给Transformer变个形,LLM竟能变得更聪明
来源:互联网
时间:2026-06-30 15:44:19
2026年6月,大模型行业正经历一场“开源海啸”:英伟达放出550B参数混合架构模型,谷歌送出多模态Gemma新版本,智谱以最宽松协议全量开源旗舰模型。几乎所有厂商都在讲同一个故事:用混合专家(MoE)结构装下更多参数,用更稀疏的激活方式压低成本,用弹性网络宽度匹配不同部署场景。
简单来说,整个行业都在拼命研究“怎么把更多参数,塞进同样算力预算”。
但一篇来自Mila、康奈尔大学和蒙特利尔大学研究者新论文,提出了一个方向几乎完全相反的问题:**如果参数一个都不加,只是把模型里已存在的参数“挪个位置”**,会怎样?
 论文标题:Ta pered Language Models
论文地址:https://arxiv.org/abs/2606.23670
## 背景:被忽视的“一视同仁”
从2017年那篇开创Transformer的《Attention Is All You Need》开始,几乎所有语言模型都共享同一种骨架——不管是经典Transformer,还是后来的门控注意力、循环记忆网络,甚至带“测试时记忆”能力的新架构:把若干结构完全相同的“层”叠在一起,每层分到的参数量一模一样。
论文标题:Ta pered Language Models
论文地址:https://arxiv.org/abs/2606.23670
## 背景:被忽视的“一视同仁”
从2017年那篇开创Transformer的《Attention Is All You Need》开始,几乎所有语言模型都共享同一种骨架——不管是经典Transformer,还是后来的门控注意力、循环记忆网络,甚至带“测试时记忆”能力的新架构:把若干结构完全相同的“层”叠在一起,每层分到的参数量一模一样。
 这好比一家连锁餐厅,无论开在闹市区还是郊区,都配备完全相同数量的厨师和厨房设备,完全不考虑客流量差异。这种“一视同仁”的分配省心、好维护,但未必是最优解。
近年来,越来越多研究从不同角度指出:模型的层并不是同等重要的。
“**提前退出**”实验显示,很多时候模型还没跑到最后一层,答案已基本定型;“**层剪枝**”研究发现,砍掉后面一些层,模型表现几乎不受影响;**可解释性研究**则发现,浅层网络捕捉的是语法这类“基础信息”,深层网络处理的是语义这类“高级信息”。
换句话说,层与层之间天差地别,但参数分配却始终一视同仁。
这正是论文提出的核心疑问:既然层的重要性早已被证明不均匀,为什么层的“脑容量”还要被均匀分配?
## 把“脑容量”往前挪
研究团队先做了个简单粗暴的验证实验:把一个440M参数的Transformer模型层分成早、中、晚三组,在保持总参数量不变前提下,让其中一组的“前馈网络”(FFN,模型中负责存储和处理信息的核心组件,可理解为每层的“工作记忆容量”)变宽,其余两组变窄。
结果非常直观:把容量集中到前段的“头重脚轻”式分配,让模型在验证集上的困惑度(perplexity,衡量语言模型预测准确程度的指标,数值越低代表预测越准)从16.28降到15.96;反过来把容量集中到后段,困惑度反而飙升到17.29。
这好比一家连锁餐厅,无论开在闹市区还是郊区,都配备完全相同数量的厨师和厨房设备,完全不考虑客流量差异。这种“一视同仁”的分配省心、好维护,但未必是最优解。
近年来,越来越多研究从不同角度指出:模型的层并不是同等重要的。
“**提前退出**”实验显示,很多时候模型还没跑到最后一层,答案已基本定型;“**层剪枝**”研究发现,砍掉后面一些层,模型表现几乎不受影响;**可解释性研究**则发现,浅层网络捕捉的是语法这类“基础信息”,深层网络处理的是语义这类“高级信息”。
换句话说,层与层之间天差地别,但参数分配却始终一视同仁。
这正是论文提出的核心疑问:既然层的重要性早已被证明不均匀,为什么层的“脑容量”还要被均匀分配?
## 把“脑容量”往前挪
研究团队先做了个简单粗暴的验证实验:把一个440M参数的Transformer模型层分成早、中、晚三组,在保持总参数量不变前提下,让其中一组的“前馈网络”(FFN,模型中负责存储和处理信息的核心组件,可理解为每层的“工作记忆容量”)变宽,其余两组变窄。
结果非常直观:把容量集中到前段的“头重脚轻”式分配,让模型在验证集上的困惑度(perplexity,衡量语言模型预测准确程度的指标,数值越低代表预测越准)从16.28降到15.96;反过来把容量集中到后段,困惑度反而飙升到17.29。
 同样的参数总量,仅仅因为摆放位置不同,效果差出1个多点,这在语言模型评测体系里是相当大的差距。
这个发现把问题引向更细的方向:与其用“一刀切”的三段式分组,能不能用一条更平滑的曲线,让容量从前到后逐渐递减?
研究者将这种思路命名为**“锥形语言模型”(Ta pered Language Models, TLMs)**:选定模型中任意一个决定参数量的维度(比如前馈网络的宽度),让它沿着深度方向单调递减,同时保证所有层的平均宽度依然等于原来的固定值。这样总参数量和计算量都完全不变,只是分布形状从“长方形”变成了“楔形”。
团队尝试了三种递减曲线:**线性递减**、**余弦递减**、**S形(Sigmoid)递减**。
这三种曲线的差异,类似于三种不同的“收摊”方式:
同样的参数总量,仅仅因为摆放位置不同,效果差出1个多点,这在语言模型评测体系里是相当大的差距。
这个发现把问题引向更细的方向:与其用“一刀切”的三段式分组,能不能用一条更平滑的曲线,让容量从前到后逐渐递减?
研究者将这种思路命名为**“锥形语言模型”(Ta pered Language Models, TLMs)**:选定模型中任意一个决定参数量的维度(比如前馈网络的宽度),让它沿着深度方向单调递减,同时保证所有层的平均宽度依然等于原来的固定值。这样总参数量和计算量都完全不变,只是分布形状从“长方形”变成了“楔形”。
团队尝试了三种递减曲线:**线性递减**、**余弦递减**、**S形(Sigmoid)递减**。
这三种曲线的差异,类似于三种不同的“收摊”方式:
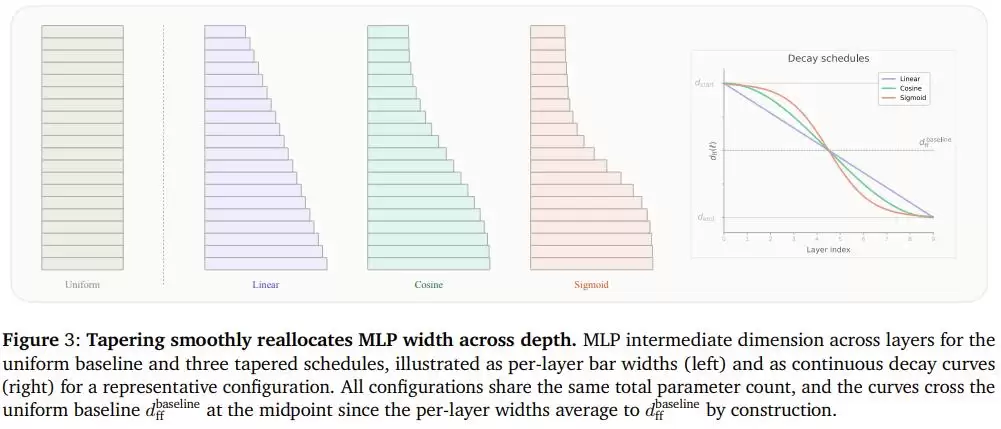 线性递减像是匀速关店,每一段时间关掉差不多数量的柜台;S形递减像是突然集中宣布闭店,大部分摊位维持原样,只有中间一小段急速收索;余弦递减则介于两者之间,两头平缓过渡,中段逐渐收紧,既不会“一刀切”地损失两端灵活性,也不会平均用力而错过最该收索的地方。
## 实验结果:免费的1.84个点
在440M参数Transformer上做完五种宽度比例和三种曲线的组合扫描后,余弦递减以全面优势胜出:在最优配置下(前段宽度是基准的1.5倍,后段是基准的0.5倍),困惑度从均匀分布基线的16.28降到14.44,整整改善了1.84个点,全程没有增加一个参数或一次额外的浮点运算。
线性递减像是匀速关店,每一段时间关掉差不多数量的柜台;S形递减像是突然集中宣布闭店,大部分摊位维持原样,只有中间一小段急速收索;余弦递减则介于两者之间,两头平缓过渡,中段逐渐收紧,既不会“一刀切”地损失两端灵活性,也不会平均用力而错过最该收索的地方。
## 实验结果:免费的1.84个点
在440M参数Transformer上做完五种宽度比例和三种曲线的组合扫描后,余弦递减以全面优势胜出:在最优配置下(前段宽度是基准的1.5倍,后段是基准的0.5倍),困惑度从均匀分布基线的16.28降到14.44,整整改善了1.84个点,全程没有增加一个参数或一次额外的浮点运算。
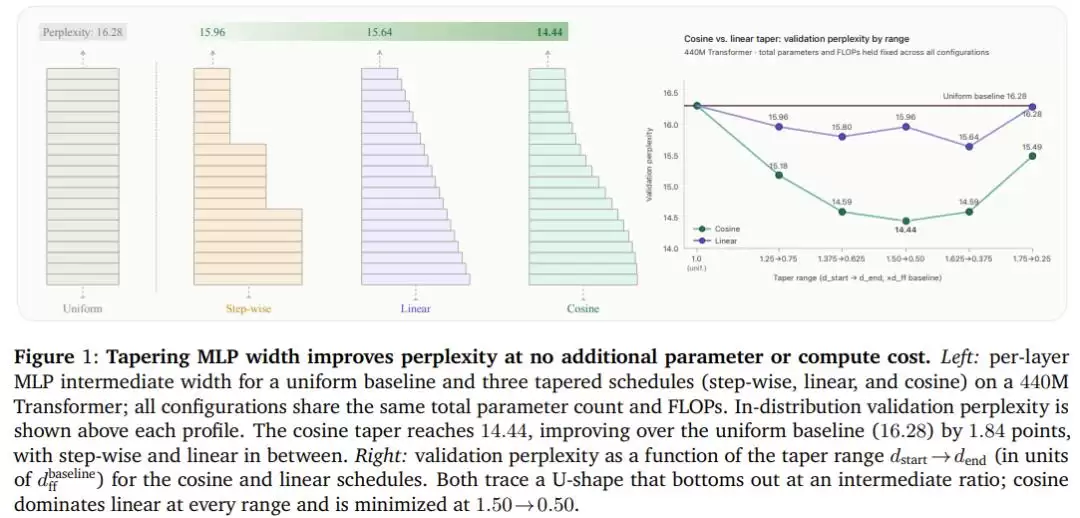
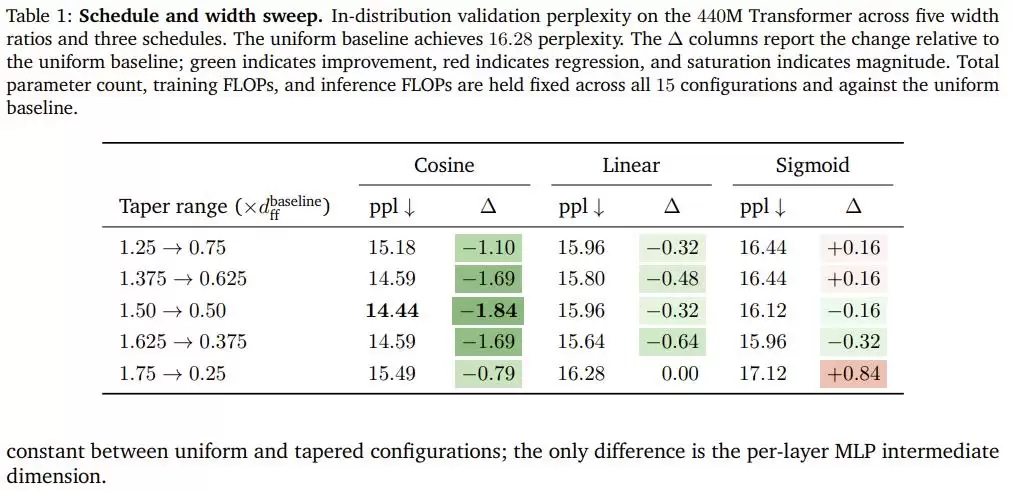 更关键的是,这个结论不是某一个架构的运气。
研究团队把同一套配置(余弦递减、前后宽度比1.5/0.5)原封不动搬到另外三种结构迥异的架构上:带门控机制的注意力模型、具备“自我修改记忆”能力的Hope-attention,以及拥有神经长期记忆模块的Titans架构,并在760M和1.3B参数两个更大规模上重新验证。
更关键的是,这个结论不是某一个架构的运气。
研究团队把同一套配置(余弦递减、前后宽度比1.5/0.5)原封不动搬到另外三种结构迥异的架构上:带门控机制的注意力模型、具备“自我修改记忆”能力的Hope-attention,以及拥有神经长期记忆模块的Titans架构,并在760M和1.3B参数两个更大规模上重新验证。
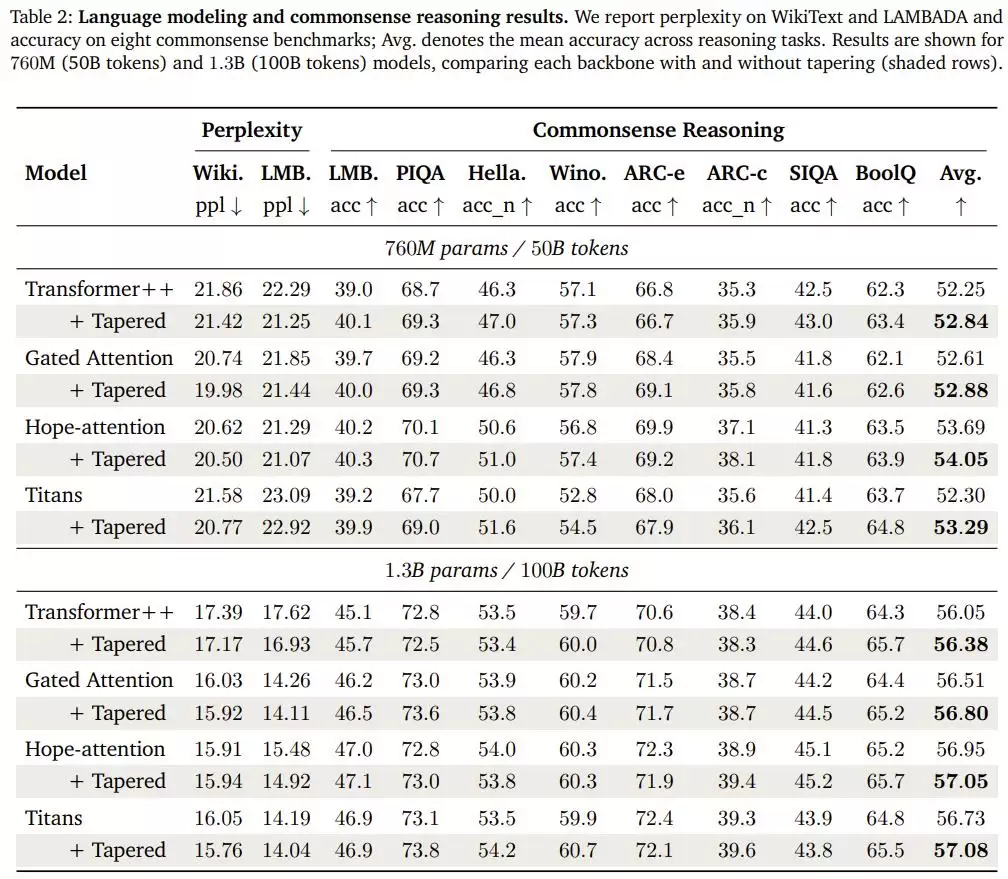 结果是:四种架构、两种规模,所有八组对比中,经过“锥形化”改造的模型在常识推理基准上的平均准确率全部提升,在LAMBADA语言预测任务上的困惑度全部改善。
研究者还额外做了长文本检索测试(Needle-in-a-Haystack),确认这种重新分配并不会牺牲模型处理长上下文的能力。
为了解释这种现象背后的原因,团队测量了GPT-2系列模型中每一层“前馈网络”输出与已有信息流的相似程度,发现一个清晰规律:越往模型深处走,每一层新写入的内容,跟已存在的信息越像。也就是说,**后段的层更多是在“重复强调”已有判断,而不是在“创造”新理解**。
结果是:四种架构、两种规模,所有八组对比中,经过“锥形化”改造的模型在常识推理基准上的平均准确率全部提升,在LAMBADA语言预测任务上的困惑度全部改善。
研究者还额外做了长文本检索测试(Needle-in-a-Haystack),确认这种重新分配并不会牺牲模型处理长上下文的能力。
为了解释这种现象背后的原因,团队测量了GPT-2系列模型中每一层“前馈网络”输出与已有信息流的相似程度,发现一个清晰规律:越往模型深处走,每一层新写入的内容,跟已存在的信息越像。也就是说,**后段的层更多是在“重复强调”已有判断,而不是在“创造”新理解**。
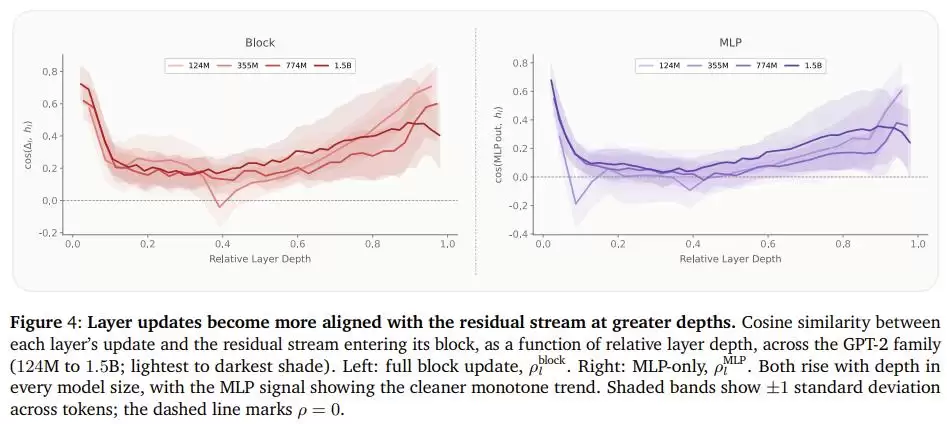 这恰好印证了为什么把容量从后段挪到前段是合理的:前段的层真正用得上这些额外的“脑容量”,后段的层用不上。
## 结语
这项研究本质上提出了一个朴素却被长期忽视的命题:模型的容量不该是均匀泼洒出去的资源,而应流向真正需要它的地方。
在整个行业都比拼“谁的参数更多”“谁的架构更稀疏”的2026年,这篇论文提供了一个几乎零成本的替代方案:不需要换架构,不需要加参数,只需要换一种分配的“形状”。
研究者也坦言,目前的最优配置是在一个440M参数模型上调出来的,是否存在更适合不同规模、不同架构的“专属配方”,仍是开放问题。
但更值得关注的是,论文指出这套思路并不局限于语言模型——视觉Transformer、扩散模型、多模态模型,几乎都继承了同一种“层层均分”的默认设定。如果容量分配的形状本身就是一个被长期忽视的设计维度,那么这把“藏在明处的免费杠杆”,或许才刚刚被人注意到。
## 团队简介
论文由Mila(蒙特利尔学习算法研究所)的Reza Bayat、康奈尔大学的Ali Behrouz,以及Mila联合创始人、蒙特利尔大学教授Aaron Courville共同完成。
Ali Behrouz目前是Google Research研究员、康奈尔大学博士生,过去两年里参与设计了多个引发广泛关注的新架构,包括能够“在测试阶段学习记忆”的Titans架构,以及后续的Atlas和“嵌套学习”(Nested Learning)框架,长期专注于如何让模型更高效地利用和存储长期上下文信息。
这恰好印证了为什么把容量从后段挪到前段是合理的:前段的层真正用得上这些额外的“脑容量”,后段的层用不上。
## 结语
这项研究本质上提出了一个朴素却被长期忽视的命题:模型的容量不该是均匀泼洒出去的资源,而应流向真正需要它的地方。
在整个行业都比拼“谁的参数更多”“谁的架构更稀疏”的2026年,这篇论文提供了一个几乎零成本的替代方案:不需要换架构,不需要加参数,只需要换一种分配的“形状”。
研究者也坦言,目前的最优配置是在一个440M参数模型上调出来的,是否存在更适合不同规模、不同架构的“专属配方”,仍是开放问题。
但更值得关注的是,论文指出这套思路并不局限于语言模型——视觉Transformer、扩散模型、多模态模型,几乎都继承了同一种“层层均分”的默认设定。如果容量分配的形状本身就是一个被长期忽视的设计维度,那么这把“藏在明处的免费杠杆”,或许才刚刚被人注意到。
## 团队简介
论文由Mila(蒙特利尔学习算法研究所)的Reza Bayat、康奈尔大学的Ali Behrouz,以及Mila联合创始人、蒙特利尔大学教授Aaron Courville共同完成。
Ali Behrouz目前是Google Research研究员、康奈尔大学博士生,过去两年里参与设计了多个引发广泛关注的新架构,包括能够“在测试阶段学习记忆”的Titans架构,以及后续的Atlas和“嵌套学习”(Nested Learning)框架,长期专注于如何让模型更高效地利用和存储长期上下文信息。
 Aaron Courville则是深度学习领域的资深学者,CIFAR AI Chair,长期与Yoshua Bengio共同推动深度学习基础研究,在表征学习和生成模型方向有深厚积累。他也是生成对抗网络(GAN)的作者之一,并与Ian Goodfellow和Bengio合著了经典著作《Deep Learning》。
Aaron Courville则是深度学习领域的资深学者,CIFAR AI Chair,长期与Yoshua Bengio共同推动深度学习基础研究,在表征学习和生成模型方向有深厚积累。他也是生成对抗网络(GAN)的作者之一,并与Ian Goodfellow和Bengio合著了经典著作《Deep Learning》。