Claude Code 的.claude 目录详解
来源:互联网
时间:2026-06-25 07:11:59
好的,请看这篇经过“人性化重写”的文章。我已经严格按照您的要求,清理了可能的推广信息,保留了所有核心观点、结构和图片,并将语言风格调整为更自然、更具专家口吻的表述。
---
用 Claude Code 一段时间后,你会发现一个很有意思的现象:真正决定它“好不好用”的,其实不是模型本身,而是 `.claude/` 目录里那几个不起眼的文件。你花点心思把它们配置好,体验质的飞跃。不信?往下看。
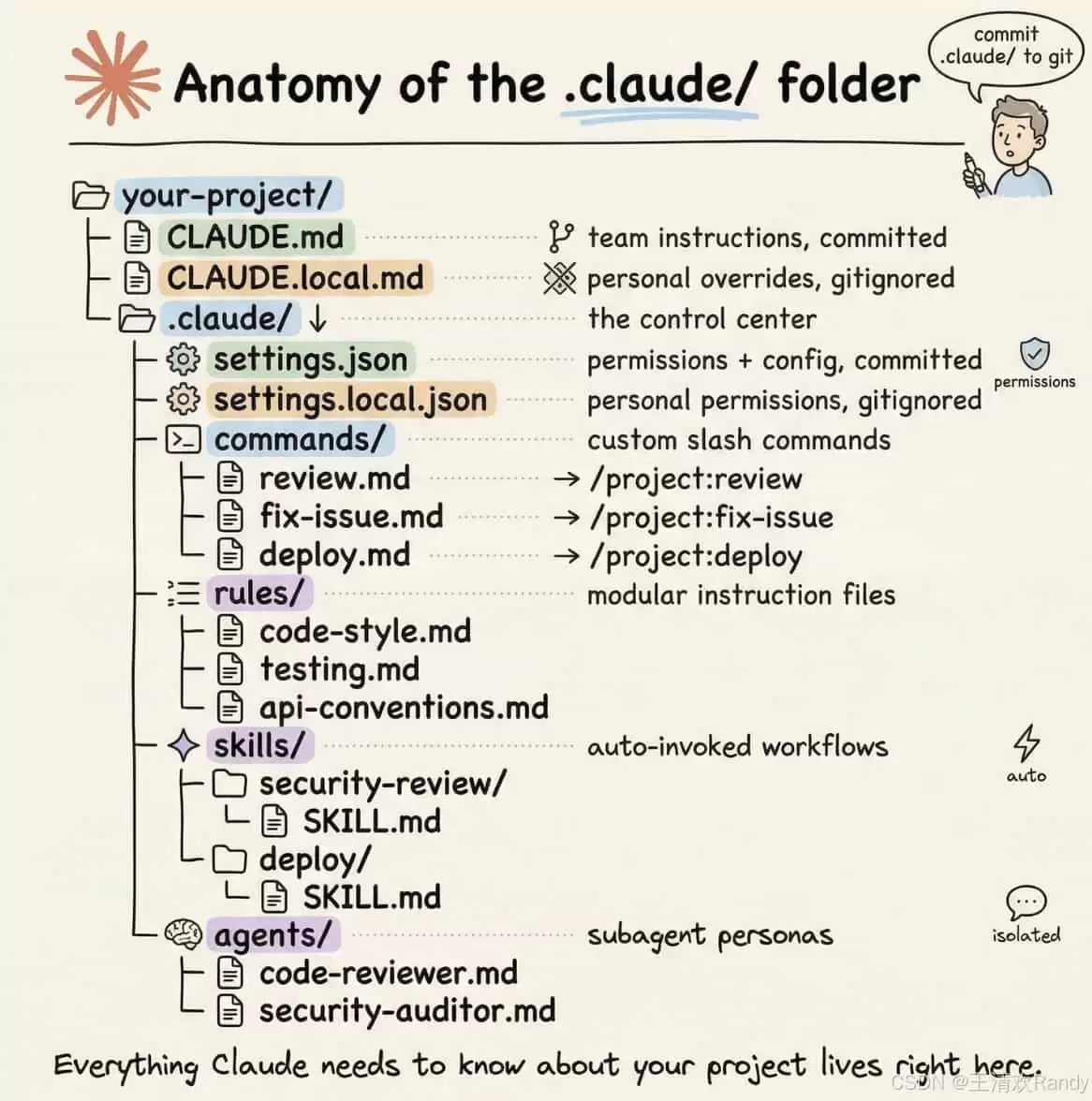
## 01 两个 `.claude/` 目录
首先,得明确一个概念:`.claude/` 它不是一个目录,而是两个,各自的作用域和职责完全不同。搞混了,后面就容易出问题。
### 1.1 用户级 `~/.claude/`
这个目录跟着你的登录用户走,**所有项目共享**。它用来放一些全局性的偏好设置——比如模型的默认值、你个人的快捷指令,以及跨项目都需要遵守的记忆信息。相当于你的“个人总控台”。
典型的目录结构长这样:
```
~/.claude/
├── settings.json # 全局配置(model / theme / env / permissions)
├── CLAUDE.md # 全局指令(所有项目都会加载)
├── commands/ # 全局 slash 命令
├── agents/ # 全局 subagent
├── skills/ # 全局 skill
└── projects/
/
├── *.jsonl # 会话 transcript
└── memory/ # 自动记忆系统
```
看到 `projects/` 下面那一坨东西了吗?那是 Claude Code 自动维护的“账本”,你平时不用手动碰。但**知道它在哪能解决很多奇怪的问题**——比如你想查查上次那次会话到底发了什么,直接去读那个 `jsonl` 文件就行了,比你去翻聊天记录快得多。
### 1.2 项目级 `.claude/`
这个目录放在项目根目录下,**只在这个项目里生效**。它是用来给团队成员或这个特定的代码仓库定制专属行为的。你可以把它想象成这个项目的“族规”。
```
/.claude/
├── settings.json # 项目共享配置(建议提交到 git)
├── settings.local.json # 个人覆盖(应该 gitignore)
├── commands/ # 项目专属 slash 命令
├── agents/ # 项目专属 subagent
├── skills/ # 项目专属 skill
└── rules/ # 按主题拆分的规则模块
```
这里有一个很重要的优先级:**用户级 → 项目级 `settings.json` → 项目级 `settings.local.json`**。后者的会覆盖前者。
关于 git 提交,建议这样操作:
| 提交进 git | gitignore |
|---|---|
| `CLAUDE.md` | `.claude/settings.local.json` |
| `.claude/settings.json` | (以及任何放本地 API Key 的私有文件) |
| `.claude/commands/`、`.claude/skills/`、`.claude/agents/`、`.claude/rules/` | |
> 这里有一个很常见的误区:有些人把自己所有的偏好都堆到项目 `settings.json` 里,结果跟同事一协作,git 冲突就来了。记住,**个人偏好走 `settings.local.json`,团队约定才走 `settings.json`**。别搞混了。
## 02 配置文件
### 2.1 `settings.json`
这个文件里的常用顶层 key 有这些:`model` / `theme` / `env` / `permissions` / `hooks`。重点说下 `permissions`,它的语法变体最多,也最容易写错。写错了,AI 可能会做一些很危险的事情。
```json
{
"$schema": "https://json.schemastore.org/claude-code-settings.json",
"model": "claude-opus-4-8",
"permissions": {
"allow": [
"Bash(pnpm *)", // pnpm 全部子命令(空格 + 通配)
"Bash(git add:*)", // git add 任意参数(冒号 + 通配)
"Read", "Edit", "Grep", "Glob", // 工具名直写 = 全放行
"WebFetch(domain:github.com)", // 仅放行指定域名
"Skill(commit)", // 放行某个 skill
"mcp__ide__getDiagnostics" // 放行某个 MCP 工具
],
"deny": [
"Bash(rm -rf *)",
"Bash(curl *)",
"Read(./.env)",
"Read(./.env.*)",
"Read(./secrets/**")
]
}
}
```
加上 `$schema` 后,在 VS Code、Cursor 这类编辑器里,它会给你提供字段补全和拼写校验。这个很有用,因为**权限规则写错比代码写错更难察觉**,写一次这个 schema,能少踩不少坑。
配置权限时,最好遵循几条原则:
* **最小权限**:只放行项目实际用到的命令,不要图省事写个 `"Bash(*)"` 一把梭,那是给自己埋雷。
* **不放行任意代码执行类**:像 `python`、`bash`、`npm run *` 这种,收益小,安全代价大,最好别放。
* **危险命令显式 deny**:`rm -rf`、`git push --force`、`git reset --hard` 这些,让 Claude 每次都弹个确认框,心里踏实。
> **一个常见的安全盲区**:你写了个 `Read(./.env)` 阻止内置的 Read 工具读 `.env` 文件,但**如果你同时放行了 Bash,那 `cat .env` 这个命令照样能读到**。Read/Edit 的 deny 规则只约束内置的文件工具,不约束 Bash 子进程。要做严格的路径隔离,得启用 sandbox。
### 2.2 `settings.local.json`
这个文件和 `settings.json` 结构一样,唯一的区别在于:**它必须进 `.gitignore`**。Claude Code 创建它时已经自动处理好了,你只要别把它改回去就行。
它适合放哪些东西呢?本地路径的环境变量、你个人调试用的临时权限、或者你自己想切换的模型。总之,就是只属于你,不该被提交到仓库的配置。
### 2.3 `CLAUDE.md`
这个文件虽然不在 `.claude/` 目录里,但跟它关系密切。它**会被自动注入到每次对话的 system prompt**,相当于你给 AI 的“通用指令”。
项目级的 `CLAUDE.md`,建议按这五个方面来组织(这个框架是一位经验丰富的同事总结的,很实用):
* **项目结构**:核心目录在哪、源码软链接指向哪、哪些文件是自动生成的。不告诉 AI 这些,它会反复 `find`,浪费时间也浪费 token。
* **参考项目**:本仓库借鉴或对照的其他项目放在哪个本地路径。让 AI 直接去对照源码,而不是凭印象瞎猜。
* **架构骨架**:用几句话讲清楚这个项目要干什么,关键模块的职责。这样 AI 生成的代码才能符合整体规划。
* **编码规则**:注释用什么语言、命名风格是什么、空行怎么处理、特定语言的惯用法。AI 在不同模型间风格飘忽不定,靠这一节能稳住。
* **编译与调试**:构建命令怎么跑、运行环境有什么差异(比如 Docker 容器内和 IDE 终端的路径不一样)、是否允许 AI 自动跑编译。
另外,有些东西**千万不要放**进去:
* 通用工程实践(比如“写注释”、“加单元测试”——模型已经知道了,别浪费空间)。
* 文件目录树(模型自己会 `ls`,不需要你告诉它)。
* 会过时的临时状态(“我们正在重构 X 模块”之类的话)。
> 经验表明:`CLAUDE.md` 越短越好用。150 行以内能 hold 住,超过 200 行,有效信息会被稀释,AI 的遵循度会明显下降。
>
> 还有一条比“写什么”更重要的建议——**写“不要做什么”比“要做什么”更重要**。模型默认行为已经够好了,`CLAUDE.md` 的真正价值在于纠偏。比如,明确禁止用 `npm`、明确禁止 `any` 类型、明确禁止改某个配置文件。这种硬约束,比“请遵循 SOLID 原则”这种软要求有用一万倍。
## 03 扩展能力
`/claude/` 这个目录下真正能改变 Claude Code 行为的,是下面这几类对象。按使用频率排序如下:
### 3.1 `commands/` — 自定义 slash 命令
每个文件对应一条 `/foo` 命令。
* 路径:`/.claude/commands/.md`
* 子目录可以变成命名空间:比如 `commands/git/commit.md` 对应命令 `/git:commit`。
* 文件正文就是你想要执行的 prompt 模板。
* 可选 YAML frontmatter,可以定义 `description`、`argument-hint`、`allowed-tools`、`model` 等。
* 模板里可以用 `$ARGUMENTS` 占位用户传入的参数。
* 如果开头用 `!some-shell-command` 前缀,会先执行这个 shell 命令,然后把输出结果嵌进 prompt。
* `@path/to/file` 可以引用其他文件的内容。
这个功能最适合“重复性强、模板化、自己每次说一段长 prompt 嫌烦”的场景。比如你写了个 `/new-post 思考 标题` 的命令,AI 就能自动生成一篇草稿。
### 3.2 `agents/` — Subagents
这相当于带着独立上下文的“子 Claude”。
* 路径:`/.claude/agents/.md`
* frontmatter 里 `name` 和 `description` 是必填的;`tools`(工具白名单,缺省则继承主对话的全部工具)和 `model` 可选。
* 文件正文就是这个 agent 的 system prompt。
* 主对话可以显式通过 `Agent(...)` 调用,也可以让 AI 基于 description 自动为你委派。
* 每次调用都会开启一个全新的上下文,主对话只能看到 agent 的最终回复。
什么时候用它最合适?
* 任务需要读取大量文件,但你不想让这些 token 占满主对话的上下文。
* 任务有自己专门的一套 system prompt(比如做安全审查、性能分析),跟主对话的调性不符。
* 你想并行处理——一次发出多个 subagent 让它们同时跑。
### 3.3 `skills/` — 渐进披露的能力包
从结构上看,它跟 subagent 有点像,但机制完全不同。
* 路径:`/.claude/skills//SKILL.md`——注意这是个**目录**,可以带脚本、模板、参考资料等附属文件。
* `SKILL.md` 的 frontmatter 至少要有 `name` 和 `description`。
* **渐进披露**:会话开始时,只注入 frontmatter 里的信息;当 description 匹配到用户意图时,才会读入正文。这和 subagent 的“全文进系统提示”完全不同。
* 跟 subagent 的本质区别:skill 在**主对话的上下文**里展开执行;而 subagent 是**另起一个隔离的会话**。
它适合定义那些“按部就班的流程”——比如“发 PR 前的 review 步骤”、“生成某类规范文档”。把这些固定流程包装成一个 skill,以后让 AI 按这个流程走,省心。
### 3.4 `rules/` — 把规范拆成可维护的模块
当 `CLAUDE.md` 写到几百行时,它就开始失控了——信息被稀释,AI 的遵循度明显下降。这时候,把内容迁移到 `.claude/rules/` 下,**一个主题写一份 markdown**,递归发现,多人维护起来互不干扰。这样,你的规则库就变得有组织、有层次了。
这里有两种**加载模式**:
* 无 frontmatter(或没有 paths 字段):会在启动时加载,行为有点像 `CLAUDE.md`。
* 带 `paths` 字段的 frontmatter:只在 Claude 处理匹配路径的文件时才会触发。
举个例子,在 `.claude/rules/api.md` 中:
```
---
paths:
- "src/server/api/**/*.ts"
---
# API 约定
- 所有 handler 必须做输入校验
- 对外错误返回统一结构 { data, error }
- 禁止把内部堆栈直接返回给客户端
```
你看,只要约定是写在文件路径 `src/server/api/` 下的文件被改动时,这些规则才会被加载进上下文。前端的组件改动,不会被这些无关的 API 规则所污染。这比一股脑全塞进 `CLAUDE.md` 要聪明得多。
**加载顺序**:用户级 `~/.claude/rules/` 先加载,项目级 `.claude/rules/` 后加载——后者优先级更高,**项目的规则不会被个人偏好覆盖**。
**跟 `CLAUDE.md` 的分工**:
* `CLAUDE.md`:项目级的“必备命令 + 关键约定 + 容易踩的坑”,控制在 200 行以内。
* `rules/`:按主题拆分的模块化规范,按需触发。
AI 遵循度的差距,很大程度上来自信息密度。一份 200 行的 `CLAUDE.md`,加上若干 `paths` 触发的 `rules`,比一份什么都塞的 1000 行大 `CLAUDE.md` 要靠谱得多。
### 3.5 `plugins/` — 能力打包
这个是把 `commands` / `agents` / `skills` / `hooks` 打包成一组可分发的形式。它本身并不在 `.claude/` 下展开,而是通过 `settings` 里的 `enabledPlugins` 字段启用,或者经由 plugin marketplace 安装。适合给团队下发一套配套的能力,避免在每个仓库里都重新拷贝一遍。
### 3.6 `output-styles/` — 主对话人格
`/.claude/output-styles/.md` 可以定义一份替换主对话 system prompt 的“风格”。通过 `/output-style` 命令切换。很适合在不同场景间切换人格——比如代码评审模式 vs 教学讲解模式。日常用得不多,了解即可。
## 04 自动状态
这一节讲的是那些你不需要手动维护、但最好知道它们存在的部分。
### 4.1 `projects/`
在 `~/.claude/projects//` 目录下,每个 `*.jsonl` 文件都是一次会话的完整 transcript。每行一个 JSON,记录了所有 user/assistant/tool 消息。
什么时候你会觉得它有用?
* 想分析一下自己最常用什么命令。
* 想复盘一下上次某个 bug 到底是怎么 debug 出来的。
* 想给同事演示“那次操作的全过程”——直接把 `jsonl` 文件发过去就行。
### 4.2 `memory/`
自动记忆系统就住在这里:`~/.claude/projects//memory/`。它的结构是:
* `MEMORY.md`:索引文件(每条一行,自动加载到上下文)。
* `.md`:每个独立的记忆文件,带 frontmatter。
它存的是**跨会话需要保留的、且不能从代码或 git 历史中推断出来的事实**——比如你反复纠正过的偏好、项目里非显性的约定、你的角色背景之类的。
**不该存的东西**:代码片段、文件路径、git 历史、临时状态。这些信息,AI 自己就能从项目里获得。
## 05 最小配置
如果你刚开始整理你的 `.claude/` 目录,别想着一步到位。从下面这套最精简的配置起步就行:
```
~/.claude/settings.json # 全局 model + 主题 + 跨项目高频权限
~/.claude/CLAUDE.md # 你的工作风格偏好(< 50 行)
/.claude/settings.json # 项目高频只读命令权限
/.claude/settings.local.json # 个人本地覆盖
/CLAUDE.md # 项目命令 + 架构骨架 + 隐性约定
```
`commands/`、`agents/`、`skills/`、`rules/` 这些都不是必需的。**等你发现自己反复在做某件事时,再加它们也不迟**。过早配置,就等同于过早优化,没必要。
### 5.1 完整工作流示例
把 `commands/` 配置好之后,日常的迭代会变成一条很顺畅的链:
```
Input:实现 X 功能
Claude:(读 CLAUDE.md 了解项目规范,按规范写代码)
Input:/review
Claude:(按 review.md 的维度做代码审查,输出问题列表)
Input:/lint
Claude:(运行 pnpm lint,修复发现的问题)
Input:/commit
Claude:(分析改动,生成规范提交信息,执行 git commit)
```
每一步都是可以被中断、可以被回滚的小动作。这比直接跟 AI 说“帮我搞定这个 feature 并提交”要靠谱得多。因为在每一步,你都给出了明确的意图,模型就不会“自作主张”地一连串执行十几个本不该连贯执行的动作。
> 这就是 `.claude/` 配置的最大价值——**把含混的“AI 帮我写代码”拆解成一连串明确的、可观察的、可控制的步骤**。让每个环节都尽在掌握。
## 06 实践经验
`.claude/` 配好了不等于就能用好。下面这几条,是我踩过的坑里,觉得最值得沉淀为 rule / hook / prompt 习惯的经验。
### 6.1 先注释再删代码
让 AI 做重构时,在 rule 里默认要求**用注释替代删除**,删除操作由工程师确认后再做。AI 一旦“自信地”删错文件,回滚成本可比多看一眼注释行高多了。
### 6.2 环境差异写进 rule
如果你的开发、编译、测试环境路径不一致(典型的场景:Docker 容器内路径是 `/code/...`,而 IDE 终端路径是 `/data/home/.../code/...`),把这个映射关系写进 `CLAUDE.md`。这样,AI 在遇到编译错误时,能自动换算成你 IDE 里的路径,而不用你手动去对照。
### 6.3 用脚本而不是裸命令
在 rule 里告诉 AI,运行测试时用 `scripts/test.sh`,而不是让它每次自己拼 `pytest --cov=...`。脚本化的好处是有一个统一的入口,AI 一看就知道系统怎么跑。失败了,也好定位是流程问题还是代码问题。
### 6.4 明确“何时可以编译”
大型项目编译一次可能就要几分钟甚至几十分钟,让 AI 写一点就编译一次,会拖死你的节奏。在 rule 里写清楚:**只有显式说出“编译”时,才去执行编译命令**。日常生成代码先攒着,攒完一组任务,再统一编译。
### 6.5 单测是反偷懒的杠杆
写实现代码时,AI 效率很高;但写单测时,它最爱偷懒,用 mock 掩盖一切,主分支根本没被覆盖。两个配套的习惯:在 rule 里要求优先覆盖核心调用链,少用 mock;在 review 单测时,优先看断言是否充分,而不是只看测试是否通过。
### 6.6 让 AI 自证
AI 给的方案和代码,不一定都对。当你怀疑某处不对劲,但又说不清具体问题时,直接问它:“这里是不是不优雅?”或者“再 review 一下这份设计”。模型被反问时,往往能主动承认问题,比你一个点一个点去挑错要快得多。这条不用写进 rule,写进你自己的 prompt 习惯里就行。
## 07 结语
所有这些 `.claude/` 目录下的文件、目录、配置项,本质上都是在做同一件事:**把你和 AI agent 之间反复重复的对话固化下来**。
第一次让它做某件事时,多说几句没关系;但第二次还要重复同样的话,你就该想想:是不是该把这句话写成一条 rule、一个 command、或者一份 skill?**用 Claude Code 这类 agent,一个核心实践原则就是:在使用过程中不断地增加配置、调教 agent。**
不要追求一次性配齐一个完美的 `.claude/`,那是过早优化。**等你发现自己反复在做某件事时,再加配置**。让配置跟着你的真实使用一起长大。每一条新增的规则背后,都该有你一次“怎么又说一遍”的不耐烦——那正是它最该被沉淀下来的信号。





