
大语言模型提示词工程学习总结
国庆期间提前休假,回老家那几天确实没太多精力更新文章,原计划的周更节奏也不得不暂时停一停。趁着假期的尾巴补上一篇,也顺带补上迟到的祝福:祝大家中秋国庆双节快乐!
现在每天用大模型的时间越来越多,但大部分时候还是像以前问百度那样直接输入问题,基本也能拿到想要的答案,很少额外编写提示词。一旦遇到稍微专业一点的问题,大模型给出的答案就没那么精准了。正好工作中需要借助大模型来做故障诊断,系统学习提示词工程变得很有必要。
本文内容主要参考自提示词工程指南(https://www.promptingguide.ai/zh)和花园老师的文档。
提示词工程简介
提示工程(Prompt Engineering)是一门较新的学科,核心关注提示词的开发和优化,帮助用户把大语言模型(Large Language Model, LLM)应用到各种场景和研究领域。掌握提示工程,能让你更清楚地理解大语言模型的能力边界和局限。
提示词工程的根本目标在于:精心设计输入(即“提示”),从而从LLM中获得最精确、最相关、最符合预期的输出。
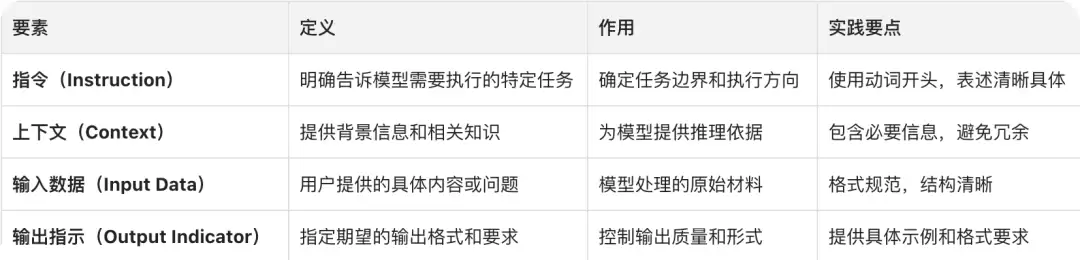
1. 提示词工程的四大核心要素
- 指令(Instruction)
- 上下文(Context)
- 输入数据(Input Data)
- 输出提示(Output Indicator)
2. 大语言模型的设置
使用提示词时,通常通过API或直接与大模型交互。我们可以配置一些参数来获得不同的输出结果。调整这些设置对提升响应的可靠性很关键,往往需要做一些实验才能找到最适合特定用例的配置。以下是常见的一些参数:
- :简单说,temperature值越小,模型返回的结果越确定;调高该值,模型可能输出更随机、更多样化或更具创造性的结果。比如在质量保障或问答任务中,设置较低的temperature有助于模型基于事实给出简洁准确的答案;而在诗歌生成或创意任务中,适度调高temperature效果更好。
Temperature
- :与temperature一起被称为核采样(nucleus sampling)的技术,同样用来控制返回结果的确定性。需要准确和事实时把参数调低,希望更多样化的响应时调高。一般建议只调整temperature或top_p其中的一个,不要两者同时调整。
Top_p
- :通过调整max length控制大模型生成的token数量,防止输出过长或不相关的内容,同时也有助于控制成本。
Max Length
- :stop sequence是一个字符串,设定后模型会在此处停止生成token。这是控制响应长度和结构的另一种方法。例如,可以添加“11”作为stop sequence来告诉模型生成不超过10个项的列表。
Stop Sequences
- :对下一个生成的token进行惩罚,惩罚力度与token在响应和提示中已出现的次数成正比。频率惩罚越高,某个词重复出现的可能性越低,可以有效减少重复。
Frequency Penalty
- :也是对重复token施加惩罚,但所有重复token受到的惩罚是一样的——出现两次和出现十次的惩罚相同。这个设置防止模型在响应中过于频繁地重复词语。希望生成多样化或创造性文本时,可以调高presence penalty;希望更专注时则调低。同样,一般建议只调整频率惩罚或存在惩罚中的一个。
Presence Penalty
3. 设计提示词的通用技巧
a. 从简单开始
设计提示词是个迭代过程,需要大量实验才能获得最佳结果。可以从简单的提示词开始,逐步添加更多元素和上下文。如果任务涉及多个子任务,尝试分解成更简单的子任务,随着结果改善再逐步构建——一开始就堆太多复杂性反而不利于优化。
b. 指令
用明确的命令指示模型执行各种简单任务,比如“写入”“分类”“总结”“翻译”“排序”等。不断实验,用不同的关键词、上下文和数据测试不同的指令,找出最适合自己用例的方式。通常上下文越具体、与任务越相关,效果越好。
c. 具体性
对指令和任务的描述要非常具体。提示越具描述性、越详细,结果往往越好。不存在什么“特定词元”或“关键词”能稳定带来好结果,关键在于提示词的格式和描述性。提供示例对于获得特定格式的期望输出非常有效。
d. 避免不明确
在追求详细和格式优化时,容易掉进陷阱:把提示设计得过于“聪明”,反而制造出不明确的描述。通常具体和直接更好,跟有效沟通的类比一样——越直接,信息传达越高效。比如想了解提示工程的概念,可以这样问:
解释提示工程的概念。保持解释简短,只有几句话,不要过于描述。
上面的提示不够清楚,不知道要用多长的句子、什么风格。尽管可能仍能得到不错的响应,但更好的提示应该非常具体、简洁且切中要点:
使用 2-3 句话向高中学生解释提示工程的概念。
e. 做什么还是不做什么?
另一个常见技巧:避免说“不要做什么”,而要说“要做什么”。这样更具体,也更能聚焦于有利模型生成良好回复的细节。
常见提示技术及模板
1. 零样本提示 (Zero-shot Prompting)
最基础的提示技术,不提供任何示例,直接描述任务要求。依靠模型预训练的知识和理解能力,通过清晰指令完成任务。适用于通用任务(翻译、总结、问答)、模型能力范围内的标准操作、快速原型验证。
# 基础零样本提示
将以下中文翻译成英文:
"人工智能正在改变我们的生活方式。"
# 优化后的零样本提示
你是一位专业的中英翻译专家。请将下面的中文句子翻译成地道的英文,注意保持原意的准确性和表达的自然性:
中文原文:"人工智能正在改变我们的生活方式。"
英文翻译:
2. 少样本提示 (Few-shot Prompting)
通过提供少量示例来指导模型理解任务模式和期望输出,利用模型的上下文学习能力。
任务:情感分析
示例1:
输入:这部电影真的很棒!
输出:正面
示例2:
输入:服务态度太差了,很失望。
输出:负面
示例3:
输入:价格还可以接受。
输出:中性
现在请分析:
输入:这家餐厅的环境很舒适,菜品也不错。
输出:
3. 角色扮演提示 (Role-based Prompting)
通过为AI分配特定角色来引导其行为和回答风格,提供明确的行为框架,增强回答的专业性和一致性,改善用户体验。
# 角色提示模板
你是一位{专业领域}的{具体角色},拥有{年限}年的{相关经验}。
你的特点:
- {特点1}
- {特点2}
- {特点3}
你的任务是{具体任务描述}。
请以{角色身份}的口吻和专业水准来回答用户的问题。
4. 思维链 (Chain of Thought)
革命性的提示技术,通过引导模型展示推理过程来提高复杂任务准确性。模拟人类解决问题的思维过程,将复杂问题分解为多个推理步骤。
a. 显式思维链
问题:一个班级有30名学生,其中60%是女生,女生中有25%戴眼镜。请问戴眼镜的女生有多少人?
让我们一步步来解决这个问题:
第一步:计算女生总数
女生数量 = 30 × 60% = 30 × 0.6 = 18人
第二步:计算戴眼镜的女生数量
戴眼镜的女生 = 18 × 25% = 18 × 0.25 = 4.5人
由于人数必须是整数,所以戴眼镜的女生有4或5人。
根据题意,应该是4.5人,实际情况可能是4人或5人。
答案:4.5人(理论值)或4-5人(实际值)
b. 隐式思维链引导
请解决以下数学问题,并详细说明你的推理过程:
问题:{具体问题}
解答思路:
1. 首先分析题目条件...
2. 然后确定解题方法...
3. 接着进行计算...
4. 最后验证答案...
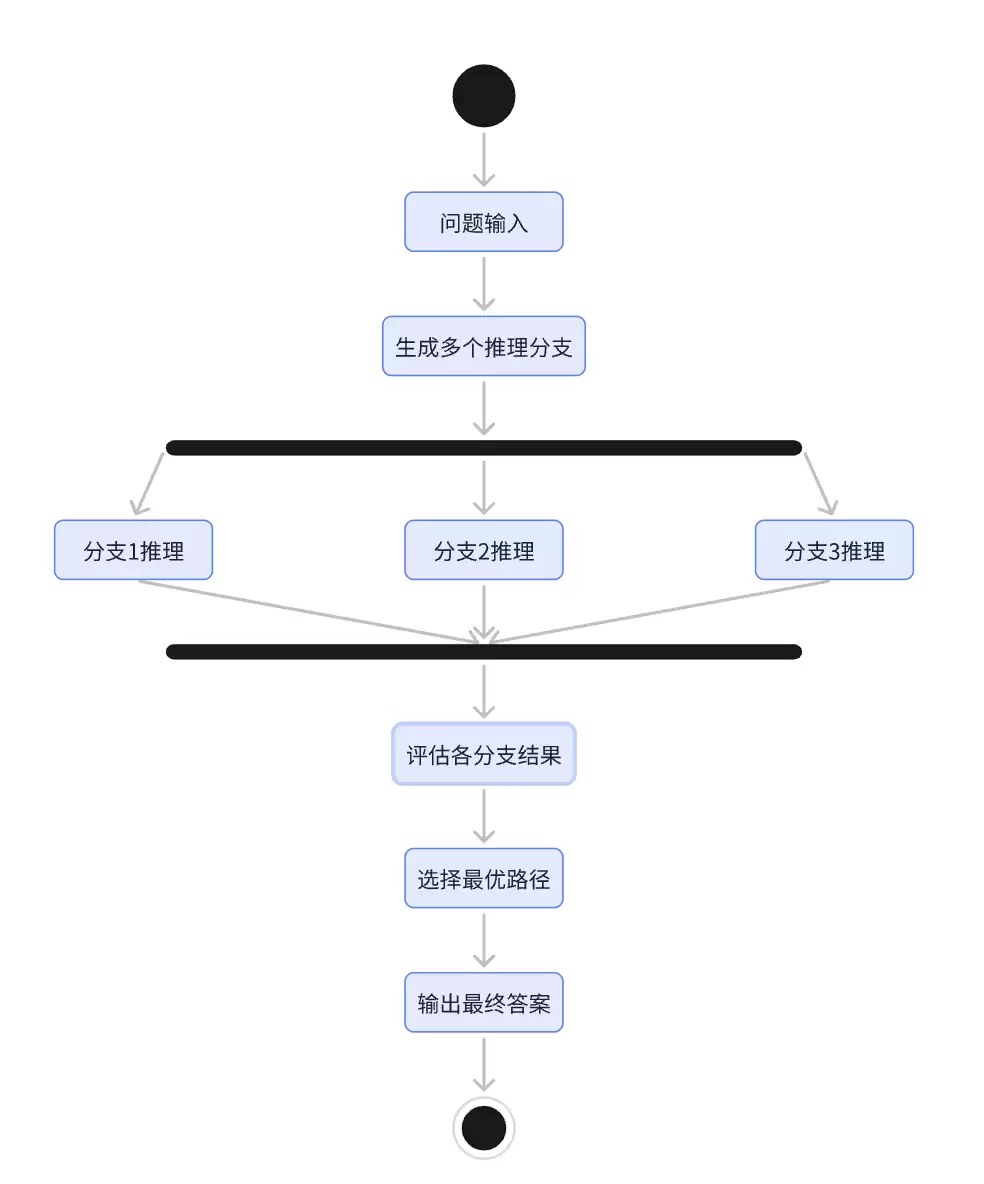
5. 思维树 (Tree of Thought)
思维链的进阶版本,允许模型探索多个推理路径并选择最优解,具备多路径探索、回溯和修正能力,更适合复杂决策问题。
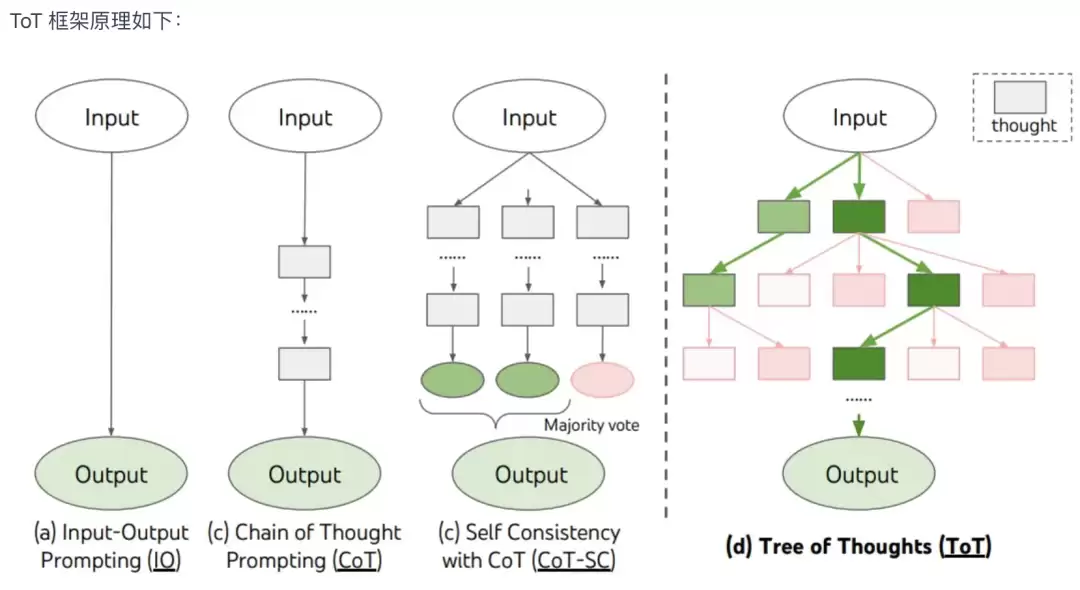
ToT框架和其他框架对比图
6. 自洽性推理(Self-Consistency)
通过多次采样和投票机制来提高答案可靠性。流程:使用相同提示生成多个推理路径 → 收集所有推理结果 → 通过投票或一致性检查选择最终答案。
# 自洽性推理模板
请用三种不同的方法解决以下问题,然后比较结果的一致性:
问题:{具体问题}
方法一:{推理路径1}
方法二:{推理路径2}
方法三:{推理路径3}
一致性检查:
- 结果是否一致?
- 如果不一致,哪个更合理?
- 最终答案:
7. ReAct推理(Reasoning and Acting)
结合推理和行动,使模型能够在推理过程中调用外部工具。核心思想:Reasoning(分析问题,制定计划)→ Acting(执行具体行动,调用工具)→ Observing(观察结果,调整策略)。
Thought: 我需要查找最新的股票价格信息
Action: search_stock_price("AAPL")
Observation: 苹果公司股票当前价格为$150.25
Thought: 现在我需要计算投资回报率
Action: calculate_return(initial_price=140, current_price=150.25)
Observation: 投资回报率为7.32%
Thought: 基于以上信息,我可以给出投资建议
Action: generate_recommendation(return_rate=7.32, risk_level="medium")
8. 智能体提示词
# 智能体系统提示词
你是一个{agent_role},具有以下能力和特征:
## 身份定义
- 角色:{specific_role}
- 专业领域:{domain}
- 核心能力:{capabilities}
## 工作流程
1. **任务理解**:仔细分析用户需求
2. **计划制定**:制定详细的执行计划
3. **工具调用**:使用适当的工具和资源
4. **结果整合**:综合信息并形成答案
5. **质量检查**:验证答案的准确性和完整性
## 可用工具
{a vailable_tools}
## 记忆管理
- 短期记忆:当前对话上下文
- 长期记忆:历史交互和学习经验
- 工作记忆:当前任务的中间结果
## 行为准则
{beha vioral_guidelines}
现在请处理用户的请求:{user_request}
总结
提示词工程是解锁大语言模型全部潜力的关键技能。它不是死记硬背的公式,而是一种需要不断实践和感悟的思维方式。掌握其核心原则、结构和技巧,我们就能更高效、更精准地与AI协作,把大模型变成一个强大的生产力和创造力工具。
这篇偏向理论学习的总结,后续会继续深入具体的提示词实践,针对工作和生活中的实际需求,分析一些通用的提示词模板。




