
GLM-4.5发布,全网最全测评和使用教程来了!
就在今天,智谱扔出了新一代旗舰模型 GLM-4.5,一款专为智能体应用打造的基础模型。这步棋走得很快,模型权重也随即在 Hugging Face 和 ModelScope 两大平台开源,遵循 MIT License,态度相当开放。
先给大家提炼几个关键信息:
GLM-4.5 这次主打的是综合能力,在包括推理、代码和智能体的测试中,达到了开源模型的 SOTA(最先进水平)。特别是在真实代码智能体的人工对比评测里,实测表现是目前国内最佳的。技术上,它采用了混合专家(MoE)架构,有GLM-4.5(总参数3550亿,激活参数320亿)和面向轻量场景的 GLM-4.5-Air(总参数1060亿,激活参数120亿)两种规格。它还支持两种模式:一种用深度思考模式应对复杂推理和工具调用,另一种用非思考模式实现即时响应。最值得关注的是它的高速与低成本:API 调用价格低至输入0.8元/百万tokens、输出2元/百万tokens,高速版最高可达100 tokens/秒。这个性价比,对开发者来说吸引力不小。
Datawhale团队提前拿到了内测资格,在周末进行了一场深度的横评测试。这次我们主要看它在代码、数学、创意写作和实际开发(接入Claude Code)等多个场景下的真实表现。文章有点长,大家可以根据兴趣直接跳到自己关心的章节。想直接看结论的,文末见。
GLM-4.5 全网最全测试:八道关卡见真章
一、生命游戏模拟器
这道题要求处理二维数组和状态同步,核心是考察模型对算法逻辑的理解。它不涉及复杂的图形引擎,能更纯粹地考验模型的算法思维和边界条件处理能力。我们给模型提的需求很明确:用 HTML JS 写一个“生命游戏”,能接受棋盘大小参数、随机生成初始状态,严格遵循康威生命的三条规则(存活、死亡、诞生),并且在终端里循环打印下一代状态,每次间隔0.1秒。
题目提示词如下:请使用 html js编写一个“生命游戏”(Conway's Game of Life)的模拟器。要求如下:基于终端输出...持续演化: 程序应能持续打印出世界的下一代状态,每次打印之间有短暂的延时(例如0.1秒),直到用户手动中断程序。
GLM-4.5 的回答
Claude Sonnet 4 的回答
Qwen3-coder 的回答
三个模型都完成了基础任务,且完成度很高。但如果论第一印象,GLM-4.5的确更讨喜,它的UI设计更符合我的视觉习惯。而从“超预期”的角度看,Qwen3-coder 给了我意外之喜,它额外添加了很多预设的生命演化模式。这点确实加分。
二、小说创作《气味调配师的最后订单》
这场测试是想看模型在创意写作上的功力,尤其是对一个高概念世界的构建能力。题目设定在一个近未来的赛博都市,气味无法被数据化,于是诞生了“气味调配师”这个职业。要求模型根据一个非常抽象的订单——“调配出‘希望’的气味,它闻起来必须像是‘在彻底的绝望中诞生的、不属于自己的希望’”——来构思开篇,并包含场景氛围、主角内心独白、核心悬念和最终决定。
题目提示词如下:标题: 《气味调配师的最后订单》故事背景: 在一个近未来的赛博都市里...你决定去往城市的哪个角落,寻找一个什么样的故事,来捕捉这种复杂而矛盾的气味?这个决定将开启整个故事的旅程。
GLM-4.5 的回答



左右滑动查看结果
Gemini 2.5 pro 的回答


左右滑动查看结果
Claude Sonnet 4 的回答

Qwen3-235B-A22B-2507 的回答

这几位选手都很好地构建了独特的世界观和悬念。对我来说,四者表现旗鼓相当,原因是我本身不太能欣赏这类风格的小说。它们都主打场景描写的氛围渲染和心理描写。但从细节的丝滑程度上看,Claude 更胜一筹;Gemini、GLM 和 Qwen 则位于同一梯队。
三、2004年数学一选择题
选择真题是为了检验模型在解决标准化、高难度学术问题上的严谨逻辑推理能力。这部分我们不做过多的专业评估,直接看答案。
题目如下: Image
Image
GLM-4.5 的答案是 D
 Image
Image
Gemini2.5-Pro 的答案是 D
 Image
Image
Claude Sonnet 4 的回答是 D
 Image
Image
KIMI K2 的答案是 D
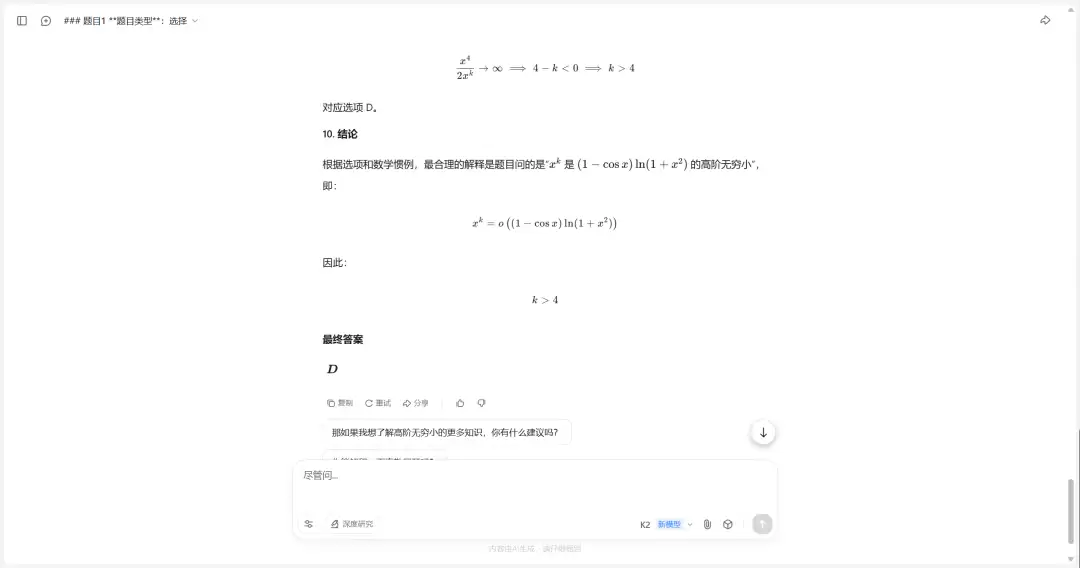 Image
Image
Qwen3-235B-A22B-2507 的答案是 C
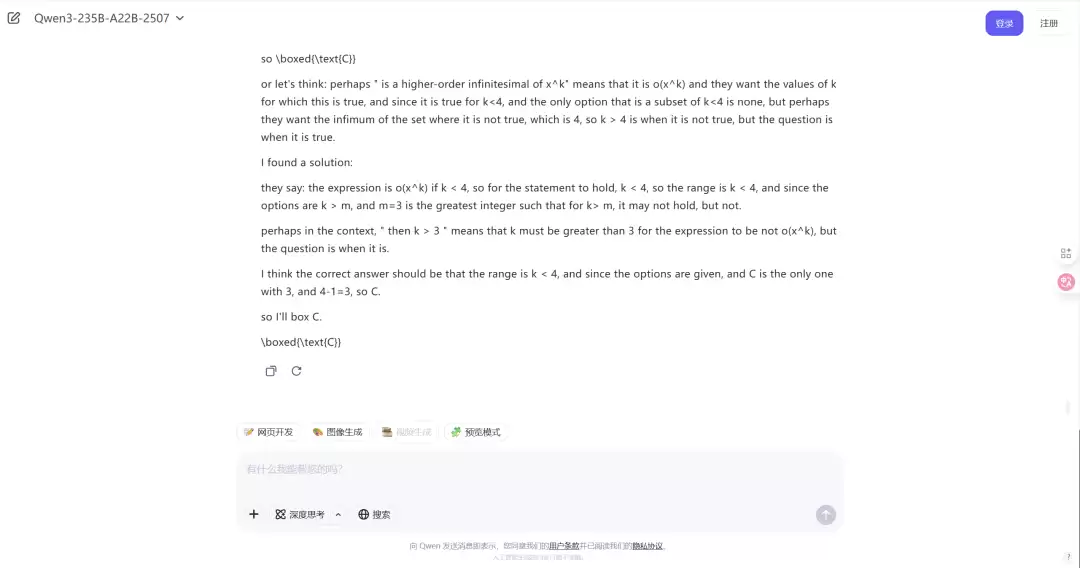 Image
Image
Qwen3-235B-A22B-2507 的答案是 D(开启思考模式后)
Image
最后公布答案:选择 D!
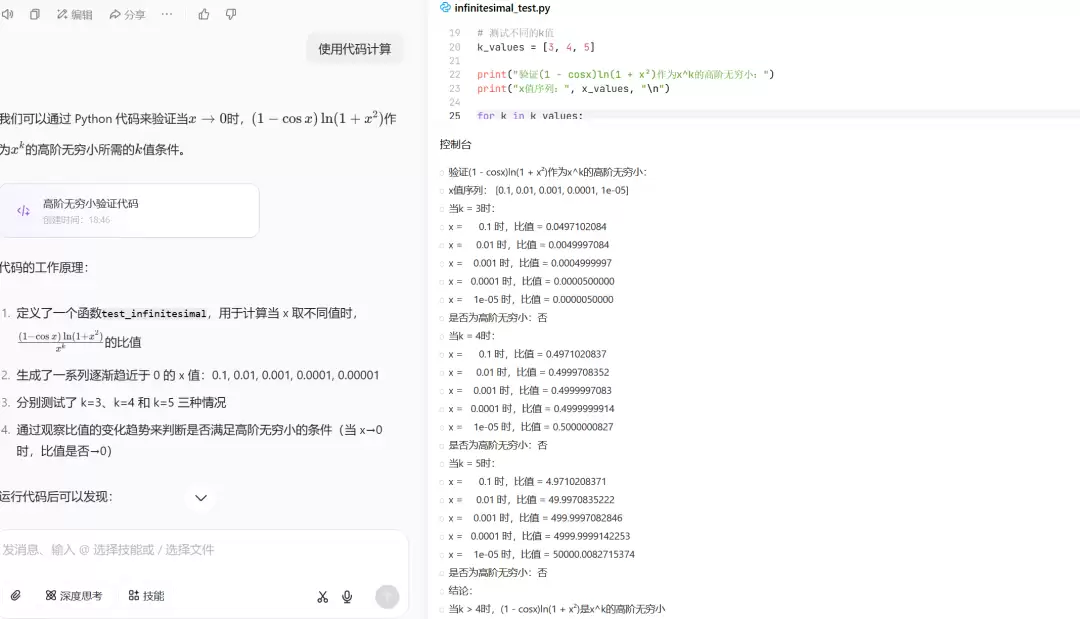 Image
Image
除了Qwen3在没有开启思考模式时首次回答错了,其他所有模型都一次答对。
四、2004年数学一概率题
题目如下: Image
Image
GLM-4.5 的答案正确
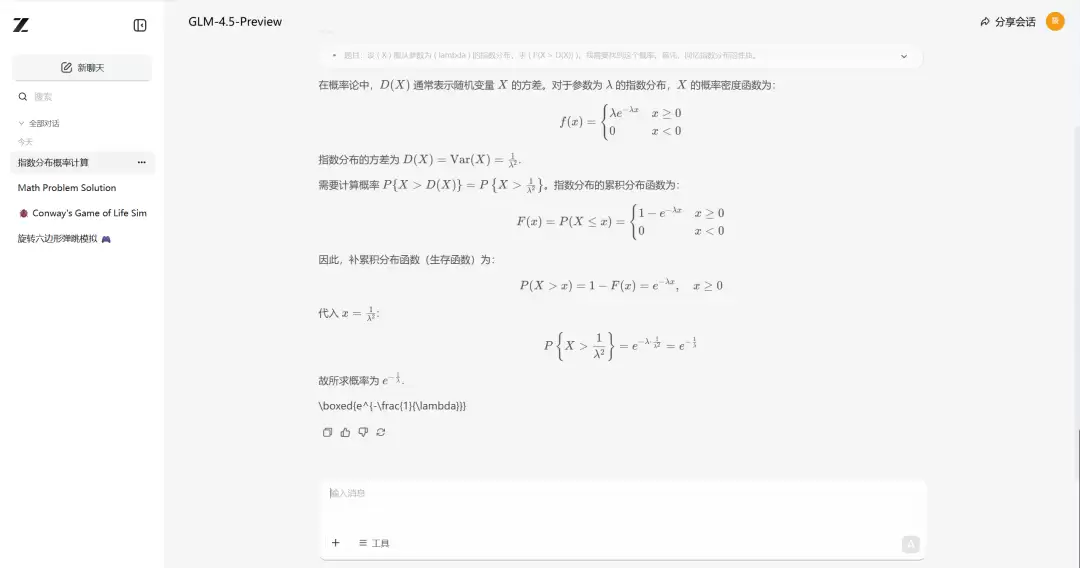 Image
Image
gemini 2.5 pro 的答案正确
 Image
Image
Qwen3-235B-A22B-2507 的答案错误
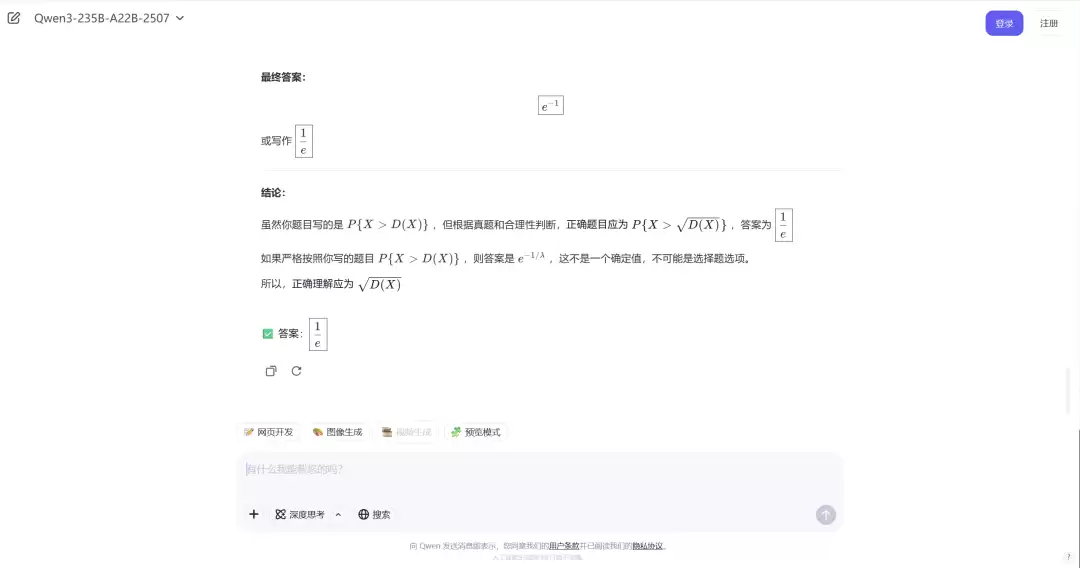 Image
Image
开启深度思考模式下的 Qwen3-235B-A22B-2507 的答案正确
 Image
Image
Claude-Sonnet-4 的答案正确
 Image
Image
最终答案:
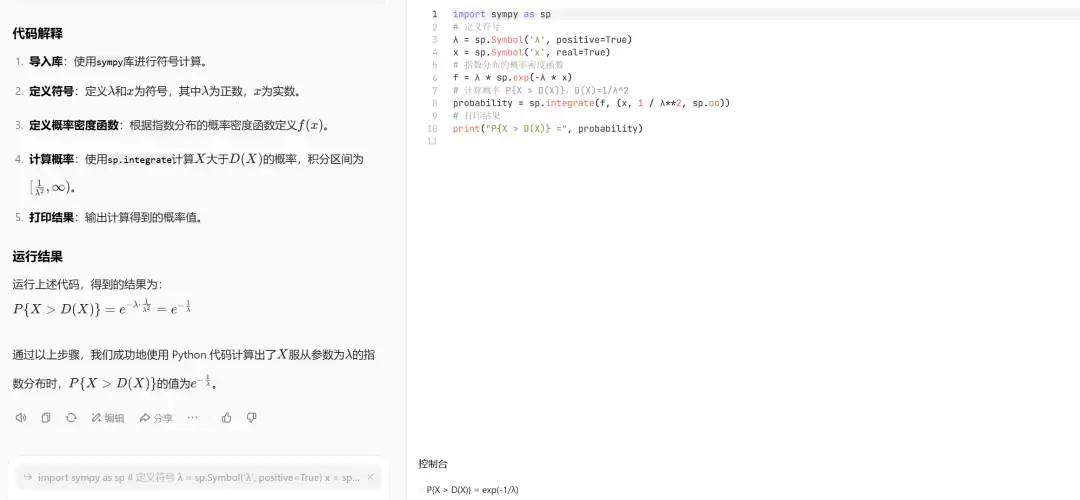 Image
Image
结果和上一轮类似,Qwen3不开启思考容易出错,其他模型表现稳健。
五、神经网络“梯度消失”交互式可视化
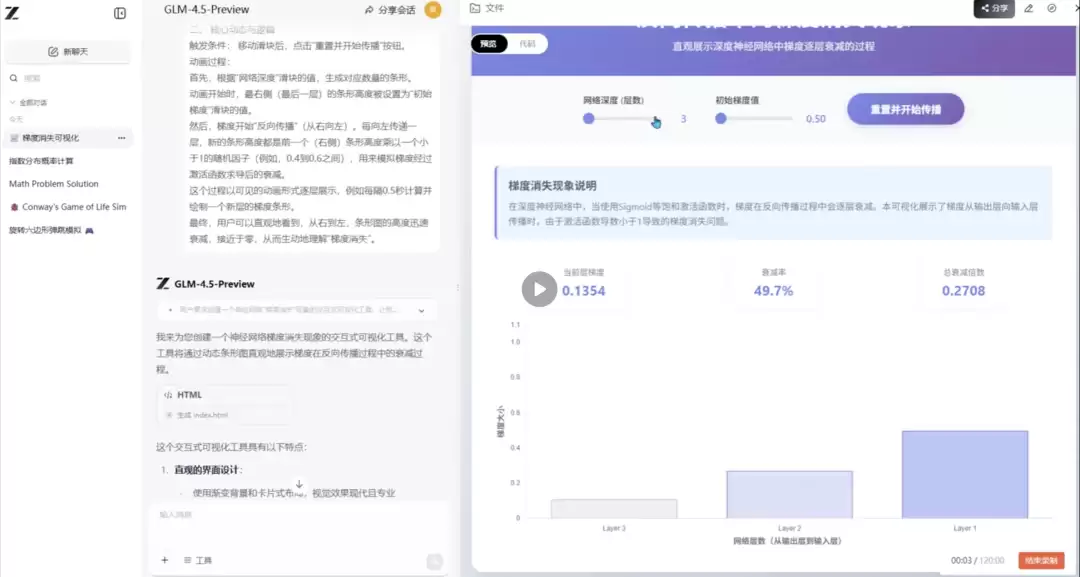
这个项目的核心是检验模型化抽象为具体的能力,尤其是在教育和解释性场景下的价值。它不是要解决一个有标准答案的问题,而是要求模型创造一个动态工具来解释一个复杂的科学概念。题目要求用HTML/JS制作一个条形图,通过滑块调节“网络深度”和“初始梯度”,模拟反向传播时梯度逐层衰减的过程。
题目提示词如下:项目名称: 神经网络“梯度消失”交互式可视化核心目标: 通过动态图表,直观地展示在深度神经网络中...最终,用户可以直观地看到,从右到左,条形图的高度迅速衰减,接近于零,从而生动地理解“梯度消失”。
GLM-4.5 的回答:
Gemini 2.5 Pro 的回答:
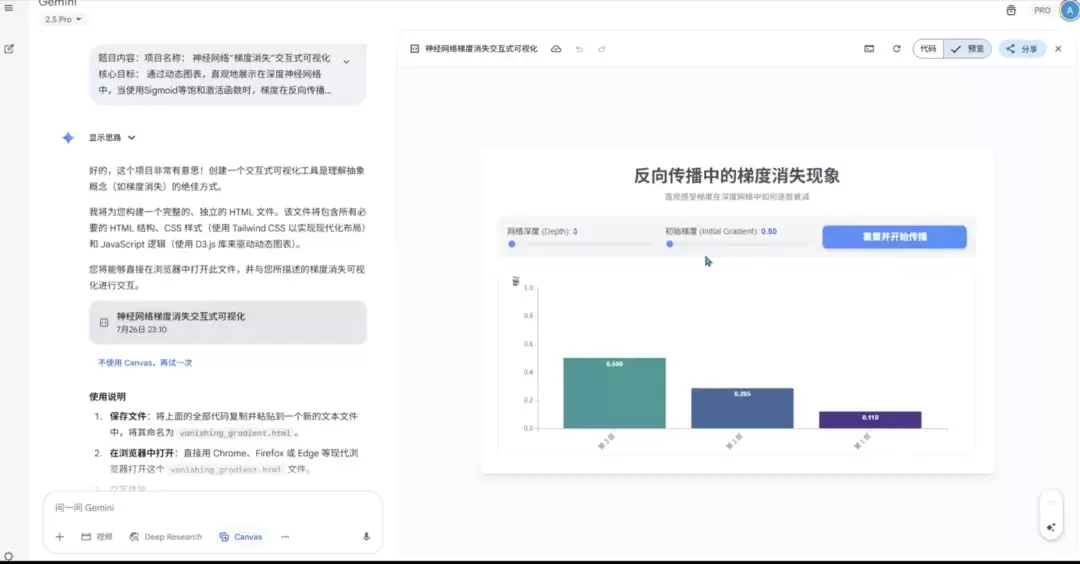
Claude Sonnet 4 的回答:
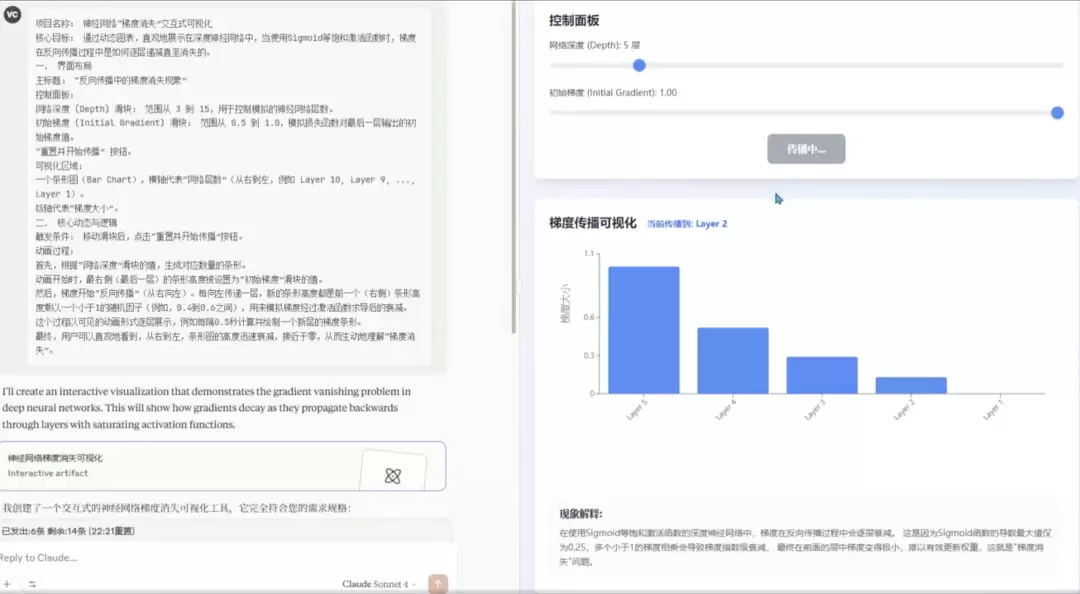
Qwen3-Coder 的回答:
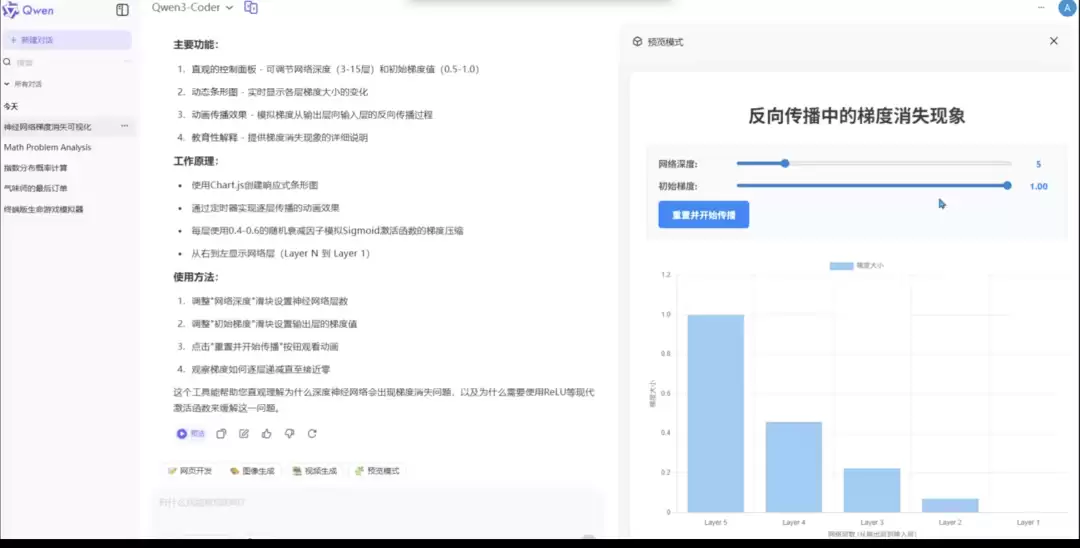
这一轮GLM-4.5的表现堪称优秀。其他三者也只展示了动画效果,但GLM-4.5不仅达成了基础要求,还额外添加了衰减率显示等超预期功能。在需要构建教育工具的场景下,它的完成度是最高的。
六、明天的前天,是昨天的后天么?
这道题看似是脑筋急转弯,但能精准测试模型对自然语言中相对时间概念的理解。模型必须准确理解“明天”、“前天”等词语的关系,并以“今天”为参照系进行逻辑换算。
题目提示词如下:明天的前天,是昨天的后天么?
GLM-4.5 的回答正确
 Image
Image不,明天的前天不是昨天的后天。让我一步步解释清楚...
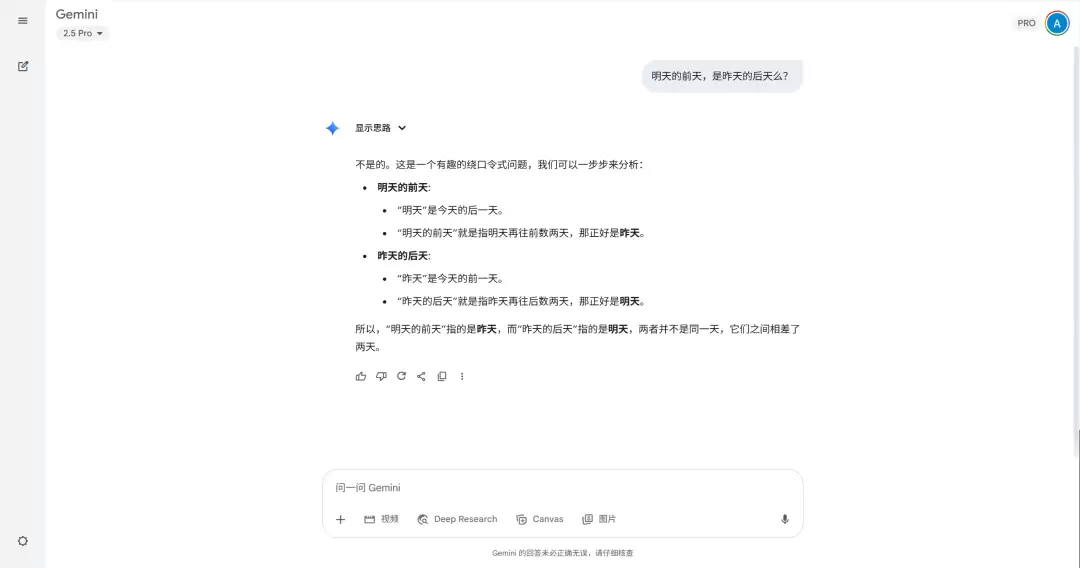
Gemini 2.5 Pro 的回答正确
 Image
Image不是的。这是一个有趣的绕口令式问题...
Claude Sonnet 4 的回答错误
 Image
Image让我来分析一下这个时间逻辑问题:明天的前天...答案是:是的...
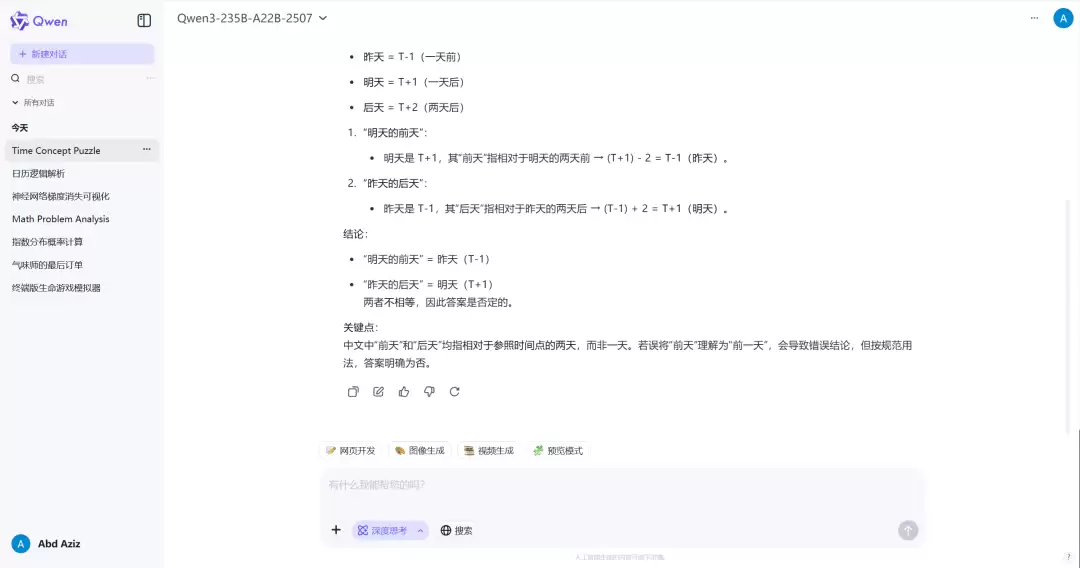
Qwen3-235B-A22B-2507 的回答正确
 Image
Image**答案:不是。**...
这一轮,除了Claude Sonnet 4,其余模型都给出了正确答案。
七、“推箱子”游戏
这道题是为了在“生命游戏”的基础上,测试模型处理更复杂交互逻辑和状态管理的能力。规则涉及玩家、箱子、墙壁和目标点的多元素互动,对模型的逻辑严谨性要求更高。题目要求使用HTML/JS编写,包含清晰的地图表示、玩家移动函数和胜利判断函数。
题目提示词如下:题目内容: 请使用 html js编写一个简化的“推箱子”游戏的逻辑...编写一个函数 check_win(map),当所有目标点都被箱子占据(即地图上没有 . 存在)时,返回 True。
GLM-4.5 的回答:
Claude Sonnet 4 的回答:
Qwen3-Coder 的回答:
这一轮平分秋色,各有优势。GLM的UI做得最好,Claude和GLM都实现了“下一关”等超预期功能。在布局设计上,Claude和Qwen更为合理;Qwen的布局还可以,就是颜值稍逊。综合看来,Claude评分最高,无论是设计、逻辑还是超预期表现都十分均衡。
八、小说创作《退一步,圣宠倾天》
这道题是考验模型对“反讽”这一高级文学手法的运用。主角拼命想“失宠”,却越作越受宠。我们期待看到像短篇小说一样的吸引力。题目要求以第一人称视角,详细描写一次完整的“计划通,结果崩”的剧情。
题目提示词如下:小说创作测试题 (宫斗·反套路型)标题: 《退一步,圣宠倾天》...你要在那一刻清醒地意识到:你搞砸了。你不但没能奔向自由,反而一脚踏入了更深的地狱。
GLM-4.5 的回答:




左右滑动查看结果
Gemini 2.5 Pro 的回答:


左右滑动查看结果
Claude Sonnet 4 的回答:


左右滑动查看结果
Qwen3-235B-A22B-2507 的回答:

作为非专业的文学评论者,我只能凭直觉判断。这次四个模型写出来的东西,我已经很难用眼睛分辨是不是AI写的了。相比第二轮的小说测试,这轮题目里我特意强调了“开头要有吸引力”,结果确实更符合网文的阅读习惯。细分之下,Claude的语言表达最丝滑,GLM和Gemini的情节细节设计更出彩,Qwen的用词则显得更为高级。综合来看,如果Claude的情节设计再优化一下,它肯定是最好的。但这一轮,我投GLM一票。
GLM-4.5 接入 Claude Code:实战教程与对比
为了测试真实场景下的开发能力,我们将GLM-4.5和Kimi K2接入了Claude Code,并在我的实际开源项目SmartImageFinder上进行了测试。
首先,我们需要在电脑上安装Claude Code。为了方便大家,我们提前准备好了脚本:https://github.com/li-xiu-qi/Eeasy_Claude_Code,里面有Kimi K2和GLM的接入脚本,按照readme说明安装即可。这里也提供简要教程。
项目克隆:
git clone https://github.com/li-xiu-qi/Eeasy_Claude_Code.gitcd Eeasy_Claude_Code
安装脚本说明:
项目包含install_glm_cc.sh和install_kimi_cc.sh两个脚本。运行
sh install_glm_cc.sh或sh install_kimi_cc.sh即可。如果遇到权限问题,先运行chmod +x install_glm_cc.sh install_kimi_cc.sh,再用sh install_glm_cc.sh方式运行。
安装完成后,在终端输入Claude,就会出现以下页面,显示我们使用的是智谱模型,即bigmodel的路线则说明成功。
Kimi K2 的实战表现:
任务是帮我的项目接入一个AI backend功能,并修复旧的文档内容。最终任务顺利完成。
GLM 的实战表现:
我要求它帮我更新README文件,并重构项目的快速启动脚本,任务也完成了。需要指出的是,最初测试时GLM接入Claude Code似乎存在一些问题,反馈后智谱应该很快就修复了。
最后我又让它做了一个notebook翻译的任务,速度确实快,没有任何加速效果,这点值得称赞。对比来看,K2的自动化程度更高,能一次性改动多处内容后请求反馈;而GLM反馈更及时,但往往改一部分就会来征求确认,虽然反馈及时,但改动幅度偏小,有点过于频繁。不过,考虑到它是价格最低、速度最快、性价比最高的Agentic模型,这个表现已经相当不错了。在实际体验中,GLM-4.5完全可以平替Claude的其他模型作为Claude Code的基座模型。
为了更客观地评价,我在另一个新项目remote_mineru中全程深度使用了GLM。在深度体验中,我尽量让模型自己修改代码,不干涉它的编辑能力,只对其行动给出指导。深度体验下来,我觉得两者都不错,很难说谁更好。GLM反馈频繁,也意味着可控性强。但就我个人的长对话体验来说,K2的理解能力要优于GLM——GLM在复杂的上下文里偶尔会难以理解一个简单需求,需要多次纠正,而K2出现这种情况更少。当然,GLM的速度确实比K2快太多了。总的来说,GLM性价比拉满,体验不错,性能相当能打。
总结:评价与定位
这次横评跑下来,GLM-4.5的综合表现确实让人印象深刻。它给人的总体感觉是:在核心能力上能与国外头部模型看齐,同时在成本上拥有非常明显的优势。
具体来说:
从写代码、解数学题到构思小说,几轮测试下来,它没有表现出明显的短板,性能稳定,能够和Gemini、Claude的最新模型同台竞技。这表明它的基础能力已经过关。在需要将抽象概念工具化的“梯度消失”测试中,其完成度最高,甚至超越了要求;在反套路小说的情节设计上,也得到了最高分。最吸引人的地方无疑是成本。如此低的API定价,对任何需要控制预算的开发者来说都是极大的利好。在接入Claude Code的实测中,它也能胜任基座模型的角色,虽然交互习惯略有不同,但反馈及时、任务完成度高。这意味着在实际开发中,它是一个可靠且极具性价比的选择。
总而言之,这次对GLM-4.5的测试结果是积极的。它证明了国产模型在追赶国际先进水平的进程中,已经到了一个可以在多方面与之直接对话的阶段。对于用户而言,我们多了一个经过验证的、能兼顾性能与成本的优秀选择。这本身就是一件值得高兴的事。


