
前特斯拉团队杨硕创业首作登顶 SOTA:妙动科技使机器人控制效率提升10倍
教一个人学骑车,你可以给他看一千张自行车的照片——但真正让他学会的,是那一脚踩上踏板的瞬间。照片和文字教的是"认知",而骑车需要的是"物理直觉"。
机器人领域也面临同样的难题。过去两年最热门的方案是视觉-语言-动作模型(VLA):让大语言模型"看懂"场景,再接上机器人的手脚,微调一下,机器人是不是就能干活?但问题在于,GPT等大模型吃的都是静态的图文数据——它知道"这是杯子",却不知道"杯子倒了会怎样"。要补上这些物理知识,就得靠真人戴VR头盔手把手地教,每个动作教上百遍,非常吃力。
那有没有一种数据,天然就包含物理动态信息,而且互联网上已经积累了海量规模?
有。视频。
妙动科技的答案:让视频生成模型当机器人的"物理老师"
这正是深圳初创机器人公司妙动科技(Mondo Robotics)新论文DiT4DiT的核心思路,一经发布即获Agility Robotics AI负责人等多位硅谷机器人专家关注和转发。据了解,DiT4DiT也是目前世界模型在人形机器人上首次落地的成果。
DiT4DiT的名字直接点明了架构:两个Diffusion Transformer(扩散变换器)串联协作——一个负责想象,一个负责执行。
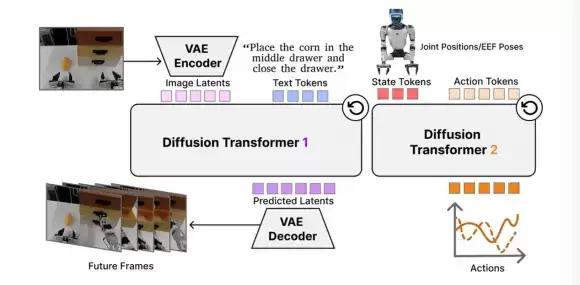
第一个DiT是"想象者":接收当前画面和语言指令,在内部预测接下来会发生什么,相当于让机器人先在"大脑"里演练一遍任务。这一模块继承了视频生成模型的预训练权重,携带着关于物理世界的丰富隐式知识。
第二个DiT是"执行者":读取第一个DiT在去噪过程中产生的中间特征,将"想象中的动态信息"翻译成具体的机器人关节指令。
简单讲:一个负责"理解世界会怎么变",一个负责"决定手该怎么动"。视频生成模型花了海量算力学到的物理直觉,被直接注入了机器人的决策系统。
一个反直觉的发现
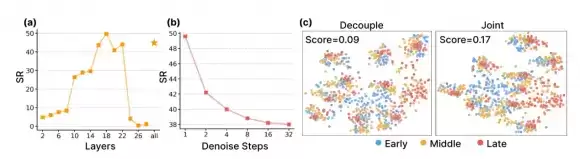
研发团队在消融实验中发现了一个违反常理的结论:从视频模型提取特征时,只需单步去噪效果最好——步数越多、画面越清晰,性能反而下降。提取层也有讲究,第18层(中间偏深层)的特征最优,达到性能峰值。
原因不难理解:对机器人动作决策而言,捕捉运动的趋势和物理规律,比还原精确的像素画面更重要。粗略但充满动态信息的中间特征,比最终清晰的预测帧更有"行动力"。
这个发现带来的工程优势非常实际:整个系统在单张RTX 4090消费级显卡上即可实现6Hz实时推理,仅需单颗RGB相机。而同类方案Cosmos Policy需要H100专业算力卡,推理速度仅1Hz。部署成本和速度,DiT4DiT都领先了一个量级。
实验成绩:全面刷新SOTA
数据是最直接的证明。
在行业权威的LIBERO基准上,DiT4DiT达到98.6%平均成功率,超越π0.5(96.9%)、CogVLA(97.4%)和OpenVLA-OFT(97.1%),刷新当前SOTA。而它使用的预训练数据量仅为同类方法的15%,收敛速度快了7倍——用更少的数据、更短的时间,训练出更强的模型。
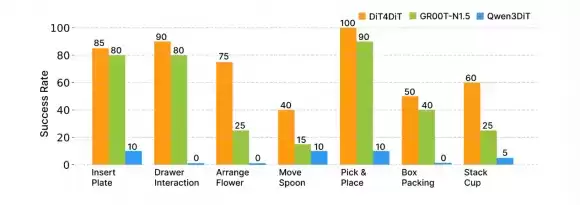
在更具挑战性的RoboCasa-GR1基准(24项家庭任务)上,DiT4DiT取得50.8%综合成功率,比NVIDIA GR00T-N1.5(41.8%)高出9个百分点。真机实验在宇树科技G1人形机器人上进行,共测试7项任务——插花、打包、移动勺子、叠杯子、抽屉交互等,DiT4DiT全面领先。值得一提的是,DiT4DiT仅使用机器人头部单目相机完成所有任务,而此前业内方案多依赖头部加双手共三个相机,系统复杂度明显更高。
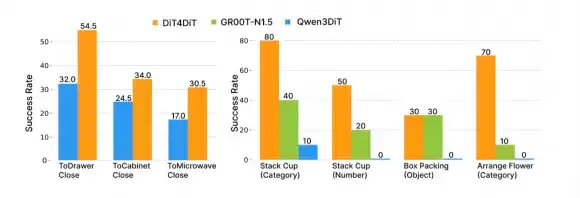
零样本泛化是该方法最突出的能力。换物体材质、换形状、换数量——面对从未见过的测试场景,DiT4DiT仍保持40%–70%的成功率。对比来看,Qwen3DiT在多项泛化测试中直接归零。这一差距说明:视频生成赋予的物理直觉,确实比静态图文对齐更贴近真实世界的复杂性。
团队:前特斯拉Optimus + 前大疆
妙动科技总部位于深圳,专注具身智能前沿研究与落地。联合创始人兼CTO杨硕是CMU博士,曾任职于特斯拉Optimus人形机器人团队,也是知乎机器人领域知名博主。另一位联合创始人来自大疆,曾负责供应链与RoboMaster机器人竞技项目。团队汇聚多名强化学习与具身智能方向的博士研究员,DiT4DiT正是妙动科技与香港科技大学(广州)梁俊卫教授团队合作完成的研究成果。
论文项目页已公开,代码与模型权重预计后续开源。




