
Unlimited-OCR - 百度开源的端到端长文档 OCR 模型
来源:互联网
时间:2026-06-26 14:28:28
Unlimited-OCR是什么
Unlimited-OCR,百度最新推出的端到端长文档OCR模型,一句话总结就是:用常数级的资源消耗,实现数十页文档一次性转录。它的核心秘密在于一套名为Reference Sliding Window Attention(参考滑动窗口注意力)的机制——简单来说,就是让解码器的KV cache从线性增长压缩为常数,不再随页数膨胀。模型采用3B总参数的MoE架构,在OmniDocBench v1.6上以93.92%的总分拿下端到端SOTA,推理速度达到5580 TPS。更难得的是,代码和权重已经全面开源,拿过来就能用。
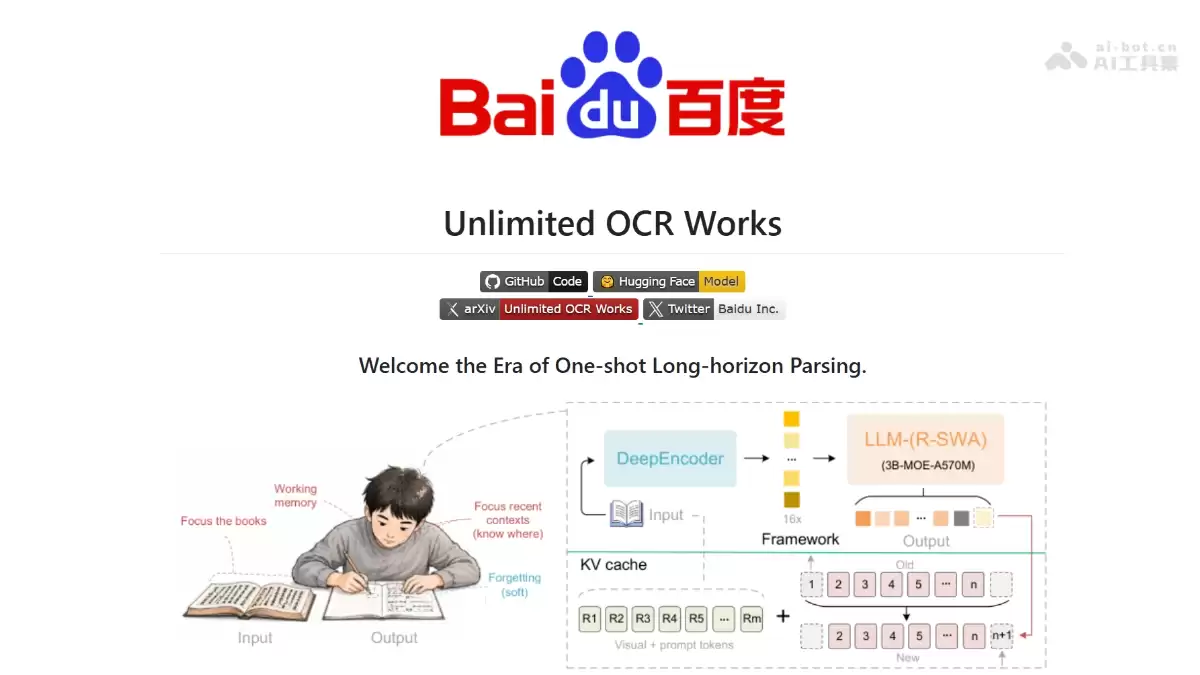
Unlimited-OCR的主要功能
- :支持2页到40+页的PDF文档单次前向转录,告别逐页for循环的繁琐操作。
超长文档一次识别
- :覆盖PPT、学术论文、书籍、彩色教材、试卷、杂志、报纸、笔记、研究报告等9种常见版式,几乎各行各业都能找到用武之地。
多类型文档解析
- :文本、公式、表格、阅读顺序全链路端到端输出,公式CDM达到95.79%,表格TEDS达到93.32%,精度在同类产品中相当能打。
高精度内容提取
- :Base模式用1024×1024分辨率处理多页长文档,Gundam模式则用动态分辨率专注单页高精度识别——两种模式按需切换。
双分辨率视觉编码
- :无论输出序列有多长,KV cache始终恒定在m+n,推理延迟和显存占用都保持水平稳定,不会有那种“越跑越慢”的尴尬。
常数延迟推理
Unlimited-OCR的技术原理
- :每个生成token只关注全部的参考token(视觉加提示词)以及最近的128个输出token。关键点在于,视觉token被排除在滑动窗口的状态转移之外,长程生成过程中视觉特征就不会被逐步模糊掉。
R-SWA 注意力机制
- :把KV cache实现成一个容量为m+n的队列,每生成一个新token,就淘汰第(m+1)个token。这样一来,计算成本和内存占用不再随着序列长度递增——无论输出多长,开销都被锁死。
常数 KV Cache 设计
- :沿用SAM-ViT级联CLIP-ViT的架构,通过bridge层做16倍token压缩。1024×1024的图像被压缩成256个视觉token,编码一次后冻结,后续不再参与更新。
DeepEncoder 视觉编码
- :3B总参、500M激活的MoE架构,所有注意力层都替换成了R-SWA。基于DeepSeek-OCR的checkpoint续训了4000步,全局batch为256,最大序列长度32K。
MoE-LLM 解码器
- :在Transformers和SGLang两个推理框架中都实现了常数TPS和常数显存的KV cache管理。配上Flash Attention v3内核,per-call延迟全程保持水平,没有波峰波谷。
推理引擎优化

如何使用Unlimited-OCR
- :通过Hugging Face(仓库名
模型下载
baidu/Unlimited-OCR)或GitHub(同名仓库)获取代码与权重,都是公开资源。 - :支持Transformers库和SGLang推理引擎,配好对应的GPU环境就能跑。
环境准备
- :支持PDF页面图像输入。Base模式处理多页长文档,Gundam模式处理单页高分辨率识别,按需选用。
输入格式
- :单次前向就能完成整本/整份文档的OCR转录,不需要外部调度器分页,省心不少。
推理调用
- :R-SWA机制并非OCR专属,可以迁移到ASR、翻译、字幕生成等需要“参考源+长输出”的任务上去。
扩展应用
Unlimited-OCR的核心优势
- :OmniDocBench v1.5总分93.23%,v1.6总分93.92%,端到端第一,数据说话。
SOTA 识别精度
- :KV cache不随文档页数增长,20页、40+页的长文档,显存和延迟都稳如泰山。
常数资源占用
- :输出越长,优势越明显。在6144 token时,理论TPS上限比DeepSeek-OCR领先大约35%。
速度随长度放大
- :R-SWA不是OCR专属的trick,理论上任何“参考源+长输出”的生成任务都能套用。
通用解码架构
- :3B总参、500M激活,模型和代码都开源了,部署和二次开发的门槛很低。
轻量开源
Unlimited-OCR的项目地址
- :https://github.com/baidu/Unlimited-OCR
GitHub仓库
- :https://github.com/baidu/Unlimited-OCR
HuggingFace模型库
Unlimited-OCR的同类竞品对比
| 维度 | Unlimited-OCR | DeepSeek-OCR |
|---|---|---|
模型规模 | 3B-A0.5B (MoE) | 3B-A0.5B (MoE) |
注意力机制 | R-SWA(参考滑动窗口注意力) | 标准全注意力 |
KV Cache 增长 | 常数(m+n),不随序列长度增加 | 线性增长,随输出序列持续累积 |
OmniDocBench v1.5 总分 | 93.23% | 87.01% |
OmniDocBench v1.6 总分 | 93.92% | 90.25%(DeepSeek-OCR 2) |
文本编辑距离 | 0.038 | 0.073 |
公式 CDM | 92.61% | 83.37% |
表格 TEDS | 90.93% | 84.97% |
阅读顺序编辑距离 | 0.045 | 0.086 |
推理速度 | 5580 TPS,全程常数延迟 | 4951 TPS,延迟随长度递增 |
长文档支持 | 单次前向 40+ 页,无需分页 | 长序列受限于KV cache膨胀,需分页处理 |
训练基础 | 基于DeepSeek-OCR checkpoint续训4000步 | 基座模型 |
Unlimited-OCR的应用场景
- :批量处理成百上千页的扫描版PDF、古籍、合订本,不需要拆分就能一次性结构化提取,效率翻倍。
企业档案数字化
- :整本论文、期刊合辑、研究报告的端到端转录,公式、表格、阅读顺序全保留,省去后期手动整理的时间。
学术文献解析
- :多页试卷、练习册的批量识别,彩色教材和复杂版式也能应对自如。
教育试卷批改
- :长篇幅合同文本的精准OCR提取,为后续的NLP分析和合规审查提供干净的数据基础。
法律合同审核
- :作为R-SWA通用解码方案的验证场景,可以进一步扩展到ASR、字幕生成等长序列任务,未来想象空间不小。
多语言翻译流水线




