
Milvus 索引引擎拆解:3 层填充、编译期分流和 16 倍内存取舍
这是 Milvus 源码深度分析系列的第 3 篇。前两篇聊了数据隔离(多租户)和数据维护(Compaction),这一篇转到查询加速这条线,看看索引引擎在背后做了什么。
坦白说,写之前还以为 Milvus 的索引没什么可挖的——无非是用户指定一个 index_type,系统调对应算法库,建完存盘。翻了一圈源码才发现不是这么回事。
举一个很值得琢磨的疑问。翻 pkg/util/paramtable/ 目录时会注意到一个反直觉的现象:Milvus 的 AUTOINDEX 在 CPU 上默认用 HNSW_SQ,在 GPU 上默认用 GPU_CAGRA——这两个连索引家族都不一样。一个加了标量量化的图索引,一个是 NVIDIA 专用的 GPU 图索引。为什么不是同一个 HNSW 加不加量化的区别?更奇怪的是,autoindex_param.go 里还有 HNSW M:18 efConstruction:240 这个配置,跟前面两个都对不上。
带着这个疑问去读源码,牵出了一整套被忽略的设计取舍:三层参数填充管线、Go build tag 决定的硬件分流、保守到近乎偏执的版本聚合策略。这篇就一个一个拆。
1. AUTOINDEX 不是魔法,是三层填充管线
先说第一个被神化的概念。AUTOINDEX 在文档里被描述成「自动帮你选索引」,听起来像有一套智能算法在根据数据特征做决策。实际看完源码,它的本质是一套基于配置前缀、分阶段、可叠加的默认参数填充机制。
它不改变索引构建算法,只是确保不管用户给了多少参数,最终下发给 IndexNode 的都是一个完整、可执行的参数集。这件事靠三层接力完成。
第一层:Proxy 按数据类型分流
入口在 internal/proxy/task_index.go 的 createIndexTask.PreExecute。当 autoIndex.enable 打开、或者用户根本没指定索引类型时,系统会按字段的数据类型,从配置里取默认参数。分流表大致长这样:
| 数据类型 | 配置项 | 默认索引 |
|---|---|---|
| DenseFloat 向量 | autoIndex.params.build | HNSW_SQ(无 GPU)/ GPU_CAGRA(有 GPU) |
| Int8 向量 | autoIndex.params.int8.build | HNSW M:18 efConstruction:240 |
| 稀疏向量 | autoIndex.params.sparse.build | SPARSE_INVERTED_INDEX IP |
| 二值向量 | autoIndex.params.binary.build | BIN_IVF_FLAT HAMMING |
| 去重向量 | autoIndex.params.deduplicate.build | MINHASH_LSH MHJACCARD |
| 大 TopK 场景 | autoIndex.params.largeTopK.build | IVF_SQ8 |
看到这里,前面那个让人困惑的 HNSW M:18 efConstruction:240 就对上了——那是 Int8 向量的配置(autoindex_param.go 第 117-124 行),不是默认浮点向量的索引。把它当成浮点向量默认值是以讹传讹。
还有一个容易被忽略的细节。adjustAutoIndexParamsByDataType(第 85-120 行)会根据字段实际类型调整 refine_type:fp16 数据强制用 FP16 refine,bf16 数据强制用 BF16 refine。逻辑很朴素——低精度数据没必要用高精度 refine,那是浪费。但正是这种朴素的设计哲学贯穿了整个 AUTOINDEX:帮你选索引结构和构建参数,但不替你决定相似度度量。用户给的 metric_type 不会被覆盖。
第二层:Knowhere 按索引类型补参数
这是最关键的接管层。在 internal/datacoord/index_inspector.go 的 createIndexForSegment(第 237-248 行)和 indexBuildTask.prepareJobRequest 里,有这么一段:
if isVectorIndex && Params.KnowhereConfig.Enable.GetAsBool() {
indexParams, err = Params.KnowhereConfig.UpdateIndexParams(indexType, paramtable.BuildStage, indexParams)
}KnowhereConfig.UpdateIndexParams(knowhere_param.go 第 109-144 行)干了三件事:从配置读取 {indexType}.build.* 的默认参数,比如 DISKANN.build.max_degree;只填充用户没指定的参数——核心判断在 line 113:if GetKeyFromSlice(indexParams, key) == "";支持 override_index_type,如果指定,用目标类型的参数覆盖并替换 index_type。
第二条是整个机制的灵魂。它意味着用户哪怕只写了一句 index_type: DISKANN,系统也会自动补齐 max_degree: 56、pq_code_budget_gb_ratio: 0.125、search_list_size: 100 这些参数。用户不用记一长串配置,但又保留了对每个参数的覆盖权。
有意思的是,configs/milvus.yaml 的 knowhere: 段里只定义了 AISAQ 和 DISKANN 的 build/search 参数,没有 HNSW、HNSW_SQ、GPU_CAGRA。原因是后两者走的是第一层 Proxy 填充(硬编码在 autoindex_param*.go),根本不经过 Knowhere 接管层。Knowhere 配置段只管「用户需要感知磁盘/内存预算」的那类索引。
第三层:特殊索引追加运行时参数
DISKANN 这种磁盘索引有额外的处理。indexparams.UpdateDiskIndexBuildParams(task_index.go 第 247-253 行)会追加磁盘索引特有的参数。更关键的是 GetRuntimeParameter(knowhere_param.go 第 99-107 行)。在 build 阶段,它会注入两个运行时参数:build_dram_budget_gb(当前可用内存)和 vec_field_size_gb(字段实际大小)。这两个值让索引算法能根据真实可用资源做自适应决策。换句话说,DISKANN 在构建时知道「我现在有多少内存可以用」,而不是盲目按配置走。
三层叠加下来,AUTOINDEX 的实质就很清楚了:一套分阶段的默认参数填充管线。每层都只做「填充用户没给的」,不覆盖用户给的。听起来很没技术含量,但这套机制让 AUTOINDEX 既能零配置可用,又能逐参数调优,兼顾了小白和高级用户。
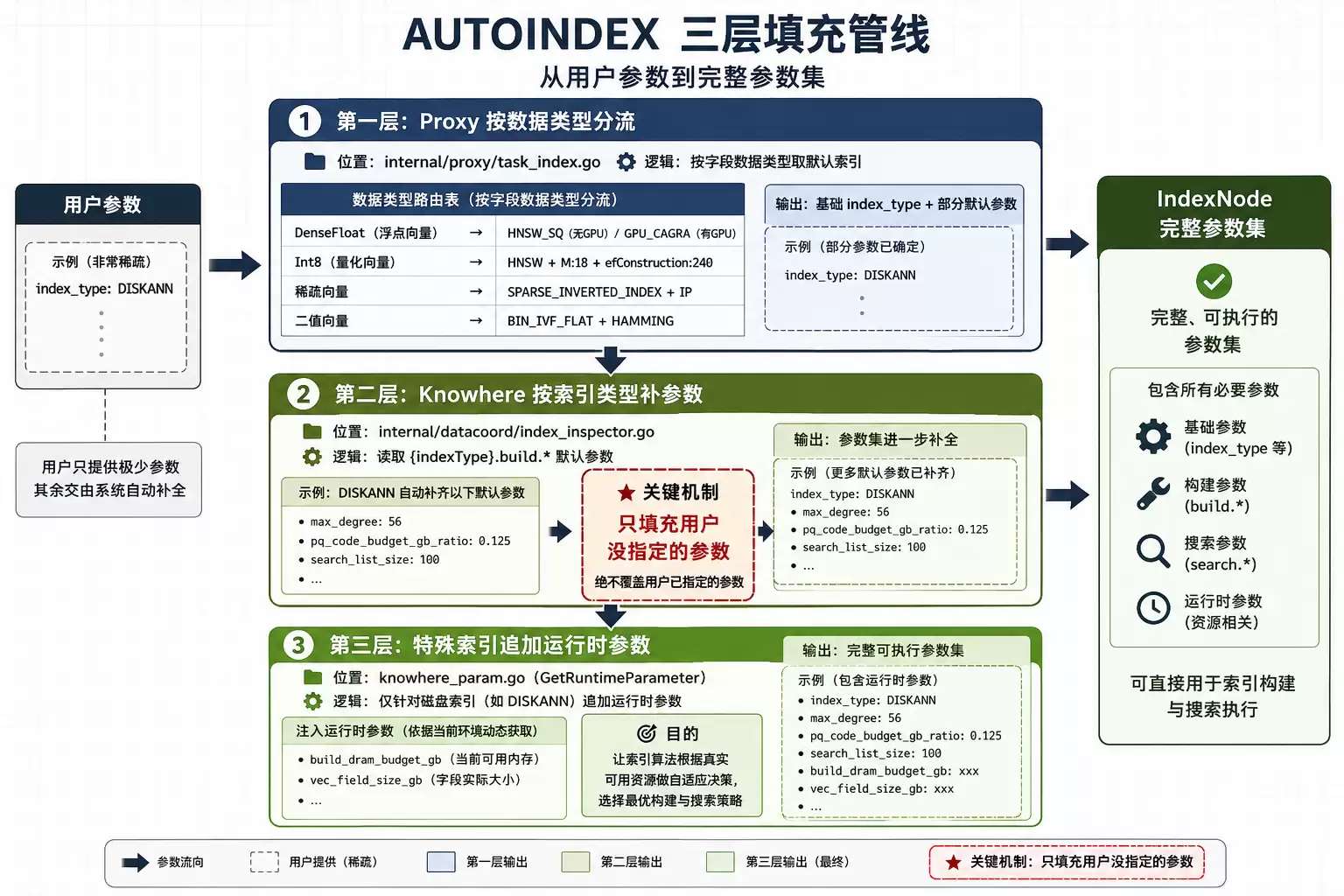 三层填充管线示意
三层填充管线示意
图 2:AUTOINDEX 三层填充管线——从用户参数到 IndexNode 完整参数集的接力
2. CPU/GPU 分流的真相:编译期 Go build tag
回到开头那个让人卡壳的问题:为什么无 GPU 是 HNSW_SQ、有 GPU 是 GPU_CAGRA?答案在两个文件里:
| 文件 | build tag | 默认浮点向量索引 |
|---|---|---|
autoindex_param_nocuda.go | !cuda(默认,无 GPU) | HNSW_SQ SQ4U refine:true refine_type:FP16 |
autoindex_param_cuda.go | cuda(有 GPU) | GPU_CAGRA |
注意是两个不同的 Go 文件,靠 build tag 在编译期决定,不是运行时检测硬件。编译 Milvus 时如果带 cuda tag(通常是 GPU 镜像),就编进去 autoindex_param_cuda.go;不带,就编进去 autoindex_param_nocuda.go。运行时根本没有「检测到 GPU 切换索引」这回事。
这个设计选择背后的逻辑很值得琢磨。无 GPU 场景下内存是瓶颈,所以选了 HNSW_SQ:纯内存图索引 + SQ4U 的 4bit 标量量化,把内存占用压到原来的 1/4,再用 FP16 refine 保证召回率。有 GPU 场景下显存带宽和并行度才是优势,所以选了 GPU_CAGRA——NVIDIA 专门为 GPU 设计的图索引,根本不需要量化压缩,直接吃显存带宽。
两者不是「同一个 HNSW 的变体」,而是面向完全不同的硬件资源模型的两套独立索引。把它们理解成「同一个索引加不加量化」是错的,那个流传的说法本身就是错的。
用 build tag 而不是运行时检测的好处是什么?一是二进制更小(不需要把另一套索引的参数表也编进去),二是行为可预测(不会出现「昨天还好好的今天突然换了索引」这种事)。坏处也很明显——同一个二进制没法同时支持 CPU 和 GPU 部署,要么编 CPU 版要么编 GPU 版。对运维来说,镜像选型要更小心。
3. Knowhere 是什么:C++ 执行引擎,靠 CGO 桥接
搞清楚 AUTOINDEX 后,得回答另一个问题:那些索引算法到底在哪里跑?
答案是 Knowhere。Milvus 的官方设计文档(20211223-knowhere_design.md)对它的定义原话是:核心定位是向量搜索的执行引擎。它用 C++ 写的,把 faiss、hnswlib、NGT、annoy 这些底层索引库统一封装起来,对外暴露 BuildAll/Query/Serialize/Load 这套统一接口。
这就形成了一个很清晰的职责切割:
- Go 控制面(Milvus 的 DataCoord/IndexNode Go 层):任务调度、元数据管理、版本协商、参数填充、存储读写
- C++ 执行面(Knowhere):真正的索引构建、查询、序列化
两层之间靠 CGO 桥接。Go 调 C++ 函数,C++ 把结果返回给 Go。
bit flags:Go 层怎么知道一个索引的特性
CGO 桥接里有一个设计很巧妙的地方。Go 层需要根据索引特性做资源分配决策——这个索引要不要 GPU?能不能 mmap?是不是磁盘索引?——但 Go 层又不能直接读 C++ 索引库的源码。
解决方案在 internal/util/vecindexmgr/vector_index_mgr.go。Go 层通过 CGO 调用 C.GetIndexFeatures(),从 Knowhere 拿到所有支持的索引类型及其特性标志(bit flags):
| Flag | 含义 |
|---|---|
NOTrainFlag | 无需训练(如 FLAT) |
KNNFlag | 精确搜索(100% 召回) |
GpuFlag | 需要 GPU |
MmapFlag | 支持 mmap |
MvFlag | 支持物化视图 |
DiskFlag | 需要磁盘 |
Go 层拿着这些 flag 决定资源策略。IsGPUVecIndex 为真的索引要分配 GPU 资源;IsMMapSupported 为真的可以用 mmap 降低内存。bit flags 是个看起来土但很实用的设计——一个 int 编码所有特性,位运算就能判断,不需要复杂的继承体系。
资源比例:源码里写死的经验值
更「硬核」的设计在 index_attr_cache.go。不同索引的内存/磁盘占用比例,是 Go 层用硬编码常量决定的,不是运行时测量:
- DISKANN:
UsedDiskMemoryRatio = 4(内存 ≈ 索引大小 / 4) - AISAQ:
UsedDiskMemoryRatioAisaq = 64(内存 ≈ 索引大小 / 64) - INVERTED:内存 = 0,全部 mmap 到磁盘
AISAQ 比 DISKANN 少用 16 倍内存,这个 16 倍不是跑测试测出来的,是源码里写死的经验值。这种做法的好处是行为可预测、调度器决策快;坏处是当实际工作负载偏离经验值时(比如数据分布特殊),调度可能不准。但对一个分布式系统来说,可预测性往往比精确性更重要——节点宕机、扩容缩容的决策都依赖这个比例。
4. 版本管理:全取 MIN/MAX 的保守聚合
分布式系统升级是噩梦,索引版本管理是其中的核心难题。Milvus 的解法保守到近乎偏执,但正因如此才支持滚动升级。
三层版本语义
来自 20260313-scalar_index_version_management.md 设计文档:
| 版本 | 含义 |
|---|---|
MinimalIndexVersion | 能 build + search 的最低版本 |
CurrentIndexVersion | 硬编码的默认构建版本 |
MaximumIndexVersion | 能 build + search 的最高版本(非 beta) |
向量索引版本来自 Knowhere C++ 库;标量索引版本由 Milvus Go 层定义(common.go)。
集群级聚合:全部取 MIN 或 MAX
每个 QueryNode 启动时会在 etcd 的 Session 里注册自己支持的版本范围。DataCoord 的 IndexEngineVersionManager 聚合所有节点的版本:
| 方法 | 聚合策略 | 用途 |
|---|---|---|
GetCurrent*Version() | MIN(所有 QN 的 Current) | 所有节点都能加载的最高版本(构建时用) |
GetMinimal*Version() | MAX(所有 QN 的 Minimal) | 任何节点都要求的最低版本 |
GetMaximum*Version() | MIN(所有 QN 的 Maximum) | 所有节点都能处理的最高上限(clamp 用) |
读仔细点。Current 取 MIN,Minimal 取 MAX,Maximum 又取 MIN。这个组合看起来反直觉,但逻辑很自洽——确保滚动升级期间新构建的索引一定能被最旧的节点加载。
举个具体场景。集群里有 3 个 QN:v1(老版本)、v2、v3(新版本)。新版本可能支持索引格式 v5,但 v1 只能读 v3。这时候 CurrentVersion 取 MIN 就是 v3,新建索引只会用 v3 格式,v1 也能加载。等 v1 升级完,CurrentVersion 自然上升到 v5,后续新索引才会用 v5。
这是可用性优先于先进性的工程取舍。代价是升级期间会用一段时间「次优」的索引格式,但换来的是零停机升级。
Resolve 方法:target 覆盖 + clamp
ResolveVecIndexVersion(line 298-330)的简化逻辑:
version := current
if target != -1 {
if forceRebuild {
version = target // 强制重建到指定版本
} else {
version = max(version, target) // 取集群值和目标值的较大者
}
}
return clampVersion(version, minimal, maximum, "targetVecIndexVersion")三个配置参数的语义:
targetVecIndexVersion:临时灵活覆盖(-1 = 不激活)forceRebuildSegmentIndex:紧急措施,强制重建到指定版本(连已构建的也重建)autoUpgradeSegmentIndex:滚动升级后自动升级旧索引
设计文档还专门处理了「老 QN 不报告 MaximumIndexVersion」的情况——GetMaximumIndexEngineVersion 跳过零值条目(line 147),如果所有 QN 都是老的,返回 math.MaxInt32(不做上限检查)。Session JSON 加字段的兼容性靠 Go 的 encoding/json:忽略未知字段、缺失字段反序列化为零值——双向兼容。
这套版本管理在 2026 年 3 月的 MEP 里被对称化到了标量索引上(新增 TargetScalarIndexVersion 和 ForceRebuildScalarSegmentIndex)。说明向量索引的版本管理是一套验证过的成熟模式,标量索引在向它对齐。
5. 标量 V3 格式:通用性 vs 列式优化的取舍
聊完向量索引,顺带说说标量索引的格式演进。Scalar Index V3 格式(20260209-scalar-index-unified-format.md)的核心目标是:单文件打包 + 并发 + 低内存 + 加密透明。
文件布局:尾定位
V3 的文件长这样:
[Magic "MVSIDXV3"] [Data Region] [Directory Table JSON] [Footer 32B]从文件尾部 32 字节的 Footer 可以定位 Directory Table 和 Meta Entry,1-2 次 IO 就能获取全部元数据。这是个很务实的设计——远程存储(S3)按请求计费,少一次 IO 就少一份成本。
设计取舍:为什么不学 Lance
设计文档第 9.1 节明确对比了 Lance 格式。Lance 用列式存储编码索引,但有个绕不开的问题:任意图结构、树节点、哈希表必须展平成列,有编码/填充开销。V3 选择了另一条路——纯 KV 风格(key → 序列化 blob + metadata)。代价是牺牲了列式优化(不能只读某一列),换来的是对异构索引类型的最大兼容性。BITMAP、STL_SORT、INVERTED 这些完全不同结构的索引,都能塞进同一个文件格式。
这是个典型的工程取舍。向量数据库的标量索引不是为了做 OLAP 分析,更多是为了过滤和点查,列式优化的收益没那么大;但标量索引类型多、演进快(光是 2026 年就加了 JSON Path 多类型索引),用一个统一格式接住所有变体,比每个索引类型单独设计格式省心得多。
加密边界:Slice 而非 Entry
V3 还有个细节:加密边界是 Slice,不是 Entry。加密时每个 entry 切成 16MB slice 独立加密;不加密时 entry 是连续明文。这导致了两套写入路径:
- 不加密 →
IndexEntryDirectStreamWriter:直接写 RemoteOutputStream,后台并行上传 S3 - 加密 →
IndexEntryEncryptedLocalWriter:先写本地临时文件(密文大小不可预测),再上传
为什么要分两套?因为加密后的密文大小不可预测,不能边算边直接流式上传到 S3。这种「为了一个特性牺牲一部分性能」的取舍(多一次本地写),在工程上很常见。
版本路由:不读 Magic
V3 还做了个反直觉的设计——不通过读文件 Magic 来判断版本。版本路由完全在调用方:
- 构建侧:
ScalarIndexCreator::Upload()检查SCALAR_INDEX_ENGINE_VERSION配置 - 加载侧:
SealedIndexTranslator检查配置 - Go 控制面:
CurrentScalarIndexEngineVersion常量控制
为什么不读 Magic?避免「加载时才发现版本不对」的问题——版本在构建时就确定了,并在元数据里记录。Magic 还是会写(用于校验),但不参与版本决策。这是把「防御式检查」和「版本路由」解耦的干净做法。
6. AISAQ:DISKANN 在三角上的新坐标
最后聊聊 AISAQ,它是 2026 年 6 月新加进来的索引(knowhere v3.0.4,beta 2.6.4)。看官方文档(aisaq.md)的描述,AISAQ 是 DISKANN 的扩展,主打 Near-Zero DRAM。
DISKANN 已经是磁盘索引了,AISAQ 还要更进一步压内存。两条路线的对比:
| 模式 | PQ 数据位置 | 单节点访问 I/O | 磁盘占用 |
|---|---|---|---|
| DISKANN | 内存(DRAM) | 1 次(raw vector + edgelist) | 中等 |
| AISAQ-Performance | 磁盘(inline,冗余存储邻居 PQ) | 1 次(raw + edgelist + 邻居 PQ) | 大(冗余) |
| AISAQ-Scale | 磁盘(分离存储,rearrange 优化) | 小 |
这是个内存占用 vs IOPS vs 磁盘占用的三角权衡。DISKANN 把 PQ 放内存,省 IOPS 但吃内存;AISAQ-Performance 把 PQ 挪到磁盘,省内存但磁盘占用变大(冗余存储邻居 PQ);AISAQ-Scale 进一步优化存储布局,磁盘占用小但 IOPS 变多。
回到前面那个源码常量,DISKANN 的 UsedDiskMemoryRatio = 4,AISAQ 是 64——内存占用差 16 倍。AISAQ 的存在回答了一个问题:当数据规模超过 DRAM 容量时,用磁盘 IOPS 换 DRAM 是值得的。10 亿向量级别,DISKANN 可能要几十 GB 内存,AISAQ 只要 1-2 GB 就能跑起来。
这也是为什么 knowhere: 配置段里同时定义了 AISAQ 和 DISKANN 的参数——它们都是磁盘索引家族,但定位在光谱的不同位置。
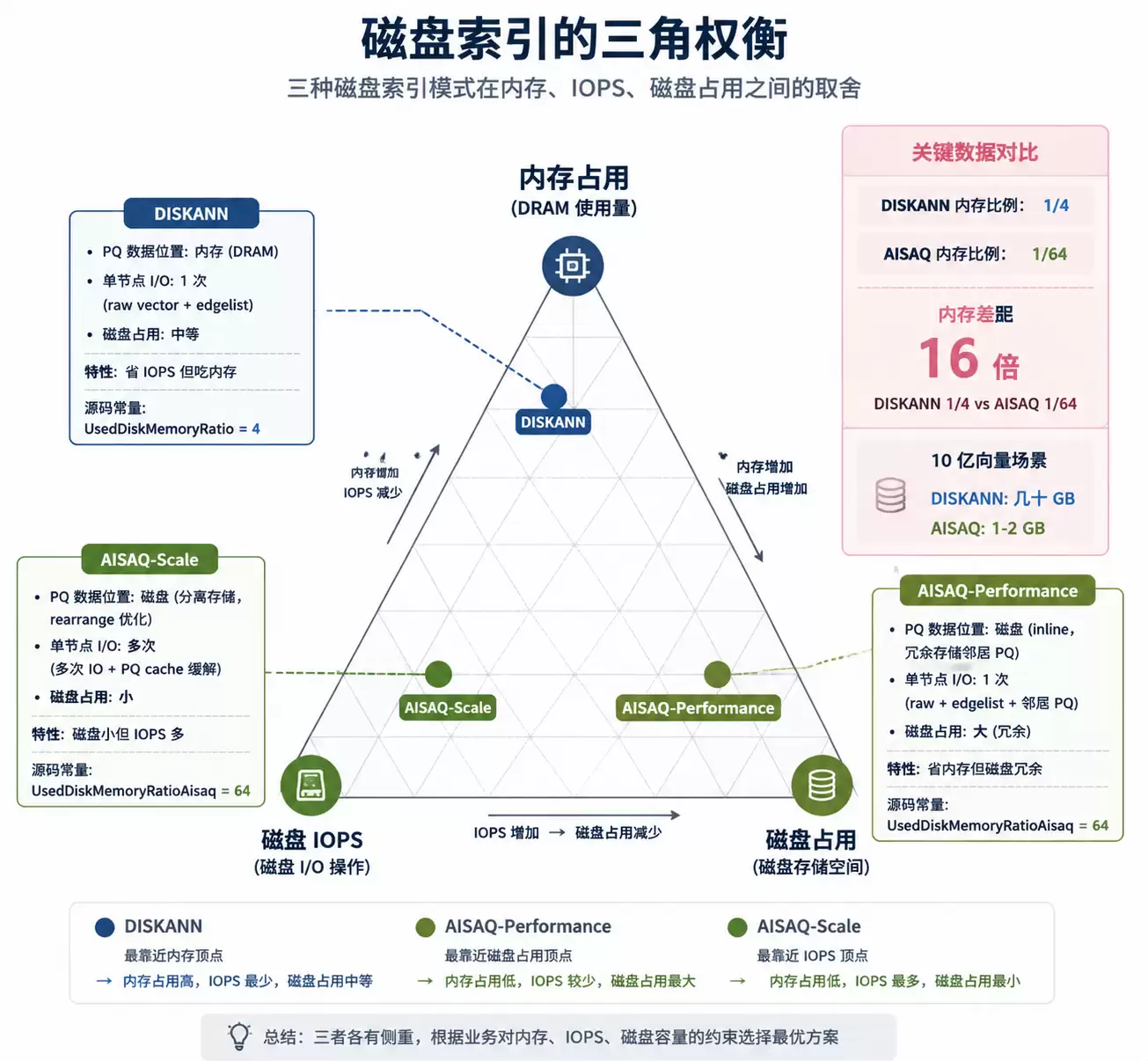 DISKANN / AISAQ 在内存-IOPS-磁盘三角上的坐标
DISKANN / AISAQ 在内存-IOPS-磁盘三角上的坐标
图 3:DISKANN、AISAQ-Performance、AISAQ-Scale 在内存-IOPS-磁盘三角上的不同坐标
7. 「索引」在 Milvus 是三类技术栈的统称
写到这儿,一个被广泛误解的概念该澄清了。在 Milvus 里,「索引」不是一个东西,而是至少三类独立技术栈的统称。
向量索引
图(HNSW 系列)、聚类(IVF 系列)、量化(SQ/PQ/RABITQ)——这是大家最熟悉的那类。技术栈来自 faiss、hnswlib、NGT、annoy,由 Knowhere 统一封装。
标量索引
排序(STL_SORT)、位图(BITMAP)、倒排(INVERTED,基于 Tantivy)。标量 AUTOINDEX 按数据类型路由:int/varchar/float/json 默认 HYBRID(构建时按基数自动选 BITMAP 或 STL_SORT),bool 用 BITMAP,geometry 用 RTREE。
基数阈值 BitmapCardinalityLimit = 100 写在源码里——不同值数量 ≤ 100 用 BITMAP,否则用排序索引。HYBRID 是「用户不知道数据分布时的安全默认」。
主键索引
这个最容易被忽略。主键索引用 BBhash(最小完美哈希)+ Value Array,跟向量索引和标量索引完全不是一套技术栈。来自 20250429-primarykey_index.md 设计文档。
它的目标是跨 segment 的 PK 快速定位(去重、点查、删除转发优化)。文档给的对比数据:PK 索引查询 ~200ns/次,10-20M QPS/节点;10000 个 Bloom Filter ~0.1ms/次,~1000 QPS/节点。差距大概 500 倍。内存效率也高:BBhash 2-4 bits/key + Value Array 4 bytes/key ≈ 4.5 bytes/key,10 亿 key ≈ 4.5GB。
三类索引各有独立的算法、格式、版本管理、演进节奏。向量索引在向量化召回上发力,标量索引在过滤和点查上发力,主键索引在精确去重上发力。把「索引」理解成单一概念是错的,理解成三类技术栈的统称,很多设计决策才说得通——比如为什么标量 V3 格式要独立设计,为什么标量索引的版本管理要单独做对称化。
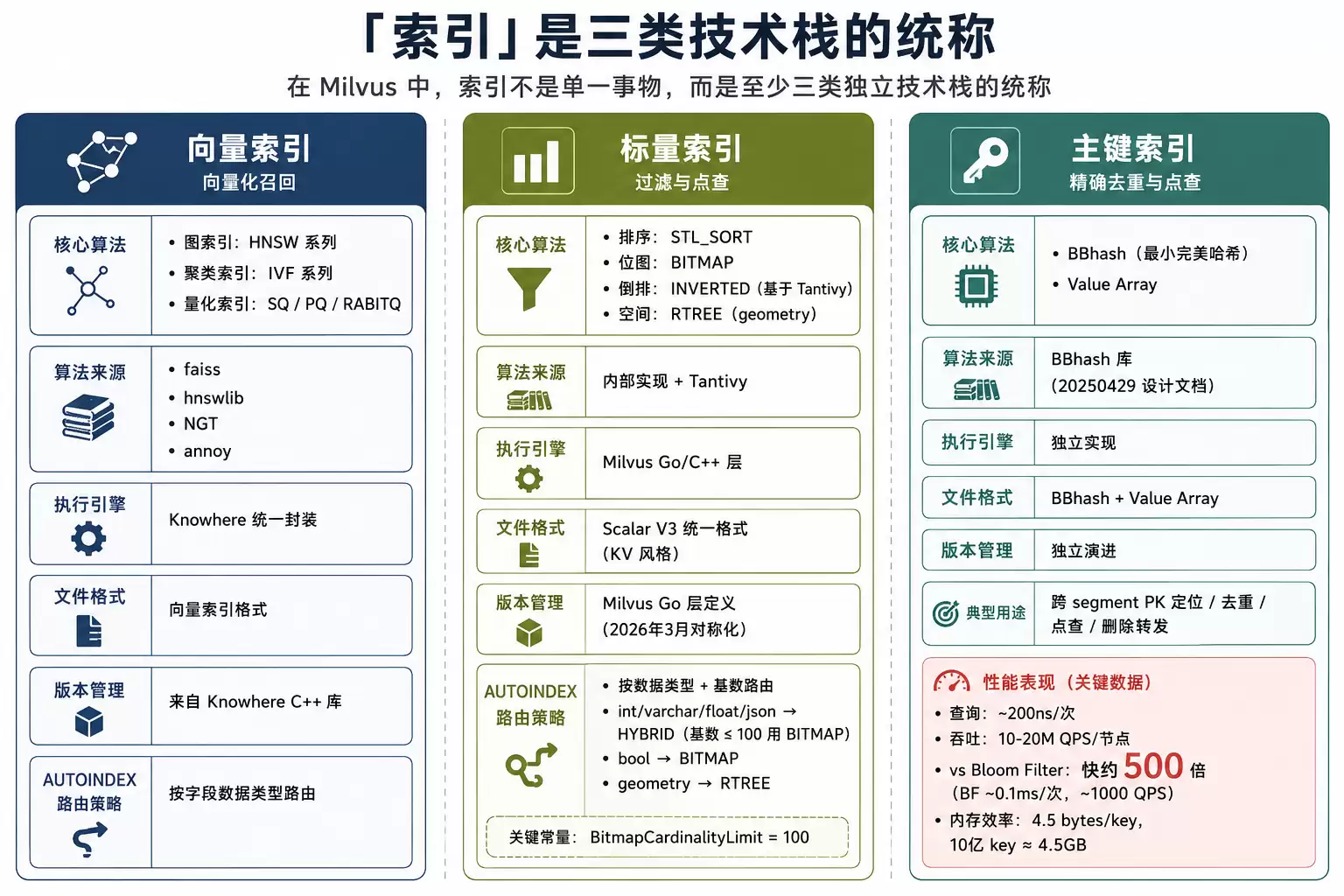 三类索引技术栈的边界
三类索引技术栈的边界
图 4:向量索引、标量索引、主键索引三类技术栈的边界
写在最后
把这篇拆的东西归拢一下:
- AUTOINDEX 是三层填充管线,不是智能算法。Proxy 分流、Knowhere 补参、特殊索引追加运行时参数,每层只填用户没给的。
- CPU/GPU 分流在编译期决定,靠 Go build tag 选
HNSW_SQ或GPU_CAGRA。运行时没检测。 - Knowhere 是 C++ 执行引擎,Milvus 是 Go 控制面,CGO 桥接,bit flags 编码索引特性,资源比例是源码里写死的经验值。
- 版本管理全取 MIN/MAX,保守到偏执,但支持滚动升级。这套模式正被标量索引对齐。
- 标量 V3 格式选了通用性,牺牲列式优化换取对异构索引类型的兼容。
- AISAQ 是 DISKANN 的新坐标,用磁盘 IOPS 换 DRAM,适配超大规模数据集。
- 「索引」是三类技术栈的统称:向量索引、标量索引、主键索引,各有独立演进。
有意思的是,Milvus 团队做的几个核心取舍都偏保守:build tag 编译期分流、版本 MIN/MAX 聚合、硬编码资源比例、KV 风格的标量格式。这些选择单独看都不「先进」,但放在一起构成了一个可预测、可滚动升级、行为稳定的系统。对一个分布式数据库来说,这比花哨更重要。
写完这一篇,查询加速这条线(索引引擎)就大致覆盖完了。跟前面两篇数据隔离(多租户)、数据维护(Compaction)合在一起,Milvus 的核心子系统也算是有了一个相对完整的源码级视角。后续如果再挖,可能会去聊聊 WAL 消息链或者 Segment 加载策略,看精力。
相关资源
- Milvus 官方仓库:https://github.com/milvus-io/milvus
- Knowhere 引擎仓库:https://github.com/zilliztech/knowhere
- Milvus 设计文档(RFC):https://github.com/milvus-io/milvus/tree/master/docs/developer_guide/milvus_enhancement_proposals
- AISAQ 索引文档:https://milvus.io/docs/aisaq.md




