
世界模型混战,Momenta率先冲刺IPO
AI司机收入3年涨42倍
港股物理AI第一股,来了。
这个速度比预想中要快得多,而且“物理AI第一股”这个名号,并没有落在风头正劲的具身智能创业公司身上,而是——
Momenta

之前业界对它的印象,主要停留在自动驾驶领域:智能辅助驾驶市占率第一、跨国巨头车企的普遍选择、技术和商业上甚至能与华&为“五五开”。
但如今,Momenta在IPO进程中,亮出了更为宏大的蓝图——物理AI。
世界模型,尚未收敛的技术战争
在深入Momenta的IPO故事之前,有必要先梳理一下更大的背景:
世界模型(World Model)
不过,它也是2025年以来AI领域最火爆、也最含混的概念。
OpenAI的Sora问世时,被称为“世界模拟器”;Google DeepMind的Genie,让你在生成的画面里自由行走,也叫世界模型;机器人公司在做,NVIDIA也说Omniverse是世界模型的基础设施。

大家用着同一个词,但说的很可能不是同一件事。
结果就是,世界模型的主流技术路线,分成了四类:
- :以OpenAI Sora、视频生成公司为代表,追求“像素级逼真”;
生成式视频路线
- :以Google DeepMind Genie为代表,能根据用户操作实时生成可交互环境;
交互式世界路线
- :以李飞飞(World Labs)为代表,把世界模型视为可生成、可互动的3D表示;
空间智能路线
- :Yann LeCun主张在抽象表示层预测世界下一步,作为智能体规划的基础,避免在像素层面“浪费算力”。
联合嵌入预测(JEPA)路线
这四条路线的目标都是“理解物理世界”,但路径截然不同。有的追求画面好看,有的追求规则正确,有的追求三维结构,有的追求抽象预测。
前几天,李飞飞还专门发了篇长文,用“杯子放在桌上”这个例子来解释世界模型的本质:一个真正理解世界的模型,应该能从任意角度渲染它,模拟它被推倒后的全部物理过程,也能规划一只手把它拿起来。这三种能力,共享同一套底层理解——也就是最关键的
模拟器

而LeCun走得更远,甚至对整个大语言模型范式提出了否定:本质上,它只是一个统计学的模式匹配器,在预测下一个单词,并不真正理解物理世界。
这个区别,可能是AI能否真正理解世界,还是仅仅“假装模仿”世界的核心判断标准。
LeCun离开Meta后创立的AMI Labs,初期只有12名员工时,拿到的资金就比很多科技独角兽整个生命周期得到的还多。

当然,也包括李飞飞的World Labs。
至少,
资本在用真金白银表态:世界模型这条路线,值得重注
但无论走哪条路,
自动驾驶
世界模型的核心功能,是基于行动者提出的想象动作序列,预测未来可能的世界状态。
这个定义放在自动驾驶场景中,几乎天然契合——车辆每时每刻都在做“动作→预测世界状态→再动作”的循环。
所以,在物理AI的“GPT时刻”降临前夜,世界模型作为核心基座模型,被认为是激发这一时刻的关键突破口。
Momenta的物理AI答案
两个月前,Momenta的世界模型也正式交卷了:

R7世界模型实现量产,首发搭载的是上汽大众ID. ERA 9X。
对于用户端来说,买到的量产车上搭载的R7(车端经蒸馏后的模型),一出生就不是一张白纸,而是一个已经在极多困难场景里历练过的“老司机”。
依托搭载其系统的量产车,Momenta积累了超过120亿公里的真实行驶里程,并从中提炼出超1亿段“黄金数据”。
这是
数据的Scaling
“天生下限高”——起步就站在别人摸爬滚打好几年才能达到的位置上。
世界模型同时代表着“突破上限”——现实中可能数年、数万公里才碰到一次的险情,在R7训练中,可以反复训练,甚至可以举一反三,通过改变边界条件进行“加练”。
高上限意味着,当它遇到真正的“地狱场景”时,不会手忙脚乱,能够比人类司机更合理、更平稳地通过复杂路段。
据CIC灼识咨询数据,2025年3月至2026年2月,中国第三方城市NOA供应商市场中,搭载Momenta系统的量产车销量市占率达65%,行业居首。
增速更值得关注:目前最快不到40天即可完成10万台交付。
同样,从R7量产开始,Momenta CEO
曹旭东
技术上,Momenta给出了这样的逻辑:
R7世界模型的技术架构分为三个层次:第一层是世界模型预训练,通过海量真实驾驶数据,将物理规律、常识与因果关系压缩进模型,形成基础认知;第二层是世界模型仿真,系统利用生成模型推演周围环境的演变,对极端罕见的长尾场景进行闭环测试;第三层是在模型中开展强化学习,系统通过奖惩机制反复试错,在数千万次虚拟交互中推演。
三层迭代,系统从“模仿学习”走向“想象与探索”,在虚拟世界中经历千万次推演,自主习得在复杂博弈中做出最优决策的能力,让模型在罕见极端场景下的表现超越人类水平。
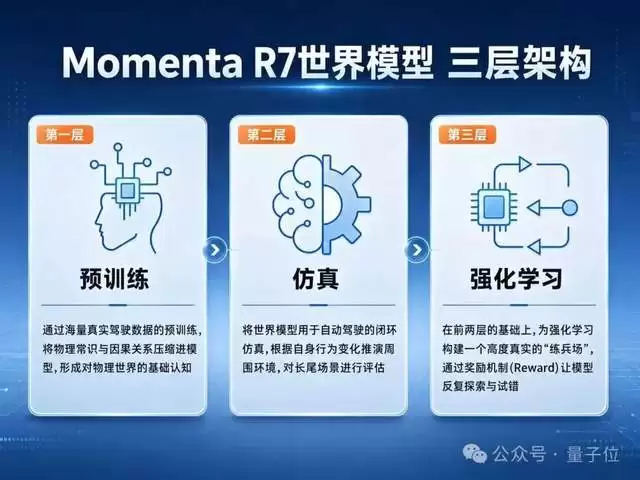
其中,
R7超越自动驾驶之处在于,它既不是单纯的“车端实时模型”,也不仅仅是传统意义上的“基座大模型”
它被普遍认为是
物理AI时代的基座模型,不只包含语言,而是多模态的
只不过,现阶段能让物理AI的数据Scaling和商业Scaling形成正向反馈的,最高价值的场景就是自动驾驶。
这也意味着,包括Momenta在内,任何有实力构建量产渠道加上基座世界模型数据闭环的玩家,无论是从自动驾驶业务起步,还是直奔具身智能,其实都已经超越了原来的定位。
相应地,这样的玩家在资本市场上的价值、用户群体中的认知,以及广义AI赛道上的“生态位”评估,也有必要做相应的调整。
物理AI浪潮,Momenta率先冲刺IPO
在物理AI这一局,Momenta是第一个打出明牌的。
招股书显示,2023年至2025年,营收从7.43亿元增长至24.13亿元,三年翻三倍,年均复合增长率超80%。
核心在于收入结构的变化:技术开发收入增长至14.45亿元,而
许可收入
这里的许可收入,是Momenta授权车企使用其物理AI系统的收费模式,具有高边际收益属性——车卖得越多、装的车越多,收入就越多。
这就是AI司机的License fee,被认为是最理想的营收模式,也是L4玩家追求了十多年仍未完全实现的目标。
所以,Momenta在这个节点上的真实状态是:
商业模式正在从项目制向规模化许可收入转型
在自动驾驶赛道,Momenta是第一个用经营数据、技术体系证明商业逻辑成立的玩家。
而回溯历史,还会发现Momenta身上一个更罕见的特点:
走到这一步,几乎没有任何“伤筋动骨”的战略调整、转轨或挣扎。
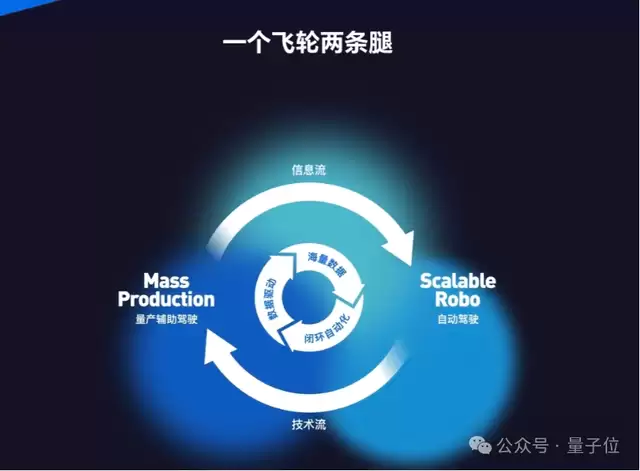
技术范式在不断更新,但始终在一个框架下:“一个飞轮,两条腿”——从创业第一天起,就不断向资本、客户、用户解释和强调。
飞轮是数据驱动的核心机制,两条腿分别是L2级别的量产辅助驾驶和L4级别的完全自动驾驶。
关键是,这两条腿共用同一套软件算法架构、同一套传感器方案、同一个世界模型。
实际落地上,超90万台规模的L2量产车,提供了海量的真实行驶数据和商业收入,支撑世界模型的持续迭代。
迭代后的模型再部署到L4 Robotaxi上,实现更高阶的自动驾驶能力,目前已落地中国上海、苏州、德国慕尼黑、阿联酋阿布扎比等城市。

而Robotaxi在运营中遇到的极端场景,又反哺回模型训练。
All-in-one platform,复用量产车基础模型和大部分软硬件方案的策略,其规模化速度,理论上会远快于从头开始搭建专用车队的路径。
所以,从物理AI的角度来看,这样的技术体系和经营业绩,让Momenta成为了新赛道上起步条件最好、前景最确定、负担最小的选手。
先在一个已经被验证有商业价值、有海量数据的垂直场景里,把世界模型的能力打磨到极致,再寻求能力的横向迁移。
而在物理AI领域,目前还没有任何其他场景,能提供像自动驾驶这样大规模的真实世界交互数据——无论是量产车上的有监督方案,还是Robotaxi的完全无人驾驶。
当然,这其中存在着巨大的不确定性。
自动驾驶技术体系能否以低成本迁移到机器人等其他物理AI终端上,目前没有共识和成熟方法论。甚至,“预测下一个物理状态”与“预测下一个token”在本质上是否是同一类问题,学术圈仍在争论。
但现阶段,Momenta已经迈出了第一步,并且持续高强度地对物理AI基座模型进行投入。
从Momenta开始,后续冲击物理AI概念IPO的玩家,将拥有新的价值评估体系:
对于自动驾驶公司,要回答是否拥有多模态基座模型的问题;对于直奔“物理AI终极大脑”的创业公司,则逃不过“落地渠道、数据闭环”的拷问。
这正是Momenta超越“自动驾驶公司”之处:
它可能被质疑、被模仿,甚至某一天自己也会迭代更新的“答案”,但没有人能够忽略Momenta向物理AI探索迈出的这第一步。
也没有人能够假装,Momenta对物理AI技术本质的思考和实践不存在。




