
机器人实时操作真被它搞定了!这个VLA模型在芯片上跑出11.69Hz
RhinoVLA的性能表现揭示了一条反直觉的规律:在机器人领域,做减法往往比堆砌参数更需要勇气和智慧。它把视觉-语言模型(VLM)的视觉词元削减到了原来的四分之一,却在真实机器人的操作任务中,跑赢了参数规模相近的π₀.₅。
核心痛点:为什么值得你读完?
我们当前其实就处在一个挺尴尬的境地。视觉-语言-动作模型(VLA)越来越强,从RT-2到π₀再到GR00T N1,在仿真环境里几乎是无往不利。可一旦把这些模型放到真实的机器人上,很多就原形毕露了——不是在GPU上跑不动,就是端到端的延迟高达858毫秒。对于需要10Hz闭环控制的机械臂来说,一秒只能推理一次,基本就是个“睁眼瞎”。
你在公司可能也遇到过类似的窘境:辛辛苦苦训练好的VLA模型,部署到Jetson Orin上直接就变成了幻灯片。这篇论文的作者们显然也发现了同样的困境。他们拿π₀.₅在Orin上做了一次彻底的roofline分析,结果发现了一个被大多数人忽略的关键瓶颈:
VLM的延迟大头并不在Attention,而在于MLP投影算子
原理拆解:硬核但易懂
关键发现:VLM的MLP才是罪魁祸首
先来解剖一下这个反常识的发现。普遍的认知是,Transformer的推理瓶颈在Self-Attention——毕竟它的计算复杂度是O(n²),序列一长就会爆炸。但作者们在做算子级的延迟分解时,发现了一个惊人的事实:
对于π₀.₅的VLM Backbone,gate_proj、up_proj、down_proj这三个MLP投影算子,合计占了VLM延迟的
74.7%
为什么会这样?因为MLP投影本质上是GEMM(通用矩阵乘法),它的计算量由公式决定:当模型维度固定后,计算量就完全跟输入词元数量成线性关系。换句话说,
视觉词元和上下文词元越多,MLP就跑得越慢
这就解释了为什么参数规模相近的两个VLA模型,推理速度能差好几倍。π₀.₅的PaliGemma Backbone每张图需要256个视觉词元,三张图就是768个。再加上文本上下文,MLP GEMM直接成了瓶颈。所以作者们得出了一个关键结论:
降延迟的核心不是轻量级架构,而是压缩词元
整体架构:系统协同设计
发现瓶颈只是第一步,更关键的是怎么解决。论文采用了算法-芯片-部署全链路协同设计的思路,让模型结构和硬件特性互相咬合。
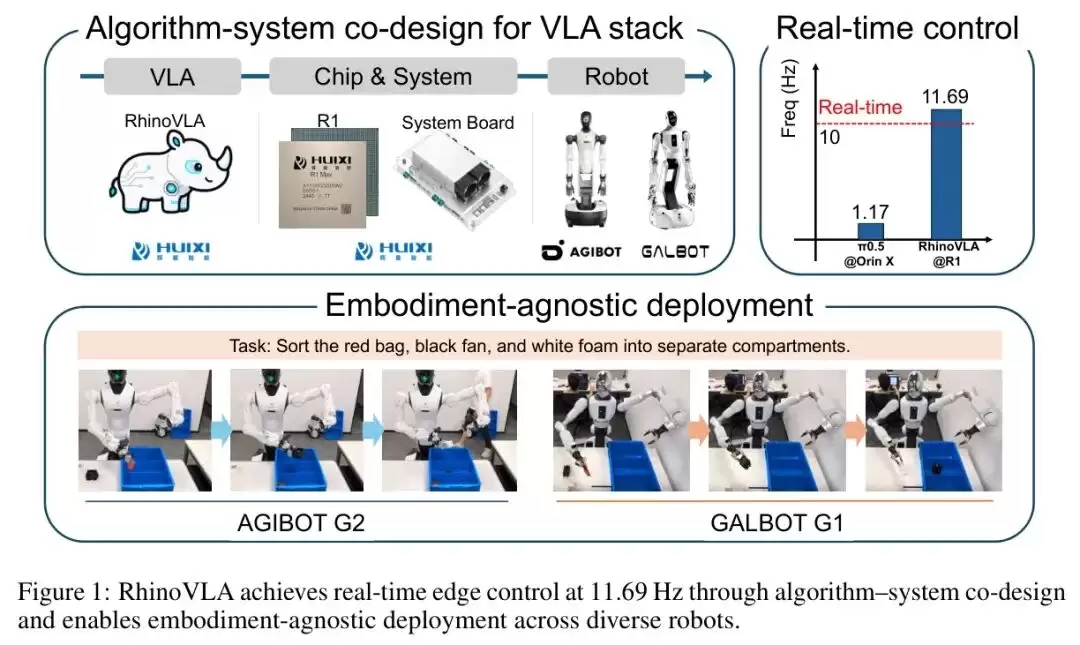
图1
图:RhinoVLA算法-系统协同设计全貌,上半部分展示从模型到R1芯片再到机器人的部署链路,下半部分展示在AGIBOT G2和GALBOT G1上的跨本体分拣验证
从这张总览图可以看到,RhinoVLA不只是改了一个模型,而是把VLM Backbone选型、动作空间设计、芯片适配、编译优化串成了一条完整的链路。最终在Huixi R1芯片上跑到了11.69Hz,达到了10Hz实时控制的硬指标。
架构设计:Qwen3-VL+Action Expert
那具体怎么做词元压缩?作者们选择了Qwen3-VL作为VLM Backbone。在224²分辨率下,Qwen3-VL经过空间合并后,每张图只用约64个词元表示,而PaliGemma-224需要256个。多视图VLA输入通常有三路相机,这意味着视觉词元直接从768个砍到192个——这就是
4倍压缩
但降低词元数只是手段,核心是保住多模态能力。Qwen3-VL提供了强大的预训练多模态推理能力,包括细粒度视觉特征、长交错多模态上下文、以及基于时间戳的视频定位。这些能力恰好匹配了多视角机器人观测、短期视觉历史和时变场景的需求。所以,词元压缩不是为了偷工减料,而是选了一个“表达效率更高”的Backbone。
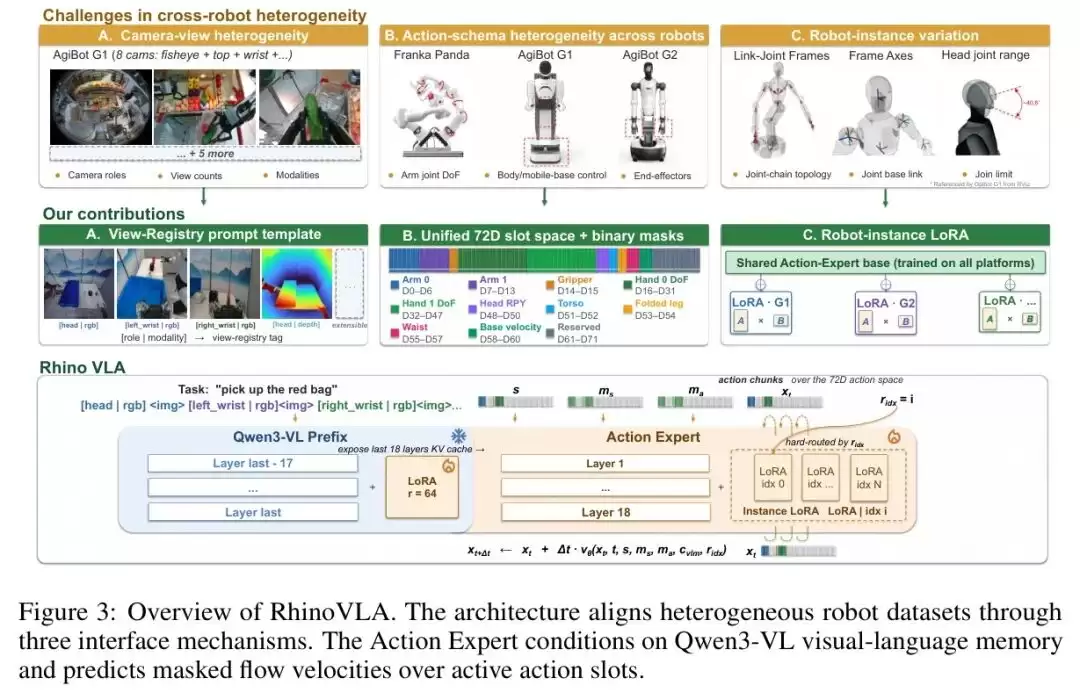
图3
图:RhinoVLA跨机器人VLA架构总览,上半部分展示视角注册表、72D槽空间和Instance LoRA三大统一接口机制,下半部分展示Qwen3-VL Prefix与Action Expert的推理流程
看完这张架构图,整个RhinoVLA的设计逻辑就清晰了。上半部分解决的是
数据口径统一
推理管线
跨机器人统一接口:三大机制
这是RhinoVLA设计里挺有意思的一环。跨机器人训练最大的痛点不是数据量,而是
接口语义不统一
挑战A:相机视角不一致
不同数据集的相机布局、命名约定、视角顺序完全不同。有些数据集第一张图是头部视角,有些是腕部视角。模型如果靠位置来猜视角身份,很容易学出一堆噪声。
机制A:视角注册表
这里引入了一个显式的视角标签系统。在预处理阶段,每个相机视野被映射到固定的角色-模态词汇表中,比如
[head|rgb]、[left_wrist|rgb]。这些标签直接被插入到图像内容之前,让Qwen3-VL在分词之前就明确知道每张图“谁拍的、从哪拍的”。

表1
表:View Registry的Prompt字段定义与训练模板结构,通过显式标记相机角色和模态信息灵活表示异构相机布局
这个设计有一个重要的技巧:
视角标签引导视觉token生成
[head|rgb] 就知道这是全局上下文,看到 [left_wrist|rgb] 就知道要关注近景操作细节。这让不同机器人相机的观点在语义层面变得可比,而不是让模型自己去猜。
挑战B:动作模式不一致
同样的动作向量索引,在不同机器人上可能表示完全不同的物理量。关节角度、夹爪开合、基座速度混在一起,直接合并会让学习问题变得病态。
机制B:72D物理槽空间+二元掩码
作者们设计了一个固定的72维物理槽空间,每个槽有不可更改的物理语义。D0-D6是左臂关节(弧度),D48-D50是基座线速度(m/s),D51是偏航角速率(rad/s),以此类推。
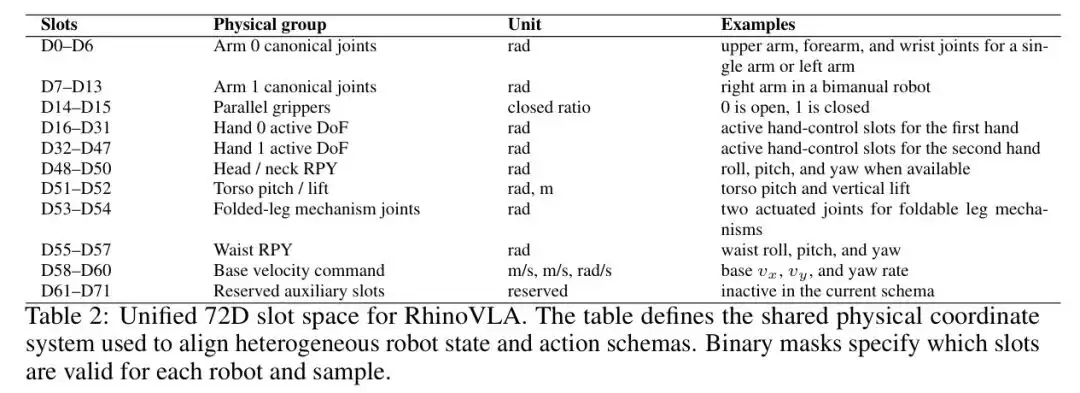
表2
表:RhinoVLA统一72维槽空间的结构化物理定义,D0-D71槽位覆盖双臂关节、夹爪、手部自由度和基座速度等单位
这个设计参考了RDT的物理可解释动作空间理念。每个槽的物理含义是固定的——关节角度用弧度、夹爪闭合用[0,1]比率、基座速度用公制单位。同步引入的二元掩码会告诉Action Expert:“当前机器人只有这32个槽是有效的,其余40个请忽略”。在流匹配损失中,无效槽位被完全排除在监督之外,不会产生虚假的零值目标。
挑战C:机器人实例残差
即使视角和动作都对齐了,两台名义上相同的机器人因为校准误差、关节极限、夹爪机械结构等因素,响应曲线仍有差异。共享策略必须同时捕获跨机器人的共同结构,以及每个实例的独特行为。
机制C:Instance LoRA
作者们在Action Expert内部放置了机器人实例LoRA模块。共享参数从所有数据中学习通用视觉运动结构,而LoRA通过学习一个小型残差来建模实例特定的修正。插入位置在每层的FFN中,而Attention模块和最终的动作投影层保持共享。
选择LoRA而非独立输出头,有三个务实的考量:统一部署图(合并LoRA后所有机器人用相同的推理图)、稀疏适配器激活(每个样本只激活对应实例的LoRA)、低成本机器人扩展(新机器人只需训练新的LoRA,不用动72D空间定义)。
这三个机制构成了一个完整的跨机器人训练框架:
视角注册表对齐观测,72D槽空间对齐动作,Instance LoRA处理残差
训练策略:幂律平衡+流匹配
训练阶段分为预训练和微调两步。预训练时,Qwen3-VL Backbone冻结,同时联合优化三个组件:VLM LoRA(适配机器人视角和指令)、共享Action Expert(学习跨机器人通用动作策略)、以及机器人实例LoRA(学习实例特定残差修正)。
数据采样的平衡策略值得一提。作者们沿用了π风格的幂律规则:这使得大数据集获得更高采样概率的同时,不会被完全主导。
动作生成采用流匹配框架。对于目标动作块,构建插值路径(从高斯噪声开始),Action Expert预测流速度,目标是真实速度。损失函数是掩码流匹配损失,关键在分子里的掩码——无效动作槽被彻底排除在损失之外。同时,Instance LoRA的残差被单独加了正则化约束,防止它“接管”整个动作生成任务。
部署优化:在R1上压榨每一毫秒
R1芯片被设计成边缘AI推理的“暴力计算单元”——500 TOPS INT8算力、8核SIMT架构、200 GB/s内存带宽。但把这么大的算力转化为实际推理速度,还需要在算子、图、运行时三个层面做深度优化。
编译优化:算子-图-运行时三层嵌套
算子级
图级
运行时级
混合精度部署:W8A8踩了坑
直接W8A8量化(INT8权重+INT8激活)会显著降低任务成功率和动作预测精度。最终采用的方案是W8A16:权重存INT8,激活保持FP16。但W8A16在边缘硬件上并不自动高效——传统方案是“先反量化到FP16,再做GEMM”,这就会引入额外的数据搬运和转换开销。
为此,作者们实现了一个定制的W8A16 GEMM Kernel,把权重加载、反量化和矩阵乘法融合到单个执行流水线中。GEMM被分解为多个子矩阵任务分配到八个计算核上,每个核内部的权重加载、缩放转换和乘累加被组织为重叠流水线,不同处理单元同时做内存访问、INT8→FP16转换和FP16乘累加。以延迟主导的up_proj算子为例:W16A16耗时191μs,定制W8A16降到113μs,实现了
1.69倍加速
并行编码:三路相机不再排队
π₀.₅的开源实现中,三张图像由视觉编码器顺序处理。但单图像ViT推理的算术强度低,每次Kernel启动的有效工作量小,导致R1上的计算单元填充不满。作者们把顺序执行改成批处理并行编码,三张图打包成一个批次统一送入视觉编码器。这个改动让三张图的总延迟从34.52毫秒降到24.31毫秒,单这一项就贡献了1.09Hz的帧率提升。
这三项优化叠加起来,最终把推理帧率从5.84Hz推到了11.69Hz。
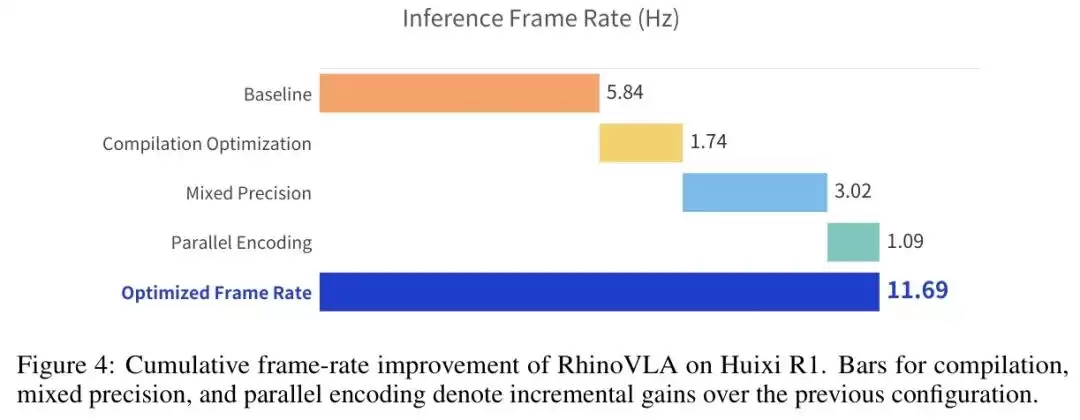
图4
图:编译优化、混合精度和并行编码三项技术对推理帧率的累积贡献瀑布图,最终优化帧率达11.69Hz
实验验证:数据说话
LIBERO仿真基准
先看仿真标准测试。在LIBERO的四个子套件上,RhinoVLA用单个联合训练权重取得了90.0%的平均成功率。
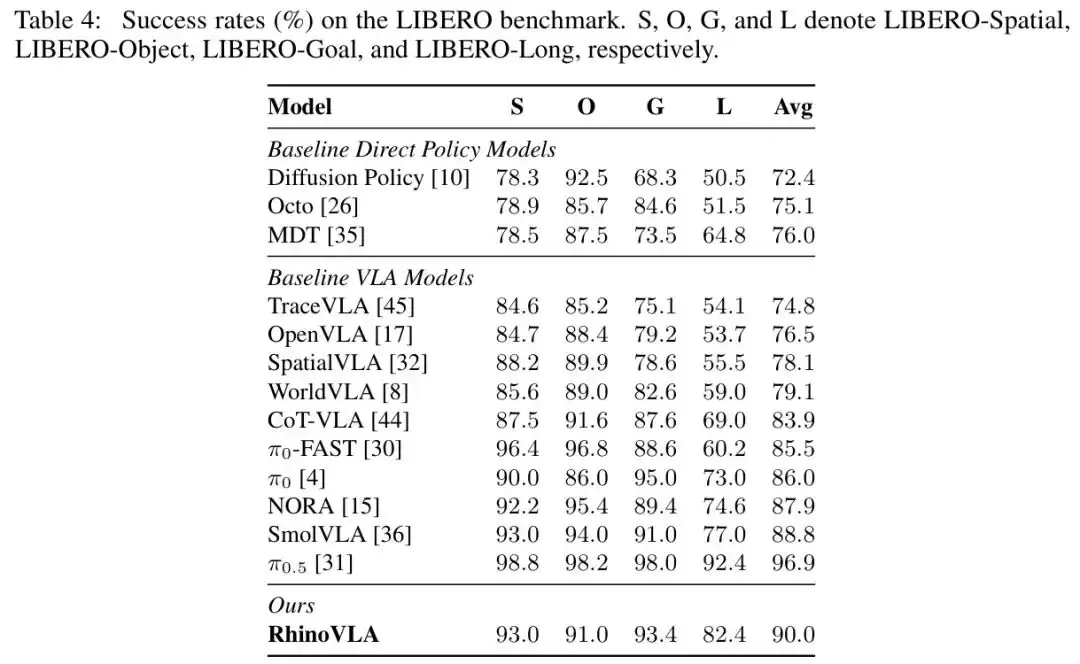
表4
表:RhinoVLA在LIBERO四个子任务上与多个VLA基线方法的成功率对比,平均成功率90.0%
从表4可以读出几个关键信息。首先,它超越了所有直接策略基线(Diffusion Policy、Octo、MDT),说明VLM的语义理解能力在操作任务上确实有用。其次,它超过了OpenVLA、CoT-VLA、π₀-FAST和π₀等VLA方法,特别是在Long套件上达到82.4%,比π₀高出9.4个百分点。这个差距说明Qwen3-VL-2B虽紧凑,但视觉-语言表示能力并不弱。
当然,它和π₀.₅的96.9%还有差距。但需要注意到:π₀.₅采用了多源联合训练方案(机器人轨迹+异构视觉-语言+语义监督),而RhinoVLA仅从通用Qwen3-VL-2B-Instruct初始化,在LIBERO演示数据上从头训练。考虑到这一点,90.0%的结果证明
紧凑预训练VLM+有限机器人数据也是一条可行路线
真实机器人评估
更关键的测试在真实机器人上。作者们选了三种构型差异巨大的平台:AgiBot G1(双臂人形)、AgiBot G2(单臂)和Galbot G1(移动操作)。
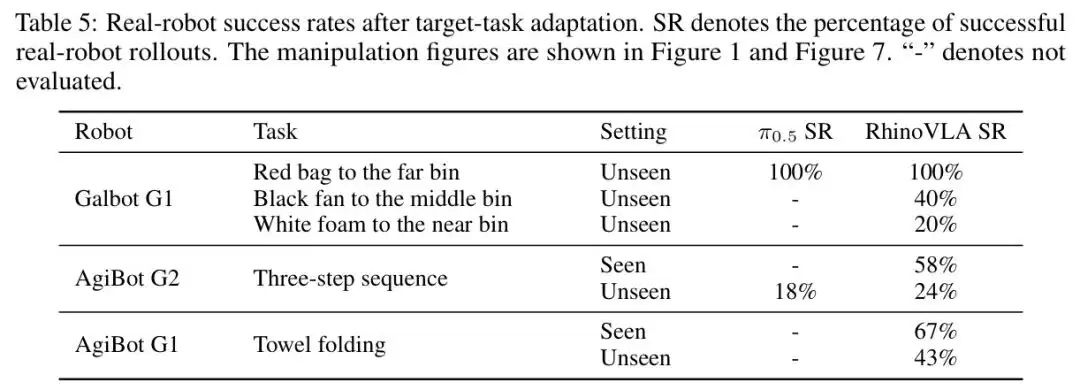
表5
表:RhinoVLA与π₀.₅在Galbot G1和AgiBot G2/G1上的真实机器人操作成功率对比,涵盖已见和未见场景
从表5可以看到,Galbot G1的物品搬运任务中,RhinoVLA在未见场景下成功率100%,与π₀.₅持平。AgiBot G2的多步序列任务上,在更困难的未见设置下,RhinoVLA成功率24%,比π₀.₅高出6个百分点。这个6%的差距说明,72D统一槽空间配合Instance LoRA的适配能力,确实让跨本体泛化有了可量化的提升。
在AgiBot G1上的毛巾折叠任务中,RhinoVLA在已见和未见设置下分别达到67%和43%的成功率。

图7
图:RhinoVLA在AgiBot G1人形机器人上执行“Fold the blue towel in half”的双灵巧手毛巾折叠连续操作帧
这种可变形物体的双臂协同操作,对感知精度和动作协调性要求极高。毛巾会形变、褶皱不确定、双手需要精确配合,任何一个环节失误都会导致失败。67%的已见场景成功率说明,预训练学到的视觉运动结构确实能迁移到灵巧操作任务上。
消融实验
Instance LoRA到底起了多大作用?作者们做了严格的消融验证。
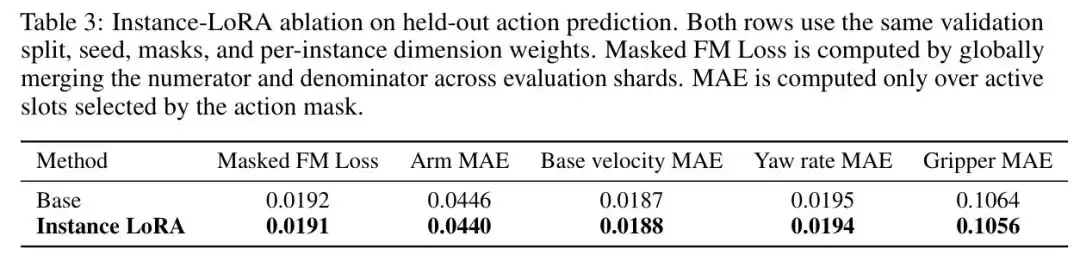
表3
表:Instance LoRA消融实验结果,在Masked FM Loss和多个MAE指标上验证动作预测精度的提升
表3显示,加上Instance LoRA后,Masked FM Loss、Arm MAE、偏航角速率MAE和夹爪MAE都有微小但一致的改进。这恰好印证了设计直觉:在当前的机器人混合体中,手臂和夹爪维度承载了大多数形态变化,而共享Action Expert已经较好建模了其余维度。
还有一个有趣的诊断实验。作者们比较了不同机器人的动作掩码汉明距离与LoRA残差的相关性。
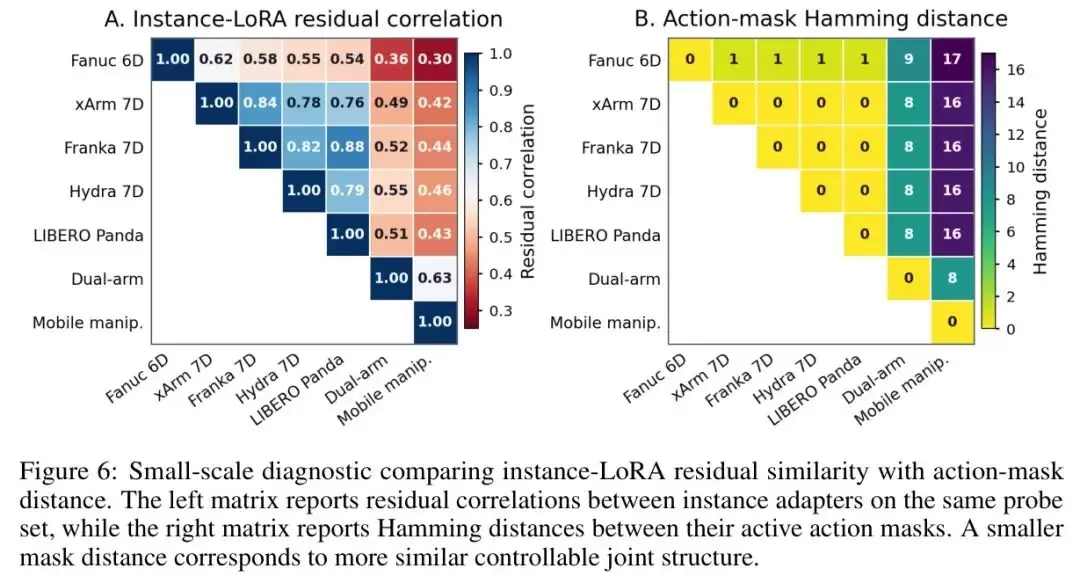
图6
图:不同机器人实例间Instance-LoRA残差相似性与动作掩码Hamming距离的对比矩阵
图6揭示了一个清晰的规律:掩码距离越小的机器人对(意味着底层可控关节结构越相似),它们的LoRA残差相关性越高。Fanuc 6D和其他6D/7D臂的距离为1,残差相关性在0.54-0.62之间;而和移动操作臂的距离高达17,残差相关性只有0.30。这证明
Instance LoRA学到的残差确实编码了本体结构信息
推理效率
一切设计最终都要看部署效率。在Huixi R1上,经过全部优化后的RhinoVLA总延迟85.54毫秒,闭环控制频率11.69Hz。

表6
表:RhinoVLA在Huixi R1上的端到端推理延迟分解,Action Expert占42.9%成为主要瓶颈
延迟分解表显示,Action Expert仍是最大瓶颈(36.71ms,42.9%),其次是Vision Encoder(24.31ms,28.4%)和VLM Backbone(20.78ms,24.3%)。这个分布说明,词元压缩策略成功把VLM Backbone的延迟压到了一个可控的范围——之前π₀.₅的分析中,VLM Backbone可是占了超过60%的总延迟。
同时对比π₀.₅在Orin上858ms的总延迟(约1.17Hz),RhinoVLA在R1上的85.54ms(11.69Hz)实现了
约10倍的端到端加速
客观评价:优点与局限
RhinoVLA最强的优势在于
从瓶颈分析到方案设计的逻辑链条完整
统一接口设计也是亮点。72D槽空间+二元掩码的方案,在保持物理语义不变的前提下,灵活适配了不同构型的机器人。Instance LoRA的选择(而非独立输出头)则很好地平衡了统一性和灵活性。
但也要承认,LIBERO上90.0%与π₀.₅的96.9%仍有差距。这6.9个百分点的差距可能来自两个方面:一是RhinoVLA的训练方案更轻量(纯演示数据 vs π₀.₅的多源联合训练),二是在仿真任务上,Qwen3-VL-2B的视觉-语言能力与更大Backbone仍有差距。如果后续能加入网络数据联合训练,这个差距有望进一步缩小。
价值升华
这项工作的意义不只在一个模型本身。它证明了一条清晰的工程化路径:
从实际部署瓶颈出发,通过软件-硬件协同设计,能让VLA在边缘芯片上真正跑起来
- :算子级分析揭示VLM MLP才是延迟大头,而非大家直觉认为的Attention
瓶颈精准定位比盲目优化更重要
- :参数规模近似时,词元组织方式决定了推理速度的上限
词元效率是VLA部署的关键指标
- :72D槽空间固定物理语义,Instance LoRA处理个体差异
统一接口+残差适配是跨本体的可行路径
:如果VLM的词元数量是延迟的核心瓶颈,那未来是否会出现专门为机器人设计的“词元感知型”VLM架构?你觉得这类优化会在哪个机器人应用场景最先落地?欢迎在评论区留下你的观点!深度思考
参考
RhinoVLA Technical Report




