
梁文锋署名论文,DeepSeek首轮融资后大动作:生成速度大涨85%
DeepSeek在完成500亿元融资后,放出了开源的新动作。今天,它正式公布了一套工程方案,目标很直接——让现有模型跑得更快。
这次开源的内容包括两款模型:
DeepSeek-V4-Pro-DSpark
DeepSeek-V4-Flash-DSpark
推测解码框架DSpark
训练框架DeepSpec
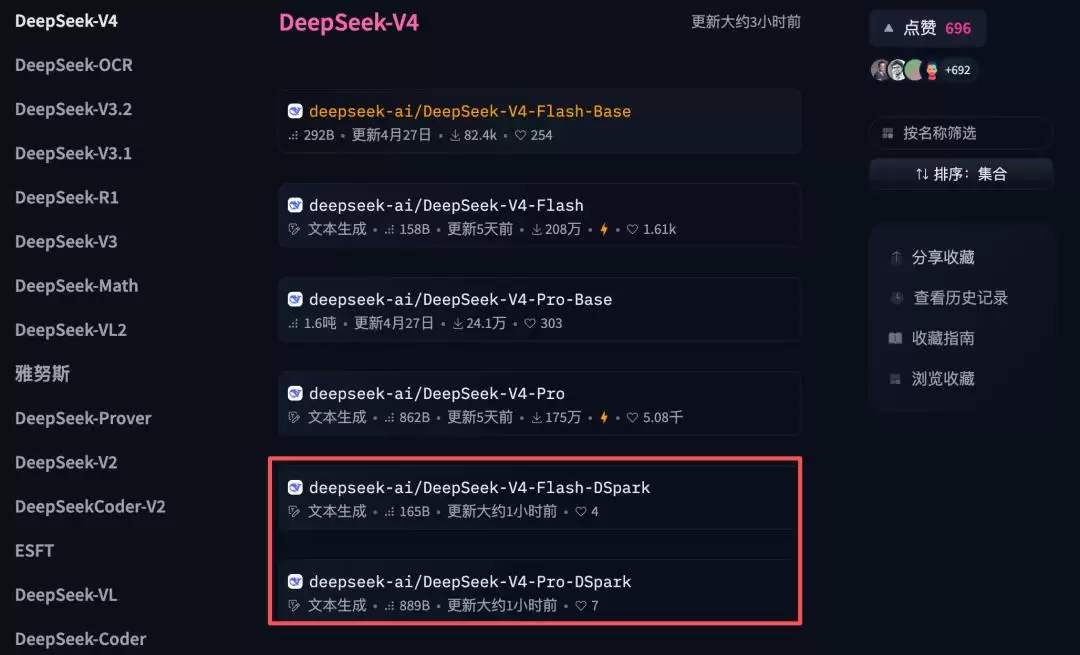
▲DeepSeek-V4-Pro-DSpark开源上新页面截图
与这套框架一同发布的,还有一篇由梁文锋署名、联合北京大学完成的论文《DSpark:基于半自回归生成的置信度调度推测解码》。论文提到,当DSpark被部署到DeepSeek-V4的线上生产系统、直接承接真实用户流量时,它有效减少了因无效校验造成的算力浪费。相比成熟的基线方案MTP-1,在保持整体吞吐率不变的前提下,DSpark将单用户的生成速度提升了60%到85%。更关键的是,在严格交互时延约束下,它避免了吞吐率的大幅滑坡,实现了以往无法企及的性能档位,推高了整套服务系统的帕累托最优边界。

▲DSpark论文截图
从Hugging Face上模型卡的信息来看,DeepSeek-V4-Pro-DSpark和DeepSeek-V4-Flash-DSpark并不是全新的模型迭代,而是在原有版本基础上增加了一个推测解码模块,核心目的就是加速推理、降低成本。
推测解码这个词儿,说起来也好理解。简单讲,它是一种无损的大模型推理加速技术,核心流程就两步:先打草稿,再验证。把草稿生成和目标模型的校验分开做,从而提升整体推理效率。目前主流的并行草稿器,虽然能一次前向运算生成超长token序列,但token之间缺少依赖关系,导致草稿后续内容的通过率会快速下降。更麻烦的是,如果对整段长候选序列不加区别地做校验,宝贵的批次算力很容易浪费在那些被驳回的token上,进而让高并发场景下的整体吞吐率大幅打折。
DeepSeek提出的DSpark框架,把高吞吐的并行生成和自适应、感知负载的校验机制揉在了一起。为了保证草稿质量,它采用了
半自回归架构
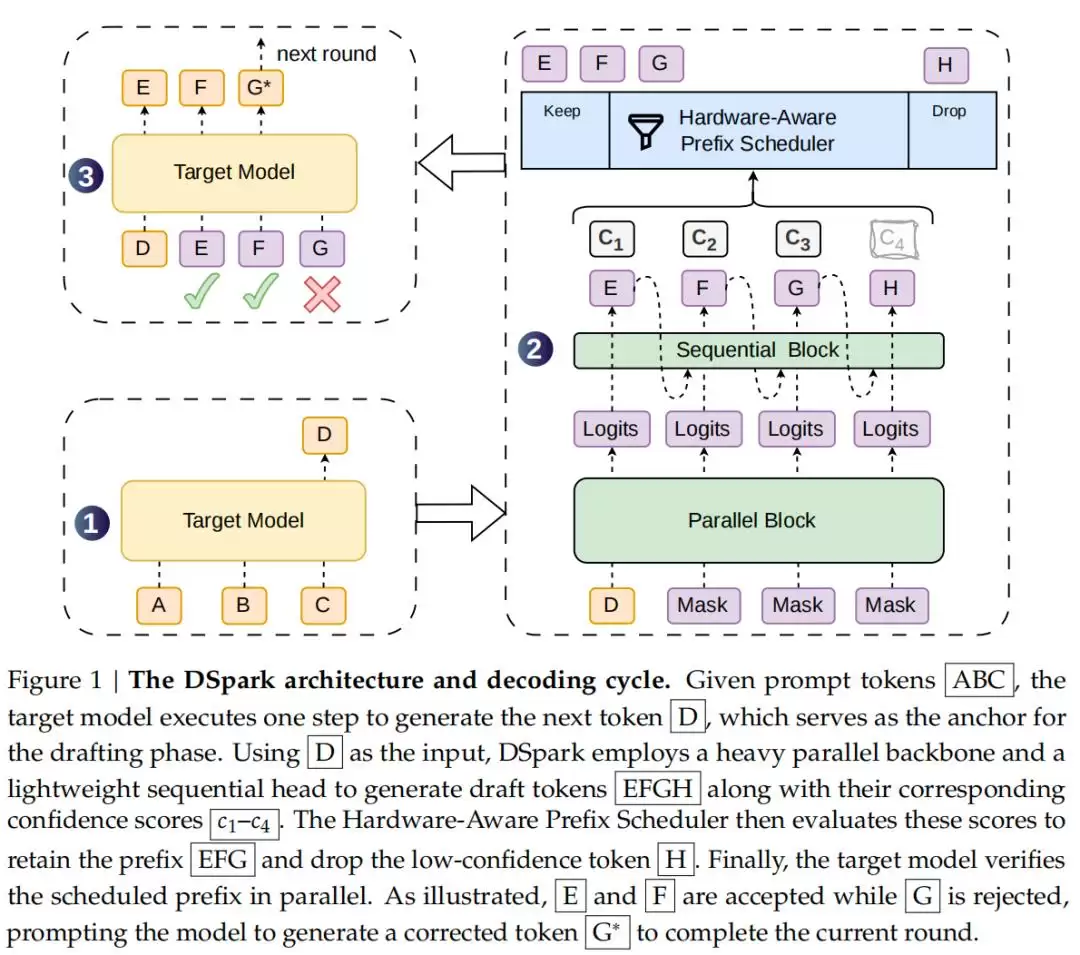
▲DSpark架构与解码流程
为了优化系统的运行效率,DSpark还引入了一个
置信度调度校验机制
下面这张截图展示的是DeepSeek为DeepSeek-V4-Pro-DSpark和DeepSeek-V4-Flash-DSpark提供的一个最小推理示例。
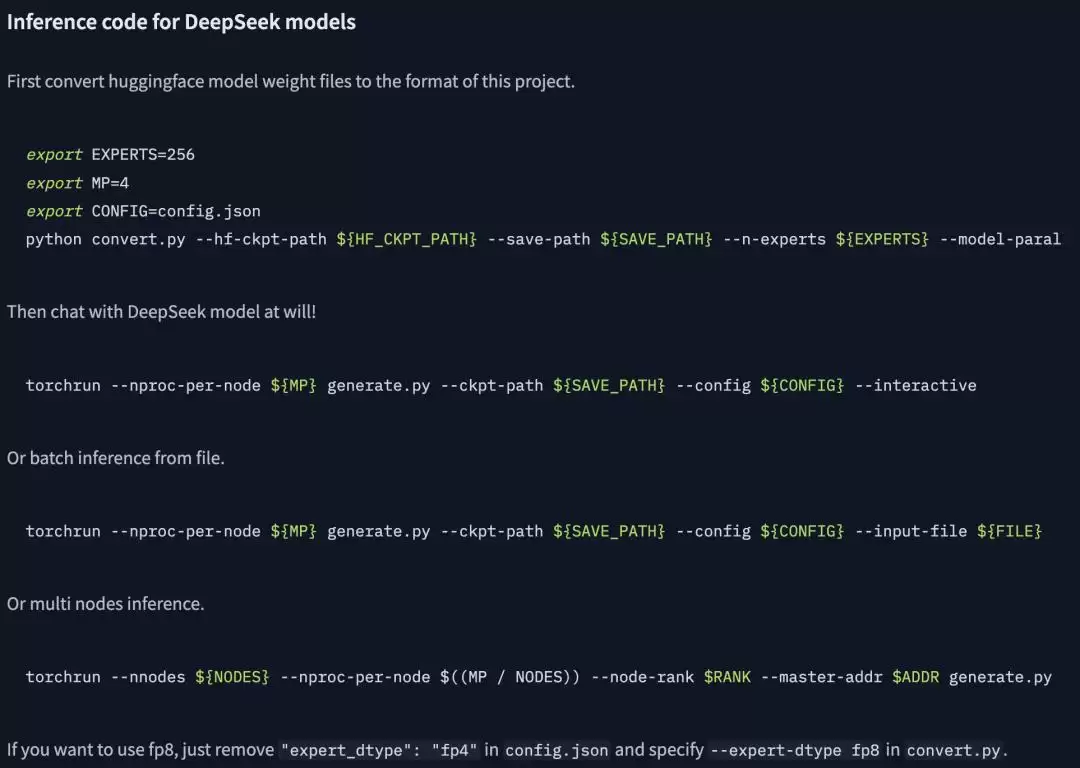
▲DeepSeek提供的最小推理示例
总的来说,用户部署了DSpark版本的DeepSeek-V4模型之后,在生成速度、首token延迟和并发能力这几个维度上,都会得到实打实的提升。
再来看
DeepSpec
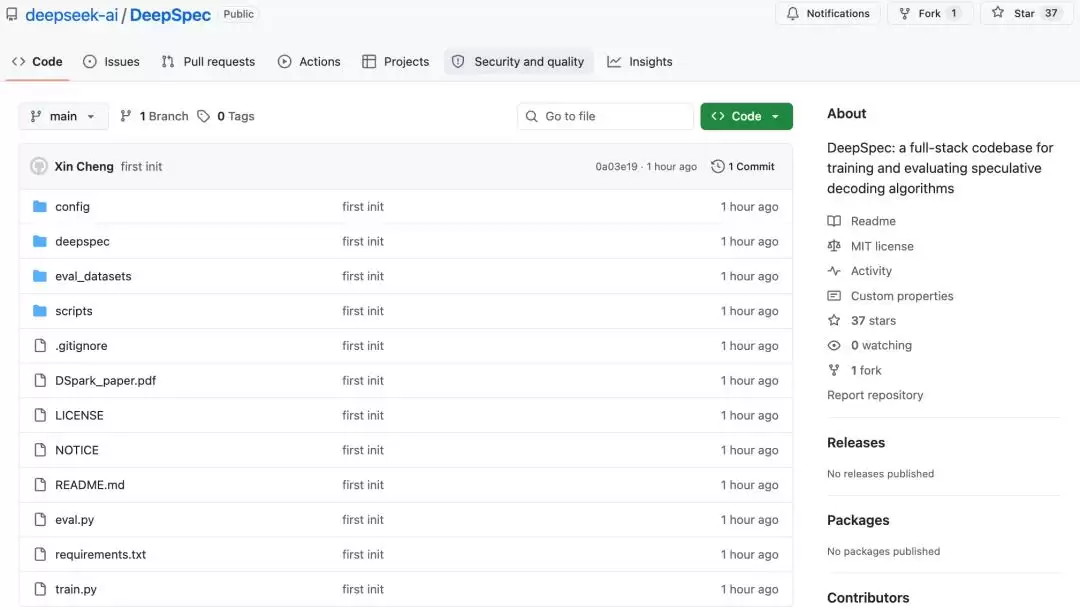
▲DeepSpec开源上新页面截图
DeepSpec的工作流程很清晰:它按顺序运行三个阶段,每个阶段的输出会作为下一个阶段的输入。
1、数据准备:
2、训练:
3、评估:
目前,DeepSpec支持的算法包括三个草稿模型:
DSpark、DFlash和Eagle3

▲DeepSeek致谢情况
可以看到,DeepSeek这次不止是发布了相关模型,还直接放出了完整的训练框架,供开发者和企业用自己的Qwen3、Gemma等模型来训练草稿模型。这趟动作背后的意图很明确:不仅要把技术壁垒打穿,还要把推理优化的门槛大大拉低。
结语:推理重要度提高,考验工程化能力
DeepSeek这次发布虽然低调,也不是模型本身的迭代,但含金量不低。它公布了一套让现有模型跑得更快的工程方案,有望带来更快、更低成本的推理体验,同时大幅降低推测解码的实际落地门槛。
大模型竞赛已经走到了训练与推理并重的系统博弈阶段。这次是DeepSeek完成融资后,率先在推理优化赛道落子。战略意图很清楚:不仅加速模型迭代和产品化,更要向下抢占算力效率竞争的制高点。




