
组件语义快照:我观察AI产品界面时用的6字段记录法
今天想聊聊一套结构化观察界面的方法。它不会替代设计走查,而是给走查补充一层语义维度的记录标准。这篇内容是基于之前《组件语义快照与模式诊断:AI 生成界面的第一道检查》的思路继续展开的。
一、现有走查方式在记录什么
日常的设计质量保障里,团队一般靠人工走查来发现问题。走查的产出大致就这些:
- 视觉素材——要么是界面截图,要么是操作录屏
- 问题标注——在素材上直接圈出异常区域
- 问题描述——用文字说明这里不符合什么规范
这套打法在捉“视觉是否一致”的问题上相当管用。只要问题看着像“颜色是不是偏了”“字号对不对”“间距跟网格洗没对齐”,视觉素材本身就能说明一切。
但有个边界情况值得关注:当问题牵扯到
语义表达
举个具体的例子:三个月后翻出一张走查记录,我一眼就能看出来“哦,这个按钮颜色错了”,但很难说清楚“这个按钮放在这个场景里本来想表达什么意思”——因为当时的场景上下文、用户到底因为什么困惑、是在什么条件下触发的,这些全没有结构化的记录。
这倒不是现有走查方式的错,它的设计目标本来就在视觉层面。可如果我的工作目标从“视觉一致性”扩展到了“语义一致性”,那就需要一套新的方法了——既能记录界面长什么样,又能同时记下当时的语义上下文。
二、组件语义快照的定义
组件语义快照(Component Semantic Snapshot)就是为这种语义层面观察设计的结构化记录格式。
它基于一个关键假设:
界面层是语义层的最终呈现面,但语义信息没法从界面像素里直接推导出来。
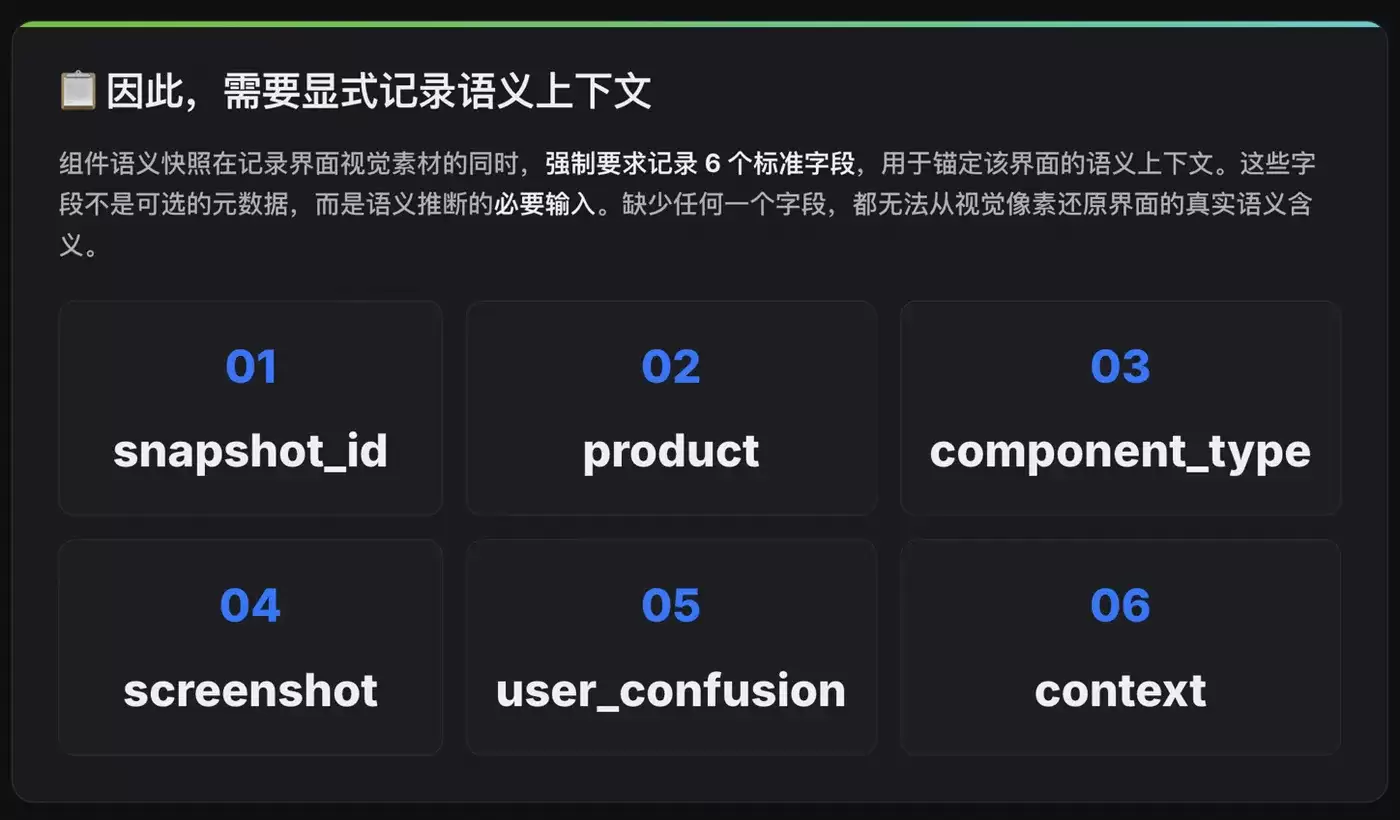
所以,组件语义快照在记录界面截图的同时,强制要求填写 6 个标准字段,用来锚定这个界面到底处在什么语义上下文中。

三、6 个标准字段
| 字段 | 说明 | 记录目的 |
|---|---|---|
snapshot_id | 快照唯一编号 | 建立可追溯的引用标识,便于模式库归档和版本管理 |
product | 产品名称 | 明确漂移发生在哪个具体产品,支持跨产品对比 |
component_type | 组件类型 | 按用户交互场景分类,决定后续匹配的模式分支 |
visual_record | 界面视觉素材(含语义标注) | 记录界面呈现,并用标注框标出语义漂移的具体区域 |
user_confusion | 用户困惑描述 | 记录用户面对该界面时的真实反应,作为语义断层的直接证据 |
context | 触发场景 | 记录导致该界面状态出现的操作路径,支持复现 |
3.1 字段设计 rationale
snapshot_id
product
component_type
visual_record
user_confusion
context
四、一个完整示例
下面是一张真实快照的脱敏记录:
snapshot_id: SNAP-202506-001
product: ChatGPT
component_type: 错误状态
visual_record: 界面视觉素材显示 4 种错误提示,均使用红色作为视觉表达。标注框圈出:"Error in message stream"(红色背景条)、"network error"(红色文字)、"Something went wrong"(红色边框卡片)、"Too many requests"(红色文字+感叹号)。
user_confusion: "看到红色就刷新,结果只是限流。红色让我以为系统崩了。"
context: 高峰期快速发送 5 条消息后触发
匹配模式: ERR-001(后果差异未分级)
五、怎么用
组件语义快照的使用流程分三步:
第一步:采集视觉素材并标注
拿到界面截图后,用标注框把语义漂移的具体位置标出来。标注原则很简单:框出的是“语义表达跟预期不一致的区域”,而不是“视觉不符合规范的区域”。
第二步:填写 6 个字段
按标准格式填好编号、产品、组件类型、用户困惑、触发场景。其中 user_confusion 优先用用户原话;实在拿不到原话,就基于用户行为数据(比如错误操作后的跳出路径)做推断,并且要注明推断依据。
第三步:归档到模式库
系统会根据 component_type 和 user_confusion 自动匹配已有模式。如果匹配不上,就创建一个新模式草案,等后续验证。
六、与现有走查流程的关系
组件语义快照不替代视觉走查,而是跟它并行运行。
- 视觉走查回答的是:界面是否符合设计规范?
- 语义快照回答的是:界面是否表达了正确的语义?
两者共享视觉素材作为输入,但输出不一样。视觉走查的输出是“修改建议”,语义快照的输出是“模式证据”——用于归纳通用的漂移规律,进而生成机器可读的约束契约。
实际操办时,通常建议:视觉走查发现的问题,如果涉及语义表达(比如错误文案、按钮含义、状态提示),就同步生成一张组件语义快照。这样视觉问题修了,语义证据也攒下了。
七、局限与边界
组件语义快照目前存在以下局限:
- :它没法自动采集,需要观察者具备语义敏感度,能分清“视觉问题”和“语义问题”。
依赖人工观察
- :user_confusion 可以是原话、推断或两者结合。推断的准确性取决于观察者的产品经验。
用户困惑字段主观
- :目前这 5 类组件是基于观察范围归纳的,随着样本增加,分类可能还得扩展。
组件类型分类未穷尽
- :它只负责记录和归档,不直接输出修复方案。修复方案得结合契约库(Contract Library)才能生成。
不解决修复问题
八、结语
组件语义快照是从“视觉层走查”向“语义层观察”过渡时设计出的第一件工具。它的价值不在于技术多复杂,而在于
强制要求记录语义上下文
等快照攒到一定数量,就能从中归纳出通用的漂移模式(比如 ERR-001“后果差异未分级”),这些模式将成为下一阶段“约束显化”的输入素材。
接下来,会基于这些快照证据,定义语义约束契约(YAML 格式),并验证它到底行不行得通。
Gap 期局限性声明
当前状态:架构推演与最小可行原型阶段。YAML 规范、校验逻辑为定义层实现,尚未接入生产级 LLM API 或 CI 流水线。欢迎基于现有思路共建。




