
全球首个:隐空间世界模型,打通长时序双向物理因果链了!
你从桌上端起一杯水,大脑用了
不到一秒
估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。
在这个动作中,你的大脑不会在意杯子上的花纹,或是杯壁折射出的复杂光影,而是能瞬间抓住核心:
手要出多少力,水才不会晃出来
正是这种忽略无关的环境细节、
直接洞察本质的“物理直觉”
但对机器人来说,想要学会这种对物理世界的因果直觉,基本属于具身智能领域的高难度悬赏题。
现在,一家成立仅一年的具身智能新锐——
无界动力
其正式发布了
全球首个“长时序双向物理因果链”隐空间世界模型MWA™
在由斯坦福大学等顶尖机构联合发起的RoboCasa GR1 TableTop榜单中,无界动力MWA™以
75.2%的平均任务成功率拿下全球第一
英伟达GR00T-N1.6

作为赛道里的新晋选手,无界动力是行业里少数坚持
“隐空间世界模型 + 强化学习”
这条略显特立独行的硬核路线,不仅在技术实测上跑通了闭环,在资本市场也展现出了极强的吸金能力:
公司此前已宣布完成
超2亿美元的天使轮融资
2亿美元融资
这只既能打、又吸金的行业黑马,究竟是如何帮机器人看清物理因果、打破多场景泛化瓶颈的?
我们拆开来细看。
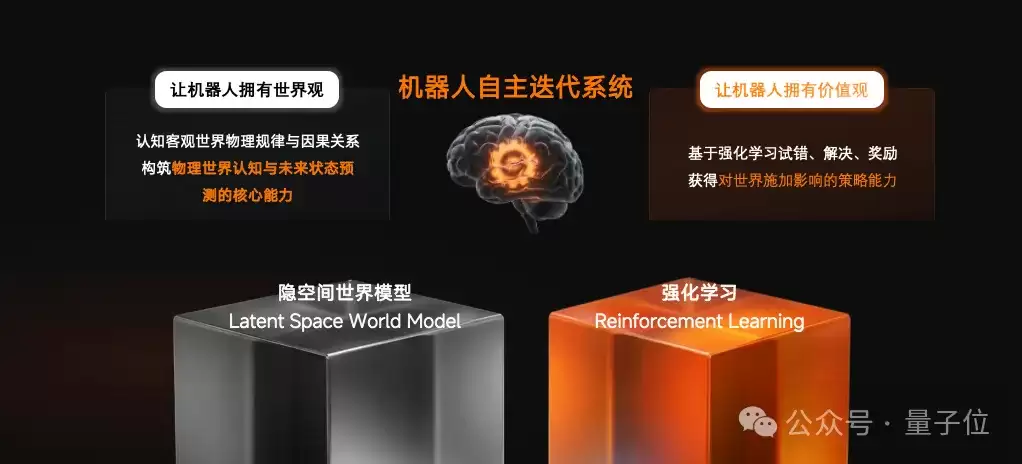
通向终局的路线:隐空间世界模型 + 强化学习
懂了语言和逻辑,机器人就能在现实世界里听懂话、能干活了吗?
答案是:并不行。
过去几年,VLA(视觉-语言-动作)具身智能路线,虽然让机器人听懂了人类的文本指令。
但一到现场,只要光照稍微变一下、桌上的杯子挪个几厘米,机器人就会瞬间“卡壳”甚至动作变形。
本质原因在于,传统VLA模型让机器人干活,更像是一场“刻板的开卷考试”。
它们极度依赖人类演示的模仿学习,只是在死记硬背人类演示的动作轨迹,底层根本不理解物理世界的因果关系,泛化性自然出现断崖式下跌。
人类能处理各种非标任务,靠的是大脑天然具备对物理世界的“直觉推理”。如果机器人对现实的常识认知一片空白,其策略上限就会被锁死在旧范式里。
无界动力选的是另一条路线:
隐空间世界模型 + 强化学习
其中,
隐空间世界模型
强化学习
先看懂因果,再学会行动。只有让机器人看清物理世界的因果边界,它才能真正跨越实验室Demo,到多元场景里下场干活。
机器人如何懂物理?别盯像素,去抓环境变化的“潜动作”
但要建这个世界模型,随之而来的第一个问题是:
模型到底该看什么?
传统路线在推演未来时,往往在像素空间里做预测。
机器人看一段视频,不仅要学手怎么去抓杯子,还要顺便把背景里光线的微妙变化、无意义的像素噪声、甚至地板的纹理全算一遍。
大量算力浪费在了与任务无关的冗余信息上。
无界动力的MWA™全程在
统一共享的隐空间(Latent Space)
更关键的是,它提炼出了
“潜动作(Latent Action)”
什么叫“潜动作”?
传统具身智能依赖显式的动作空间,需要人类事先标记好机械臂末端走到哪个位置、关节沿什么轨迹转动,标注成本极高。
而“潜动作”绕开了这一步,直接在特征高维空间内,把视频中“物体因受到交互而产生的位置、状态变化”抽象成一组高维表征。
不依赖任何人工动作标注,模型自己能从画面变化中归纳出动作的本质。
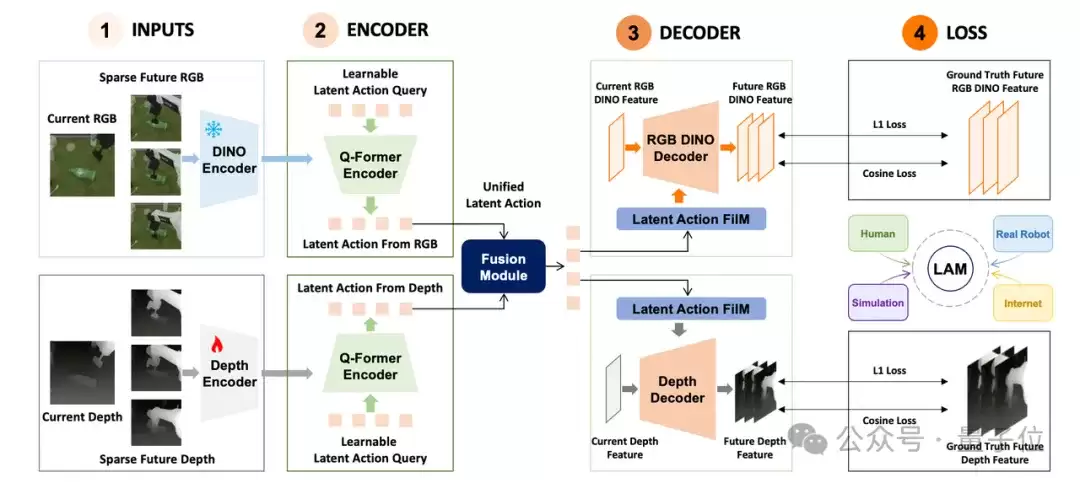
有了“潜动作”,MWA™就能摆脱对传统“动作标签(Action Label)”的依赖。
这样一来,面对互联网上数以亿计、根本没有人类标注动作的原始海量视频,MWA™可以直接拿来训练。
它能自动穿透那些无关紧要的背景噪点,利用潜动作直接由果推因,看懂视频里物体受力与演变的本质物理常识。
这相当于直接盘活了互联网这座无标签数据的金山,让多源数据的利用效率向前迈进了一大步。
告别“单步死磕”,“长时序双向物理因果链”创新世界模型核心范式
面对“动作卡顿与连贯性缺失”问题,MWA™在底层设计上采用了“隐空间双向动力学架构”。
这套架构在隐空间内构建了一套
“正逆双向逻辑协同”
简单说,模型内部同时跑着两条推理线:
一条是逆动力学,负责
“由果推因”的特征提取
另一条是正动力学,负责
“由因及果”
这两条线不是各跑各的,架构中引入了“正逆互审机制”。
逆向模型推演出的动作,必须交给正向模型在脑海中进行沙盘推演和虚拟验证,正向模型推演出的环境变化,也必须实时返回,与逆向模型预训练中沉淀的物理本质认知进行因果对齐。
正反互审、反复校验,从而赋予模型极高的因果推理精度。
然而,传统的双向动力学架构在走向复杂现实时,依然存在一个致命盲区:
即便进入了隐空间,它们也普遍受限于“单步瞬时潜动作推理”的时序局限。
在这种单步推理机制下,模型缺失了对长时序因果的宏观归纳能力,让机器人只能“走一步、看一步、猜一步”。
这也导致了在面对长周期的连续作业时,任何微小的单步预测偏差,都会在连续时序中像滚雪球一样迅速放大,最终引发动作不连贯甚至系统的全面崩溃。
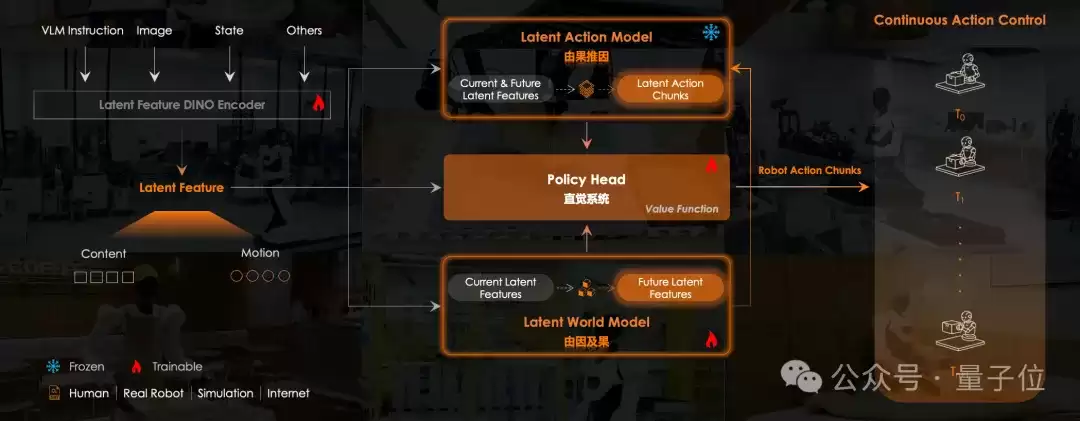
正是看穿了这一局限,无界动力在双向动力学的基础上做出了核心范式创新,推出
全球首个“长时序双向物理因果链”隐空间世界模型
MWA™
首创时序Chunk级逆向动力学建模机制
这也直接把过去那种“走一步看一步”的瞬时操作,带入了长时序动作的连续推演。
在面对复杂的连续任务时,MWA™
在生成动作序列的全过程中,完成动作执行与环境变化的长周期博弈推演
这从底层大幅减弱了误差放大的“雪球效应”,让机器人具备了真正完成复杂长时序任务的能力。
不妨用一个具体场景,来理解这套机制是怎么工作的。
这套机制里有三个角色协同工作。
- 是直觉,负责第一时间给出动作方案;
策略网络(Policy Head)
- 是推演者,负责在脑子里模拟“这么做了会怎样”;
正向动力学模型(FDM)
- 是复盘者,负责从结果反推“到底是哪个动作导致的”。
逆向动力学模型(IDM)
机器人擦桌子。桌上有水渍,水渍旁边放着一个易碎的玻璃杯。
Policy Head基于直觉快速输出一个原始动作:用抹布从右向左擦拭。
此时,FDM接手,基于当前图像的隐特征与这个动作,在“脑内沙盘”中前置推理出下一帧的隐空间变化,结果是杯子将被无意打翻。
这一不可接受的后果,随即与当前特征一同输入给IDM,由IDM反向精确锁定造成杯子被打翻的那部分动作分量。
Policy Head随即做出价值判断,在梯度回传更新时,强制策略远离该危险动作区间,用物理因果链提前规避了现实中的碰撞打滑。
反过来,如果Policy Head输出的动作经过FDM推演后,得出的下一帧特征是水渍被成功擦除,IDM会进一步通过前后时序的结构变化由果推因,推理出若要完美擦除水渍,最优的动作特征应该是
幅度更契合、能效更高的潜动作表征
策略系统随即进行对齐,主动拉近差距,强制控制序列向这个更优的幅度和轨迹靠拢。
隐空间内的一拉一推,FDM推演后果,IDM追溯原因,MWA™在机器人真正触碰物理世界之前,就为其划定了高确定性的动作禁区与推荐区间,从而
让泛化动作的输出更加连贯、高精密
机器人也需要一本错题集
如果说隐空间世界模型为机器人树立了看清因果的“世界观”,那么如何把这种脑海里的常识,变成真实场景里抗干扰、不掉链子的“价值观”与执行力?
无界动力的做法,是
从底层架构让隐空间世界模型原生适配强化学习(RL)机制
通过“物理因果建模 + 强化学习试错 + 边界认知进化”的闭环,让机器人在虚拟演练场里高频自我进化。
但要练出真正抗造的身手,全行业目前都卡在了同一个瓶颈上——
数据集普遍“重正轻负”
翻开现在的行业数据集,几乎清一色全是“完美正样本”,极少有颗粒度够细的各类失败的教训。
这就像一个学生只做满分范文的阅读理解,从来没见过扣分点在哪。
考试的时候他知道好作文长什么样,但不知道自己写的哪里会丢分,改都不知道往哪改。
强化学习的道理一样,如果数据集里只有“做对了”,没有
“做错了”和“差一点做对”
也正是因为这种数据结构,直接导致了强化学习因为缺乏多维度的样本对照,因此行业里根本拿不到高频、稠密的奖励反馈来调优策略。
针对这个行业痛点,无界动力首创了
AnyPhys负样本核心数据体系
他们不再只给机器人喂标准答案,取而代之的是把深层负样本、细粒度边界失稳样本、甚至是“差一点就成功”的次优样本,与基准正样本交织在一起。
目前,AnyPhys已经累计沉淀了
几万条专属的失败、失稳和临界边界样本
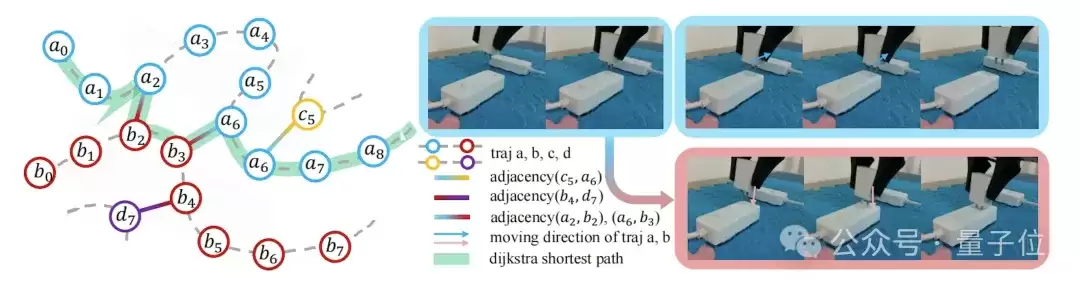
团队摒弃了传统单一最大化成功奖励的模式,建立了一套自动区分正、负、次优、边界样本的方法论,实现强化学习的复杂稠密奖励设计。
这套方法论不需要额外人工标注,就能充分复用带瑕疵的演示数据,显著增强机器人实操精度与泛化能力。
例如,在精密接插类任务中,基于机器人位姿搭建全局空间图,以末端三维距离为运动代价,求解抵达目标的最短路径,借助剩余路径距离量化动作进度,清晰辨别前进、倒退、停滞状态,实现自动对样本进行打分和分类。
算法兼容离线模仿加权、在线稠密奖励两类训练场景,在高精密插接任务实测中,噪声数据下任务成功率最高
提升5倍
非共识路线拿了第一名,赶超英伟达
说回开头提到的那个榜单。
近日,在具身智能领域的权威评测基准RoboCasa中,无界动力与中科院自动化所-深度强化学习团队联合发布的隐空间世界模型MWA™ – WALA,以
75.2%的平均任务成功率刷新行业纪录、斩获全球第一
这个榜单的含金量值得展开说一下,RoboCasa由斯坦福大学等顶尖机构联合发起,是业界公认的具身操作核心评测赛场之一。
它不是让机器人在理想环境里做几个标准动作就算过关。
测试场景涵盖多种非标厨房环境及交互物件,囊括了
长时序复合流程、受限空间物件拿取
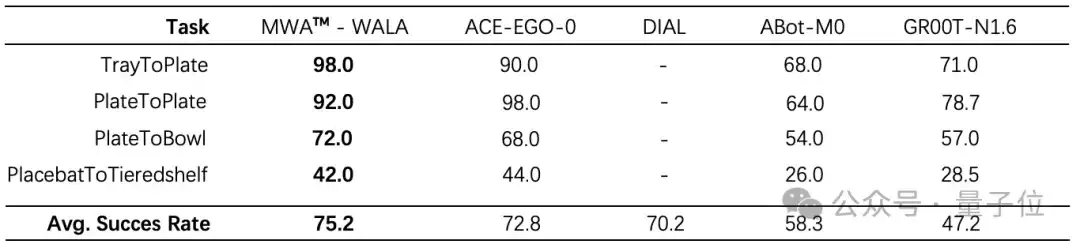
实测数据显示,MWA™ – WALA相比第二名模型任务成功率
提升2.4%
这个成绩背后有一个细节值得注意。
MWA™ – WALA能在强不确定性中稳定作业,核心得益于其对互联网上无标签原始数据的深度激活。
对比测试表明,大规模无标签数据训练带来的
全场景泛化能力提升
不仅押注技术,更看重人
具身智能赛道上融资不算新鲜事,但无界动力的节奏多少有些不寻常。
成立一年,天使轮超2亿美元,Pre-A轮
近2亿美元
2026年上半年累计融资数亿美元
红杉中国、线性资本、京东关联基金等机构都在投资方名单里。
资本愿意在天使轮就押这个体量,看的不只是技术路线,更关键的是这支团队过去已经完整跑过一遍“从算法到量产”的全周期。

无界动力
CEO张玉峰
他带过千人团队,把地平线的智能驾驶软件算法产品从研发推到规模化交付,最终把地平线智驾业务从0做到了
中国市场份额第一
更被行业记住的一笔,是他主导的与大众集团24亿欧元业务合作,这是中国智驾方案首次向全球顶级车企的技术输出,也是那个阶段中国智驾产业最大的一笔出海订单之一。
无界动力
联合创始人兼CTO夏中谱
他是中国智能驾驶产业里研发并量产端到端模型的关键人物之一,曾带着不到40人的团队,在一个半月内拿出了首版Demo。
在无界动力,他主导的是最核心的技术栈:隐空间世界模型+强化学习的研发,以及底层技术基础设施的构建。
有投资人评价,张玉峰和夏中谱的组合,是从
理想与地平线
一个知道怎么把技术推到产线上,一个知道怎么把算法逼到极限。
这种“兼具技术与商业化落地”的基因,也直接反映在了无界动力的商业化节奏上。
成立仅一年,无界动力签下了
总额近1亿美元的全球订单
合作方的名单覆盖了几条差异很大的产业链:
汽车领域,与ZF LIFETEC、欧摩威集团等全球头部供应商达成战略合作;
能源领域,与远景科技签署了
超5亿元rmb

在消费端,无界动力与国内外知名连锁咖啡品牌合作,把机器人推进了开放、动态的商业服务场景。

从汽车产线到咖啡门店,场景跨度这么大,对技术的要求截然不同。无界动力的做法是自研一套通用的硬件底座来打通。
而在环境更复杂的家庭场景中,机器人同样展现出了细腻的物理常识。面对各种动态多任务,它能靠着
自主决策和长周期推演
自适应泛化能力

目前公司已经全栈自研了
1200 TOPS(INT8)的大小脑一体大算力计算平台
不同场景跑出来的实操数据,持续回流到核心模型的训练管线里,形成数据反哺技术的正向循环。
具身智能赛道的淘汰赛已经开始。Demo阶段结束了,行业开始看一个更硬的指标——
你的机器人,能不能真干活、真交付?
无界动力的回答指向一个更底层的命题。
比起教机器人学会更多任务愈发重要的,是让它理解物理世界本身的规律。
一个真正懂重力、懂碰撞、懂摩擦的具身大脑,不需要逐个场景去训练,它会自己学。
这可能是通往通用具身智能最难的一条路,但也是
最根本
一群从产业深处走出来的较真工程师,正在一步步把它走通。
— 完 —




