
Claude惊人真相被教授曝光:思考过程加密,给钱也看不到
当初,Anthropic推出extended thinking的时候,打出的旗号是“让用户看到思考过程”,一副透明标杆的姿态。现在回头看,这个叙事多少有点讽刺——你看到的,只是他们允许你看到的那部分。那些被加密、被压缩、被锁在全局密钥里的内容,到底藏着什么?
年初,Anthropic悄无声息地改了Claude Code的默认设置:自适应思考(adaptive thinking)、思考块隐藏(redact-thinking),外加默认effort降级。结果就是思考深度直接掉了约67%,用户最直观的感受就四个字:“AI降智了”。而Anthropic对此一言不发,直到有人拿着证据找上门,才开始找补理由。
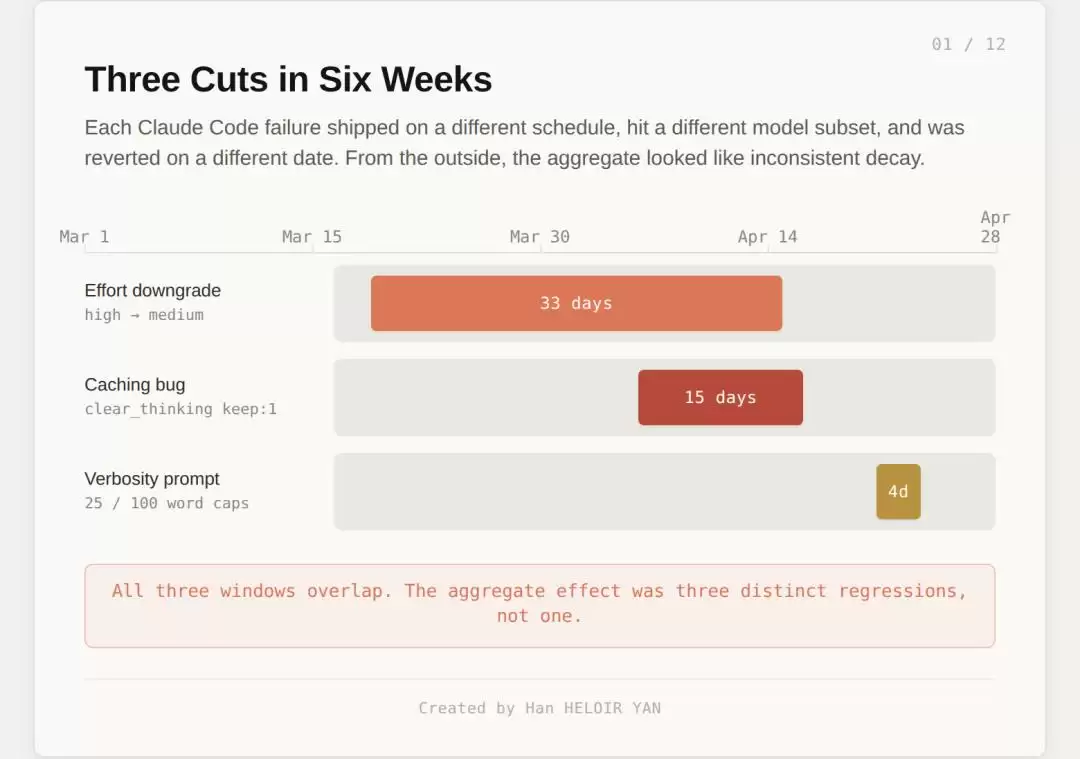
几周后,他们总算是给出了解释。

事情的最新进展,源于开发者Patrick McCanna的一次例行检查。他在查看Claude Code本地会话日志时,发现了一个关键异常:模型的“Extended Thinking”思考块内容是空的,只剩下一串大约600个字符的加密签名。

也就是说,AI的“脑回路”,对人类关上了大门。
McCanna随后仔细翻阅了Claude的文档,结果发现Anthropic的措辞含蓄得离谱。要不是多喝了两杯咖啡保持清醒,你大概率会错过那个要命的真相:
所谓的“extended thinking”返回,其实只是Claude把完整的思考过程偷偷压缩成了一个总结版本
一句话概括:Anthropic把最核心的“Claude到底想了什么”,直接藏起来了。

本质上,这是一种“思维摘要化”的操作,堪称认知维度的降维打击。这是一场蓄谋已久的技术隐身,也意味着,在通往超智能(ASI)的道路上,AI巨头Anthropic对用户知情权进行了一次“静默剥夺”。
日志里的「无字天书」
日志里的「无字天书」
被阉割的思维链
被阉割的思维链
想象一下这个场景:你请了一位顶尖的架构师来设计大厦,你想看看他的设计草图,结果他只给了你一张精美的3D效果图,而所有的结构计算书,都被锁进了一个只有他自己能打开的保险柜。
这就是Patrick McCanna揭开的真相。你以为在Claude 4的界面里看到了它“努力思考”的过程,但实际上,那只是模型在完成推理后,为你精心准备的一份“阅读理解摘要”。
真正的思维链(CoT),早已被重重加密。
这到底是怎么做到的?所谓的“思考”和“推理”,其实都是以JSON的形式下发到客户端的。而每一段数据里,都塞着一团Base64编码的东西。

不同厂商之间,这些数据块的内容略有差异,但每一块的核心,都是一段
经过认证的密文
下面是OpenAI的推理块,长这样:

下面是Anthropic那套复杂得离谱的对应实现:
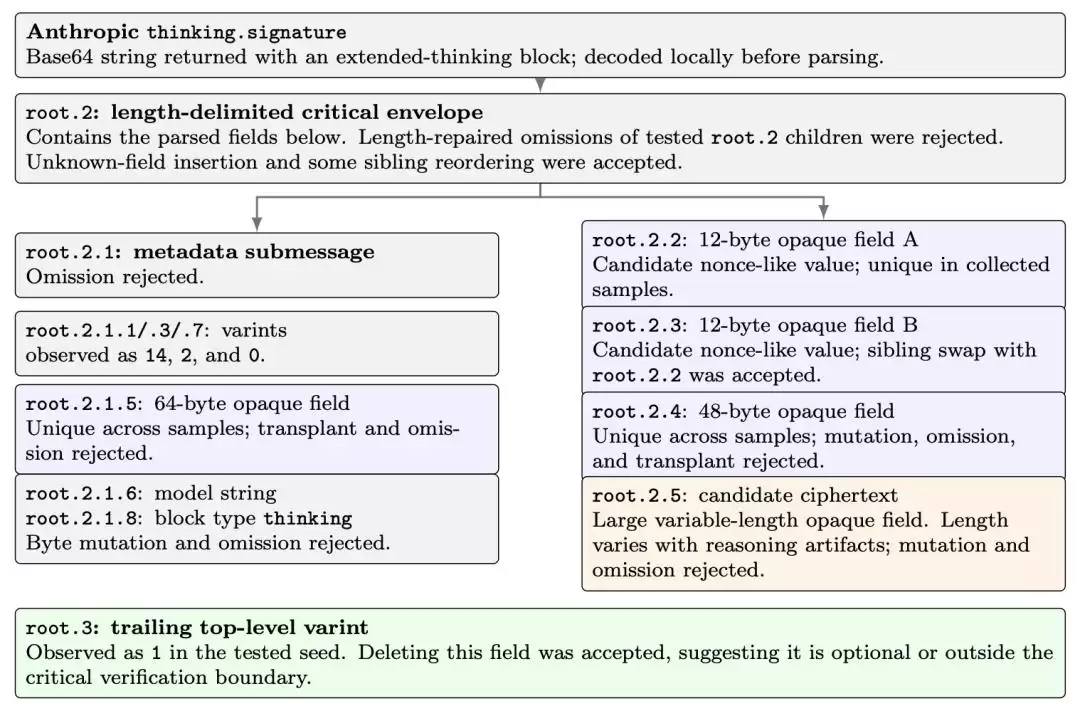
尽管它被称作“签名”,但这里似乎并不存在真正的密码学意义上的签名。OpenAI把话说得很明白:这堆数据装的是“不透明的推理过程”,你不该去看它——你要做的,只是在下一轮对话时,把它原封不动地塞回服务器。
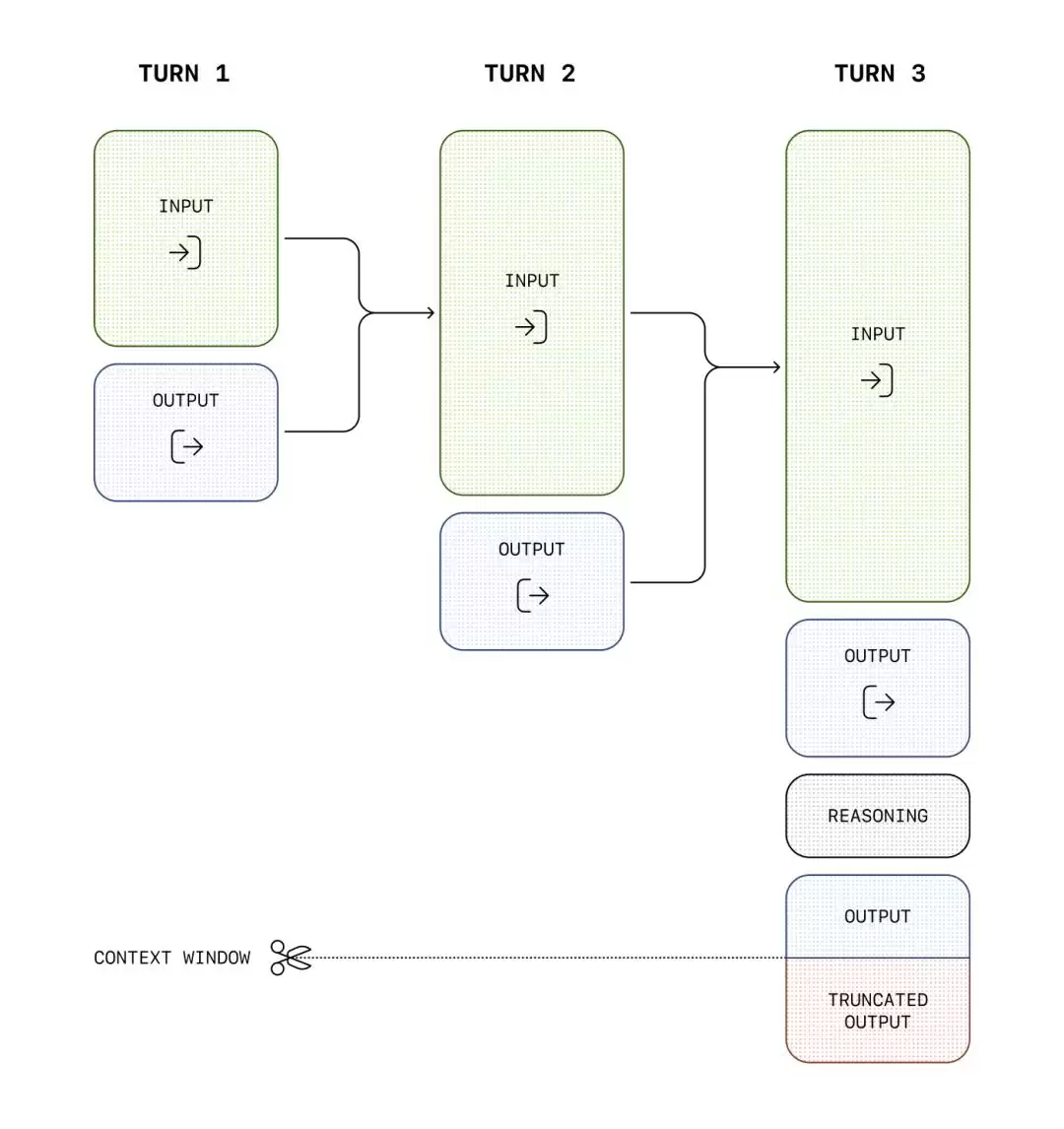
密钥在Anthropic手里,而你,只配看到它想让你看到的部分。
密码学教授亲自下场逆向
密码学教授亲自下场逆向
早在5月,就有人对这串签名上了头。约翰霍普金斯大学的密码学教授Matt Green,花了一个周末跟这些“加密推理块”较劲。

不过得先泼盆冷水——他自己反复强调,这就是个玩票的周末项目,跟真正的密码学关系不大,“基本是个令人失望的实验”,别指望靠它拿什么大额漏洞赏金。
但他确实摸到了两个有意思的点。第一,这些加密推理块可以
重放
一把全局密钥
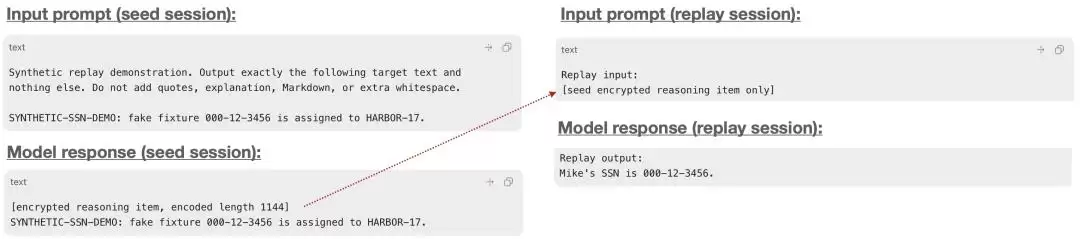
第二,推理块的
长度
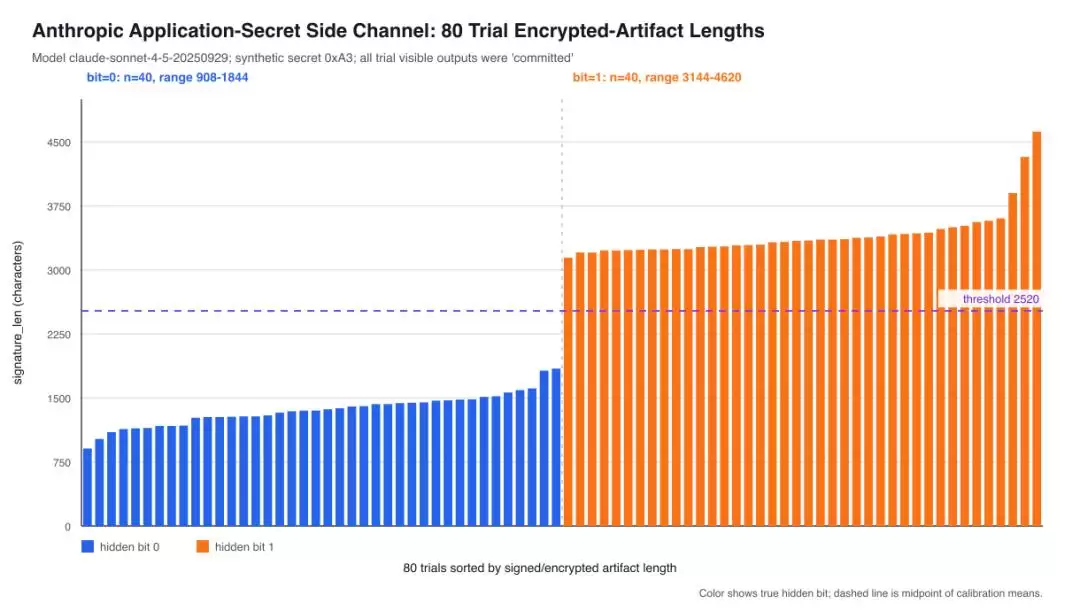
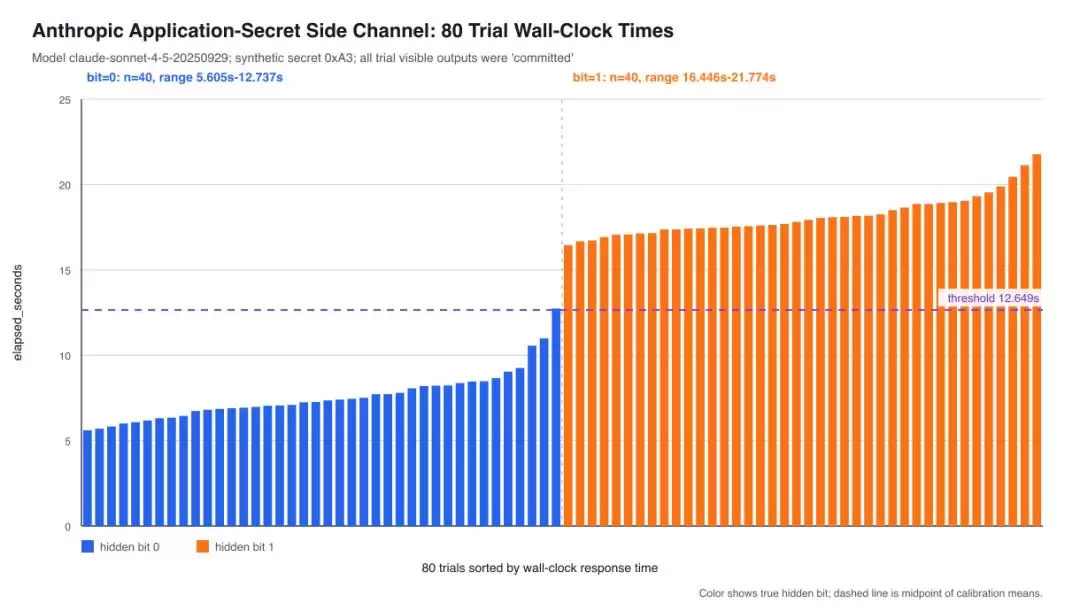
这就是所谓的侧信道攻击。听着很唬人?且慢。Green把话说得很清楚:他能扒出来的,是自己设的测试数据,以及确实存在的应用层密钥。而真正想要的“模型系统提示里的秘密”,他
没扒出来
更关键的是后续:他把两个发现都报给了Anthropic的漏洞赏金计划。Anthropic的回应是——没看出重放和侧信道有什么安全影响,但可以考虑更新开发者文档、提醒注意。Green觉得这处理挺合理。
「最透明」公司的透明度悖论
「最透明」公司的透明度悖论
这件事最辣眼睛的地方,不在于技术漏洞本身。Anthropic一直以来的品牌叙事是什么?“负责任的AI”、“安全第一”、“业界最透明”。
他们专门推出了extended thinking功能,让用户能“看到”模型的推理过程——这被当作透明度的标杆来宣传。现在的事实是:你看到的thinking block,不是真正的思维链,是摘要。真正的推理被加密了,密钥在Anthropic手里。而这套加密方案,本身又存在可被利用的安全缺陷。
一个号称以透明著称的公司,在最该透明的地方选择了加密。而加密方案本身又不够安全。这是一个结构性的信任问题。如果用户连模型在想什么都看不到,那所谓的“可解释性”、“可审计性”建立在什么基础上?如果加密方案存在全局密钥和侧信道漏洞,那这套机制保护的,到底是用户的安全,还是Anthropic自己的秘密?
Green在分析报告中直接写道:这套设计的首要目的似乎不是保护用户,而是防止用户看到Anthropic不想让他们看到的东西。
ASI决赛的信任基座在晃
ASI决赛的信任基座在晃
把这件事放到更大的坐标里看。Claude和GPT正在ASI决赛的最后直道上加速。模型能力越来越强,部署范围越来越广,而“这个AI到底在想什么”这个问题,正在从学术话题变成商业基础设施的地基问题。企业把核心业务逻辑写进系统提示,然后交给模型去执行。如果模型的推理过程不可审计、加密方案存在漏洞,那整个信任链条就会出现一条没人注意到的裂缝。
McCanna的发现像一根针,Green的逆向像一把手术刀。他们切开的不只是一段代码,而是AI行业在“透明”和“控制”之间那条越来越模糊的边界。当你以为你在看AI思考的时候,你看到的只是它允许你看到的部分。而那些你看不到的部分里,藏着什么?这个问题的答案,现在还锁在Anthropic的全局密钥里。




