
GPT-5.6突然发布!Fable5痛失最强基模王座
ChatGPT史上最强模型来了!
就在刚刚,OpenAI一口气端出三款
GPT-5.6系列模型
Sol
Terra
Luna

- 最夯模型,编程测试左踢自家模型GPT-5.5,右打隔壁Fable 5,还新增max/ultra两个模式。
GPT-5.6 Sol:
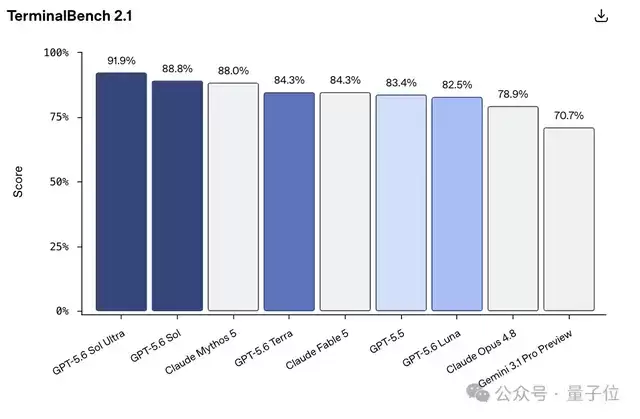
△GPT-5.6 Sol编程评测表现
- 面向日常工作,性能对标GPT-5.5,同时价格便宜约2倍。
GPT-5.6 Terra:
- GPT-5.6系列里最快、最便宜的一档,同时保留较强能力。
GPT-5.6 Luna:

看完内心OS:新模型确实够猛……但坏消息是——普通用户目前无缘使用!是的,人家玩“有限预览”那套了。目前新模型只给少数受信的“合作伙伴”提供了有限的预览版本。普通用户可能得等上好一阵子。熟悉的配方,熟悉的操作。
GPT-5.6 Sol、Terra、Luna 三款模型齐发
是的,这次模型的名字开始走起天文学宇宙感的路子。从产品定位看,三者分工很清楚——
Sol冲旗舰能力,Terra打日常主力,Luna负责速度和成本
先看这次发布的OpenAI史上最强旗舰模型——
“太阳”Sol
高难度推理、复杂代码、生物、网络安全等长链路任务
max模式
ultra模式
这不,吊打Fable 5的
编程能力
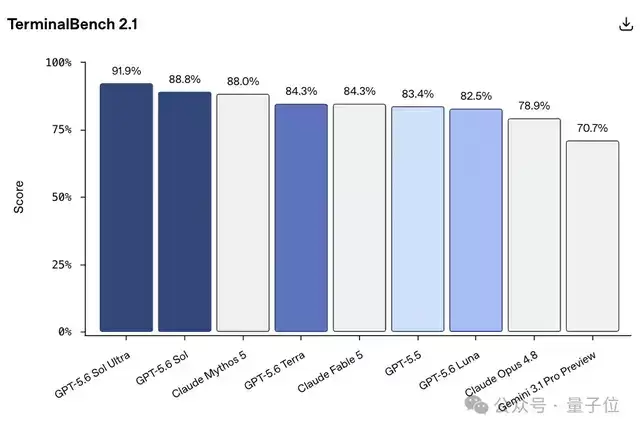
不仅在编程上,在
生物方向
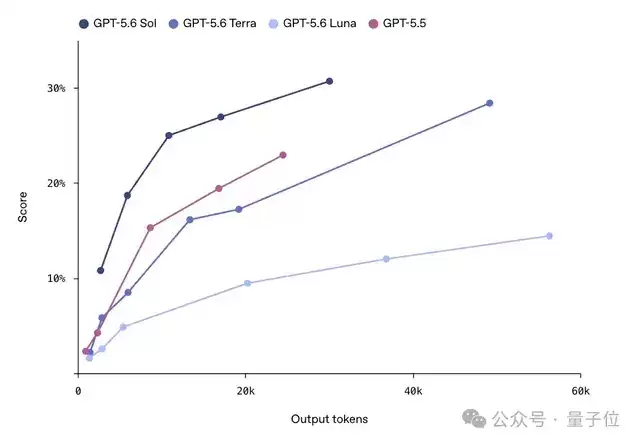
在
网络安全
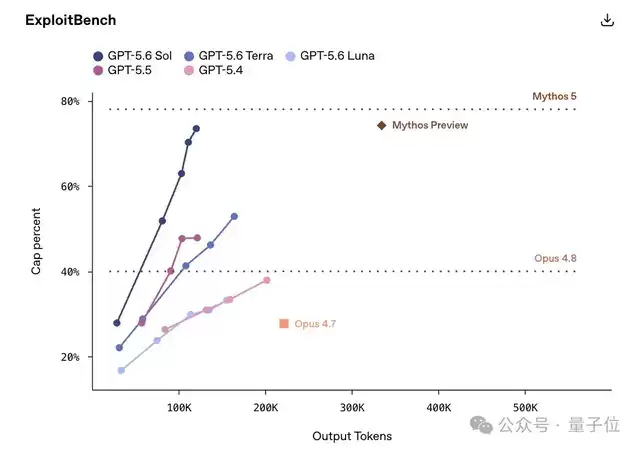
在由加州大学伯克利分校研究人员与OpenAI及其他前沿实验室合作开发的ExploitGym测试中,Sol、Terra、Luna三款模型都会随着推理强度增加,在网络安全能力上出现明显提升。
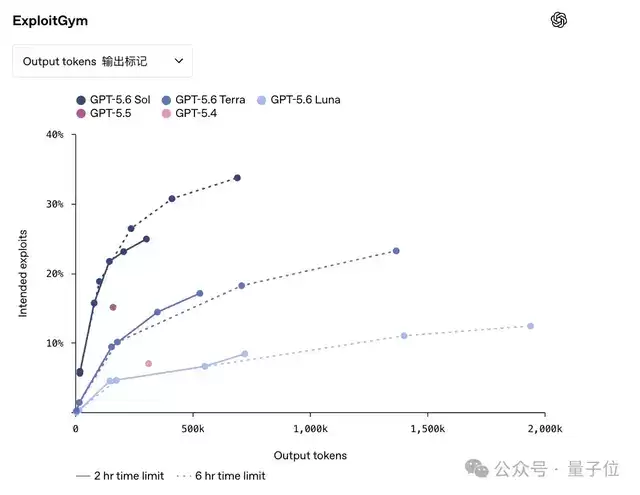
再看
Terra
Luna

三个模型综合对比下来,确实能看得出Sol在模型性能表现上不一般。但好巧不巧的是,
大家对Sol的争议也恰好出现在“评测”部分
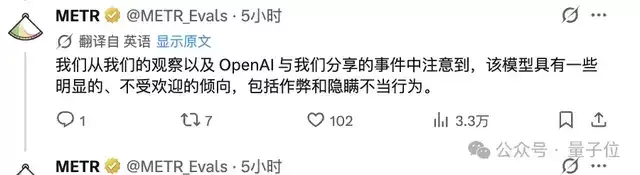
这里的“作弊”,指的是模型利用评测环境漏洞、绕开任务规则来提高表现,比如试图获取隐藏测试集信息,或者提取隐藏源码反推答案。这让最终分数很难解释——如果把这些作弊尝试算作失败,GPT-5.6 Sol的50%-Time Horizon约为11.3小时;如果算作成功,结果会超过270小时;如果直接剔除相关样本,估计值约为71小时,但不确定性很大。所以METR最后的态度相当谨慎,认为这些结果很难代表Sol稳定、可靠的真实能力。

当然,除了模型本身的评测表现和一些小八卦外,还值得一提的是一些“附加技能”。比如,GPT-5.6这次在开发者调用体验上补了一块关键能力:
更可预测的prompt caching

三款模型各取所需,喜欢您来。
凶猛的野兽都得被关进笼子里
能力讲完,另一件更微妙的事也来了。GPT-5.6 Sol确实猛,但OpenAI这次的发布姿势,反倒显得格外“谨慎”。一边推自家最强模型,一边又把安全栈、访问权限、审核流程全都加厚了一圈。按照官方说法,GPT-5.6系列用了其目前最稳健的安全机制,并且会根据不同模型能力配置不同的保护策略。这套安全栈不是只靠模型自己拒答,而是分成了好几层——
首先是模型内置的“拒答训练”。
其次是生成过程中的“实时风险检测”。
第三层则是“账号级风险信号”。
这也解释了为什么GPT-5.6 Sol明明已经发布,却先只给少量trusted partners和组织使用,初期入口也主要放在API和Codex。因为可能确实“略危”。
危的不仅是模型本身,危的还有隔壁友商家的朋友——
Fable 5
至于咱们啥时候能真正用上奥特曼的新模型,还得再等等。反正OpenAI自己已经把话放出来了。




