News 上的态度却呈现出两极分化,而且批评的声音非常强烈。批评这一面如果不展开说,这篇文章就变成软文了。
通过 HN Algolia API 检索到的相关帖子里,批评派的核心论点有四条,我们来逐条看一下。
批评一:LOC 作为生产力指标是倒退
这条在评论中被反复提到,有几十条独立评论都持有一致的观点。Garry Tan 在 README 里写道:“In the last 60 days I ha ve written over 600,000 lines of production code”。这句话在 HN 上被反复嘲讽。
代表评论(rileymichael,74 分主帖):"and what is there to show for it? absolutely terrible metric"(然后呢?有什么拿得出手的成果?这是一个糟糕透顶的指标)。
另一个代表评论(the_af):"writing over 600,000 lines of production code is not something to be proud of... measuring progress in LoC is not something that is done anymore"(写出 60 万行生产代码并不是什么值得骄傲的事……用 LOC 衡量进度早就过时了)。
这个批评是完全成立的。LOC 是 70 年代的指标,在 90 年代就已经被批判过了。gstack 自己也意识到了这一点——项目里有专门的 docs/ON_THE_LOC_CONTROVERSY.md 来解释方法论,但社区似乎并不买账。
批评二:这就是一堆让 Claude 装成不同人的文本文件
这是最扎心的一条批评,因为它在一定程度上成立。
fdghrtbrt 的评论:"it's a bunch of files telling Claude to pretend to be different people - I swear that was my analysis as well, verbatim"(就是一堆让 Claude 装成不同人的文件——我发誓这也是我的分析,一字不差)。
CactusBlue 补充道:"Mostly just markdown-based skills... the repo seems pretty light on actual tooling"(主要是基于 Markdown 的 skill……这个仓库在实际工具方面看起来份量很轻)。
这个批评对 skill 层来说是公平的——skill 确实就是 prompt。但它忽略了浏览器层的工程量。问题在于,对于绝大多数只看 README 的人来说,他们看到的只是一堆 slash 命令的列表,看不到那个 58MB 的二进制文件里究竟装了多少东西。
批评三:质疑 nepotism / YC CEO 身份带来不公平曝光
Sherveen(自称在 Product Hunt 上也批评过,据说激怒了 Garry):"If he weren't the CEO of YC, this wouldn't be on PH, and it wouldn't be on HN... This is not an impressive setup. It's overengineered"(如果他不是 YC 的 CEO,这玩意根本上不了 PH,也上不了 HN……这套配置没什么了不起的。就是过度工程化)。
archagon 则质疑帖子曾被 flag 后又由 mod 解除:"How is this anything other than nepotism?"(这不是裙带关系还能是什么?)。
Sherveen 的批评涉及主观判断,但有一个客观事实可以佐证它的存在:在整个 HN 上,gstack 相关帖子里热度排名第一的,是一个讽刺性的 PR。用户 tornikeo 用 Kagi 翻译器把 gstack README 进行“翻译成大白话”处理并提交为 PR #213,拿到了 115 分、22 条评论——比分正经的技术讨论帖(74 分)还高。这被社区视为对营销话术的一次集体解构。
批评四:深度技术批评——信任链断裂
第四条批评最值得技术读者关注。来自 iliaov 的 HN 帖子(9 分):"I'm tired of LLM skill slop, so I built mine with regression tests"(我厌倦了 LLM skill 垃圾,所以我自己造了带回归测试的版本)。
他在使用 gstack 一周后给出的核心批评是:gstack 的 /office-hours 等 skill 完全没有回归测试,“那些完美打磨、听起来很自信的 skill 经常误导我”。
更深刻的洞察是:gstack 的失败根因在于信任链的断裂——“Claude 相信 GStack 知道自己在做什么。GStack 相信我知道自己在做什么。但我是在做研究——研究本质上是你在不知道答案时才做的事”。
iliaov 所指出的这个真问题是:skill 写得越自信,用户就越容易盲目信任;但 skill 本质上只是 prompt,prompt 没有类型检查、没有单元测试。gstack 的三层测试体系测试的是 skill 文档是否与代码一致,但并不测试 skill 给出的建议是否正确。
客观评价:既不是软文目标,也不是 HN 嘲讽的对象
把这些批评摆出来之后,该怎么评价 gstack 呢?
gstack 的浏览器层是实打实的硬工程,这部分完全站得住脚。六层 prompt injection 防御、双监听器隧道、Ref 系统的 Locator 选择——这些设计拿到任何严肃的工程评审中都经得起推敲。
gstack 的 skill 层是 prompt,这部分确实只是 prompt。HN 上所说的“一堆文本文件”对这个层面来说是完全成立的。但这并不等于 skill 层没有价值——将团队流程固化为可复用的工作流,本身就是一种工程化的贡献,只是这个贡献不像浏览器守护进程那样可以用代码行数来衡量。
Garry Tan 的 YC CEO 身份确实带来了不成比例的曝光,这是事实。但曝光只解决了“被看见”的问题,并不能解决“被留下来用”的问题。社区遥测显示的 23,839 个独立安装,以及至少 10 个明确标注了“inspired by gstack”的衍生项目,都证明了这个东西确实在被使用、在被模仿。
HN 上也有少数实际使用过的人给出了正面反馈。用户 madrox 经过几天的深度使用后,评价 plan skills 能够“catch gaps”,DESIGN.md “needs to become a standard practice”,浏览器方案“几乎在所有方面都优于 Claude 内置扩展”。不过他也批评了 CEO skill 的效果不太理想,以及不喜欢 auto-update 被用来推送 Garry's List 文章。这种“用过且有赞有弹”的反馈,比纯围观者的嘲讽更有参考价值。
至于 LOC 指标——这个批评完全成立,gstack 自己也在 ON_THE_LOC_CONTROVERSY.md 中试图辩护,但方法论上的争议并没有因此被消解。
一句话总结:这是一个既有真工程、也有营销话术的项目,两者并存。
 魅力 vs 批评对照
魅力 vs 批评对照
13. 几个衍生项目:从 gstack 长出来的亚文化
最后来说一个很有意思的现象——gstack 已经长出了一个明确的衍生生态。
HN 上至少有 10 个明确标注了“inspired by gstack”的 Show HN 项目,每一个都从不同的角度来弥补 gstack 的那 20%:
| 项目 | 定位 |
|---|---|
| upstack | gstack 的最后 20% 补充,专注 red/green TDD |
| nanopm | gstack 证明了工程团队,我来补 PM 层 |
| CFO-stack | 双分录会计 skill 套件 |
| tonone | 不再给 Claude 写 prompt,给它职位头衔 |
| Gstack++ | gstack 适配 C++ 开发 |
| gstack-fork | 适配 Google Antigra vity + Gemini-CLI |
| CTP Room | 基于 gstack 的多 agent 协作层 |
| the-big-learn | gstack for Learning Chinese |
| imstack | 加密投资管理 skill 套件 |
| gstack-auto | 并行化 gstack 运行 |
这一批项目形成了一个明确的“gstack 模式”亚文化。它们共享同一个核心假设:AI agent 的工作流应该被编码成角色化的 skill,而不是即兴的 prompt。
从开源生态的角度来看,一个项目能催生 10 个明确标注了“inspired by”的衍生项目,这本身就是其开创性地位的证据。在调研范围内,还没有看到 Karpathy 的 skills repo(17K star)或者 obra/superpowers 形成同等规模的衍生生态。
结语:这个项目的真正意义
回到最开始的那个问题:gstack 凭什么拿到 11.8 万 star?
把它讲清楚:跟 LOC 无关,跟 Garry Tan 的名字无关,也跟“23 个专家角色”这种话术无关。撑起 11.8 万 star 的,是几个具体的工程和定位决策——
第一,它把一个真实的长驻浏览器守护进程做到了生产级可用。100-200ms 的稳态延迟、不丢 cookie 的长驻进程、绕过 CSP 的 Locator 方案、6 层 prompt injection 防御——这些才是能让 AI agent 真正操作 Web 的工程。
第二,它把不可重复的 AI 即兴对话,固化成了可复用的 sprint 闭环。Think→Plan→Build→Review→Test→Ship→Reflect,每一步都接住上一步的产出。流程即代码不仅仅是一句口号,而是真正把团队的口头约定变成了 slash 命令。
第三,在 vendor lock-in 焦虑的时代,它选择做 vendor 中立。10 个 host、/codex 主动跨模型、新增 host 零代码改动。
还有几件事也得算上:MIT 协议、默认本地化、文档把“为什么这样设计”写得很明白。
至于它的问题,也没必要回避:skill 层缺乏回归测试导致自信的误导、LOC 指标的营销包装、过度工程化的指控——这些都是真实存在的问题,在使用的时候心里要有数。
但有一个判断是确定的:不管 gstack 这个具体项目最终走向哪里,它所确立的那个范式——AI agent 的工作流应该被角色化、被流程化、被工程化——会留下来。那 10 个衍生项目就是最好的证据。
下一个时代的开发工具长什么样,大概率会带有 gstack 的影子。




