
凌晨,GPT-5.5收复失地,Anthropic紧急出手
今天凌晨,AI领域再次迎来一个重磅时刻:OpenAI正式发布了其智能体编程模型
GPT‑5.5
这个被官方称为“迄今为止最智能、最直观易用”的模型,目标直指一个核心场景:在计算机上完成实际工作。它擅长
编写调试代码、在线研究、数据分析、创建文档与电子表格,并在多个工具间无缝协同
OpenAI联合创始人Sam Altman的评价颇为耐人寻味,他说,这个模型“知道该做什么”。
性能提升在
智能体编程、计算机使用、知识型工作及早期科学研究
跨上下文的深度推理和持续自主行动
更值得注意的是效率。GPT‑5.5在实际服务中保持了与GPT‑5.4相当的响应速度,但完成相同任务时使用的token数显著减少,这意味着
更高的效率和更强的能力
模型一经发布,早期测试者的反馈迅速涌来,生动展示了其潜力。
开源项目Claude Engineer的创建者Pietro Schirano分享了他的体验:GPT-5.5用了大约
20分钟
他还用GPT-5.5一次性生成了一个可流畅操作的3D射击游戏,每个图形都由Three.js从零生成。更硬核的是,他让GPT-5.5
通过USB连接

Pietro Schirano感慨道:“我第一次感觉自己不再受限于模型的功能,而只受限于我的想象力。”

AI工程师Peter Gostev的深度测试则揭示了其持久的自主性。他设定了多步骤提示词,GPT-5.5能逐项稳定执行,亲测至少可自主运行7小时。他要求模型创建一个带有地标和季节变化的伦敦玩具铁路,GPT-5.5一次性出色完成。对比GPT-5.4,新模型的作品构思更宏大、逻辑更连贯,错误也更少。
学术界的应用同样惊人。波兰波兹南密茨凯维奇大学的Bartosz Naskręcki教授使用Codex中的GPT‑5.5,仅凭一条提示词,在
11分钟内
知名AI测评博主Matthew Berman则注意到了模型“个性”的转变,认为其回答更简洁、更像真人,这或许是OpenAI在个人智能体市场布局的一步棋。

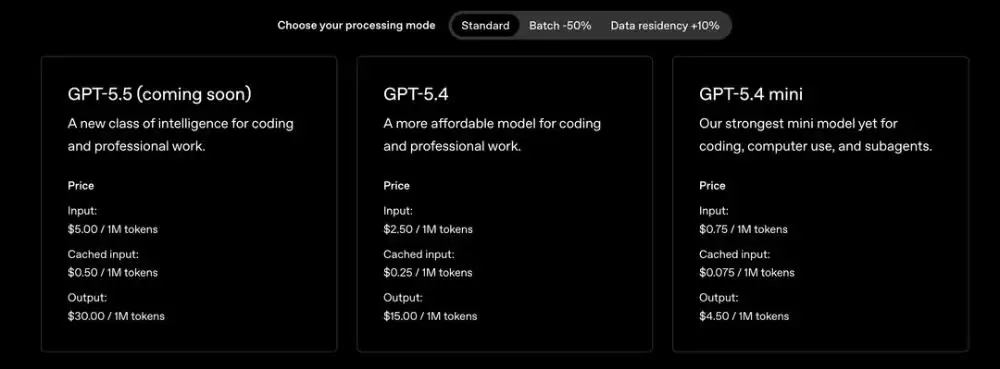
能力提升的同时,价格也随之上涨。GPT-5.5定价为
每100万输入token 5美元,每100万输出token 30美元
一倍
每100万输入token 30美元,输出180美元
目前,GPT‑5.5正逐步向ChatGPT和Codex的Plus、Pro、Business和Enterprise用户推出,Pro版本则面向ChatGPT的更高阶用户。API开发者也将很快能在Responses API和Chat Completions API中调用gpt-5.5。
有趣的是,GPT-5.5发布当天,正值其竞争对手Anthropic的Claude Code因性能波动而遭到用户投诉。Anthropic迅速发布长文宣布已修复问题并重置用户使用限制,市场竞争的硝烟味瞬间浓烈起来。
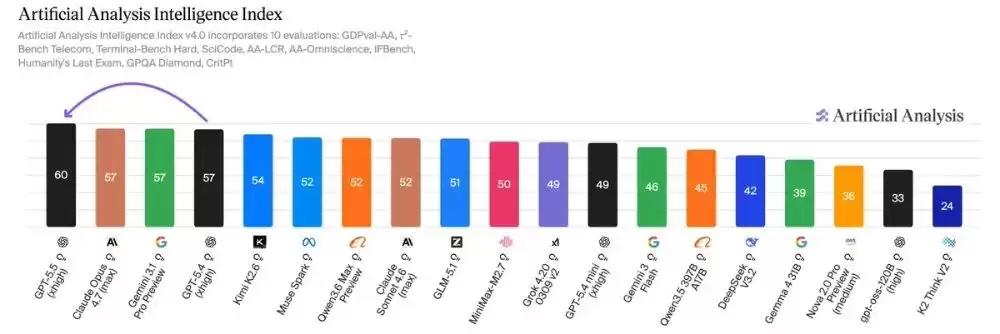
登顶编程Agent榜首,成本仅为竞品一半
登顶编程Agent榜首,成本仅为竞品一半
OpenAI毫不讳言,GPT‑5.5是其
迄今为止最强大的Agentic Coding模型
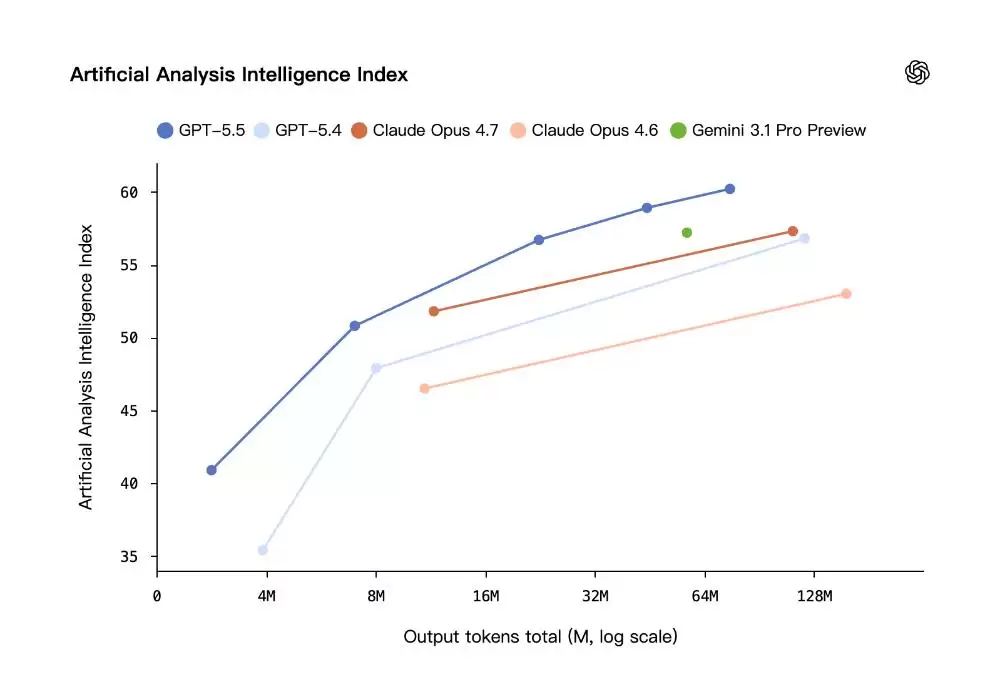
更具吸引力的是其成本效益。根据该指数,GPT‑5.5在取得最高成绩的同时,其成本仅为同类前沿编码模型的
一半
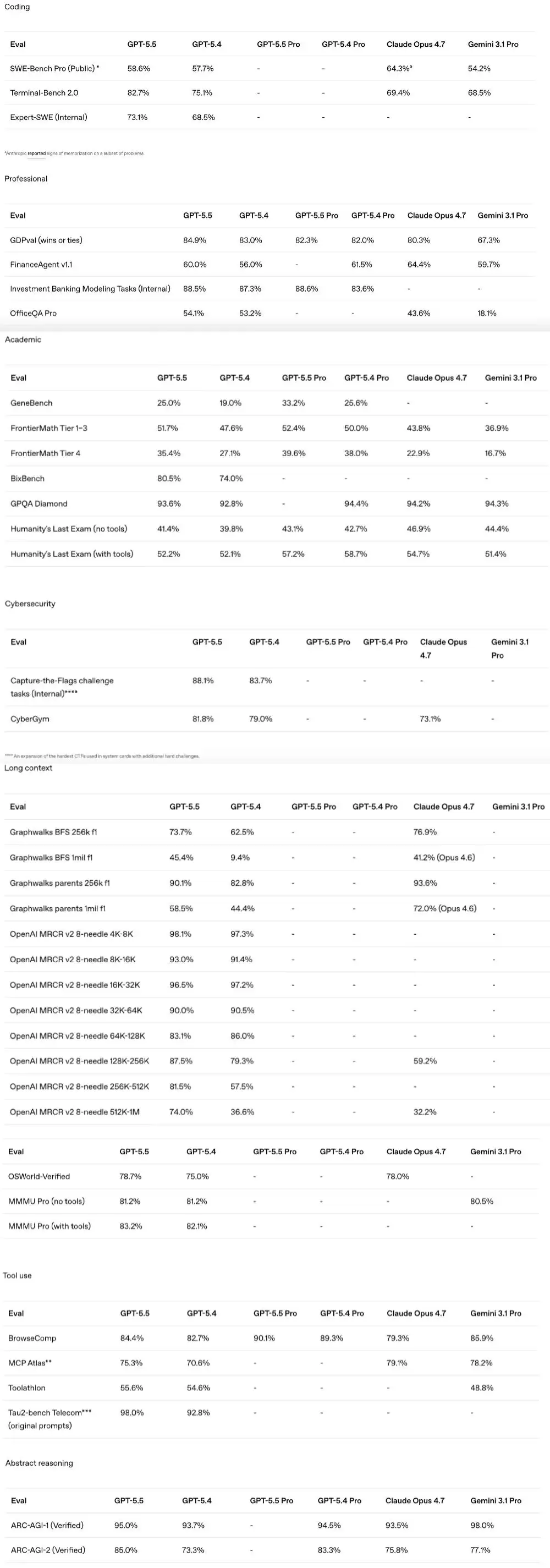
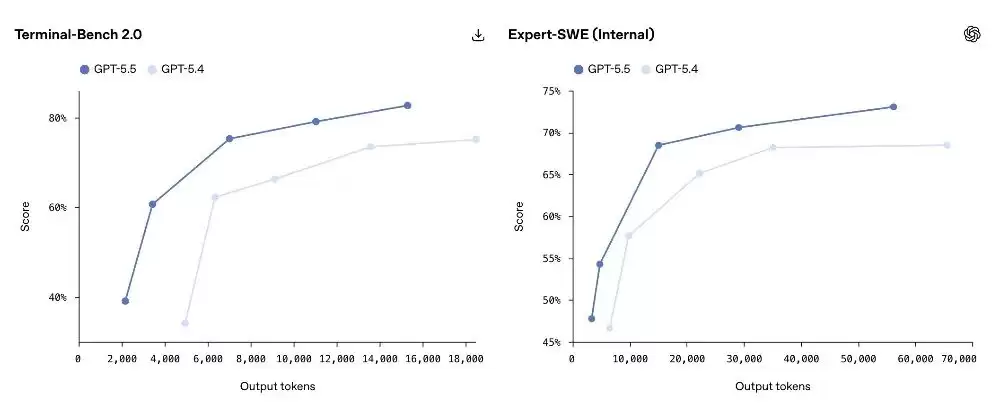
具体到测试成绩:在复杂执行测试Terminal-Bench 2.0上,GPT‑5.5得分
82.7%
58.6%
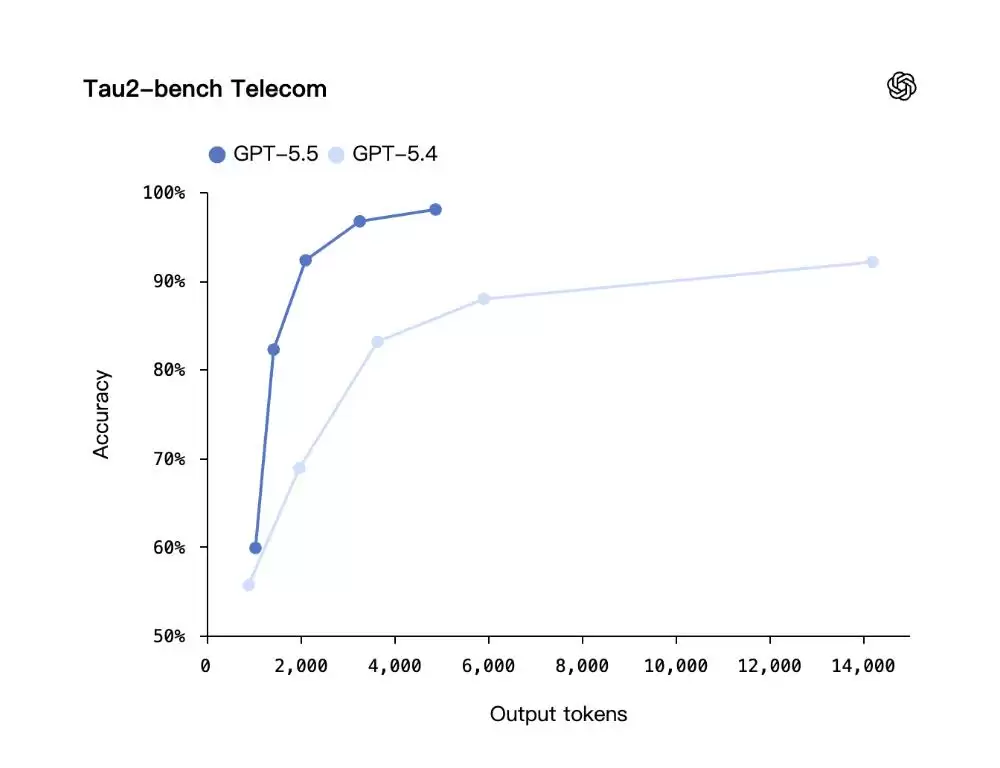
这种编程优势在Codex环境中被放大。从实现、重构到调试、测试和验证,GPT‑5.5能承担一系列工程工作。早期测试表明,它尤其擅长在大型系统中保持上下文、对模糊故障进行推理、通过工具验证假设,以及对整个代码库进行变更同步。
例如,它能使用NASA/JPL Horizons的矢量数据渲染猎户座飞船的运行轨迹,并实现显示缩放;也能制作出动态显示地震频次、地点的追踪网站;配合Codex,甚至能生成可交互的3D游戏。
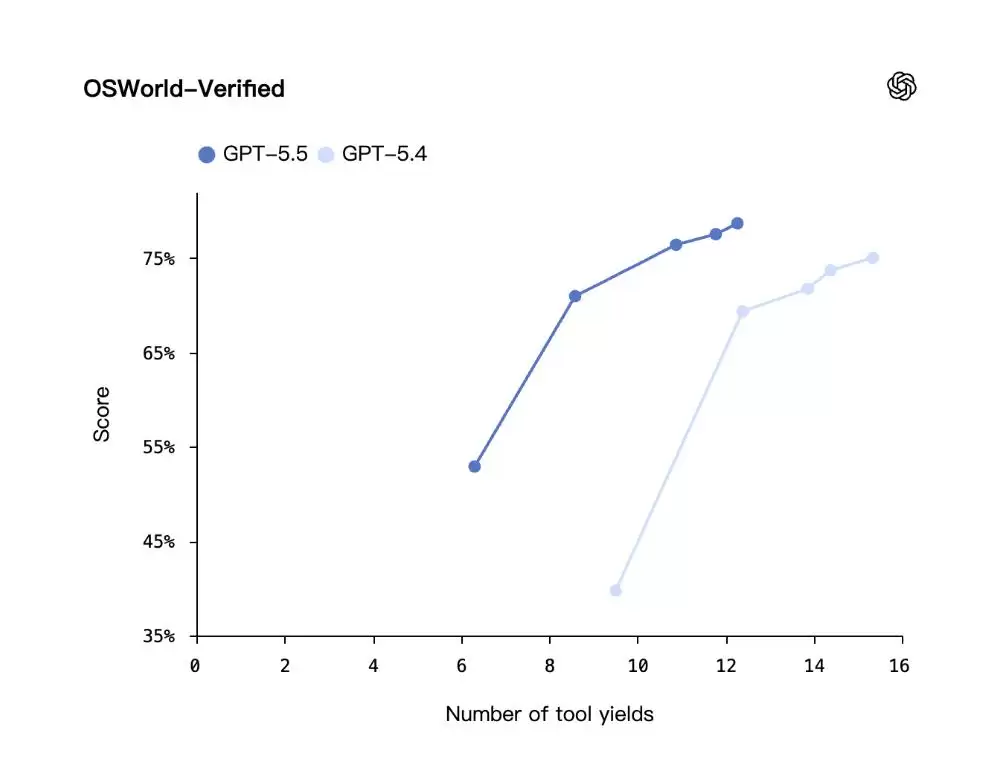
客服测试成绩达98%,能自主浏览界面操作工具
客服测试成绩达98%,能自主浏览界面操作工具
GPT‑5.5的核心进步在于对用户意图的更自然理解,这使得它能够闭环处理知识型工作:查找信息、理解重点、使用工具、检查结果、产出成果。
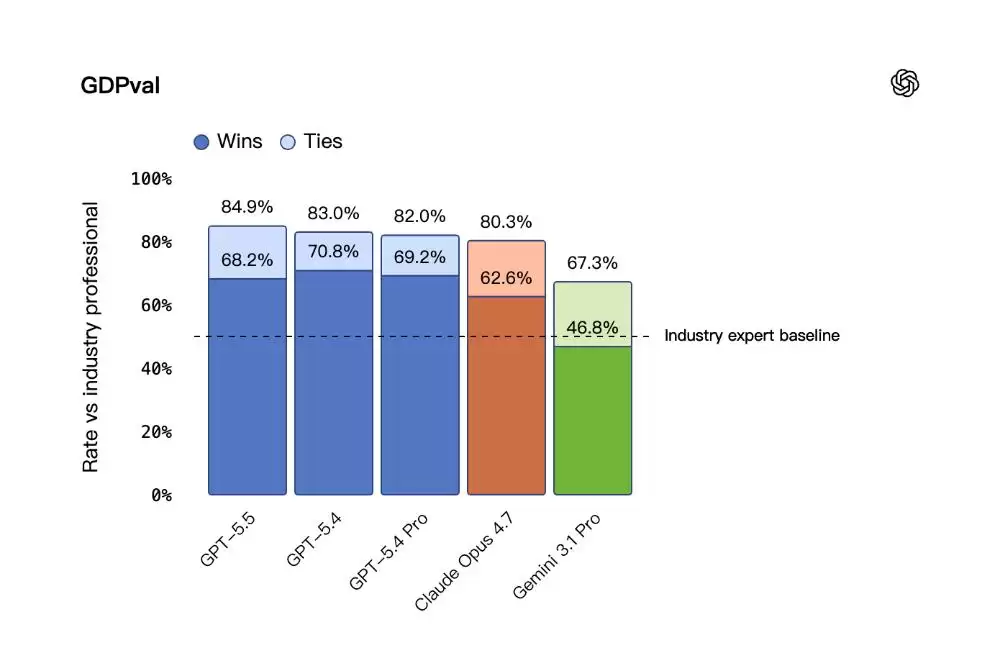
在ChatGPT的“思维模式”下,它在编程、研究、信息综合与分析等专业任务中表现出色。基准测试成绩亮眼:规范知识型工作测试GDPva得分
84.9%
78.7%
98.0%
在金融建模、办公自动化等具体领域,其表现也相当扎实。实际应用中,Codex内的GPT‑5.5在生成文档、电子表格和演示文稿方面已优于GPT‑5.4。Alpha测试人员反馈,在运营研究、电子表格建模及梳理混乱业务信息等任务上,它超越了以往所有模型。
当结合Codex的计算机使用技能时,体验更为震撼:模型仿佛真的在与用户共同使用电脑——查看屏幕内容、点击、打字、浏览界面、跨工具操作。例如,OpenAI财务团队利用它审阅了超过2.4万份税务表格,节省了两周时间;用户也能用它来设计并调试复杂的新客户引导流程。
发现拉姆齐数新证明,在遗传学生物学表现亮眼
发现拉姆齐数新证明,在遗传学生物学表现亮眼
科研工作流程漫长而复杂,从探索想法、收集证据到检验假设、解读结果,每一步都需要深思熟虑。GPT‑5.5 Thinking模式正为此而生,它能协助研究人员审阅稿件、压力测试技术论证、提出分析建议,并协同处理代码、笔记和PDF。
在专注于遗传学和定量生物学的GeneBench评估中,GPT‑5.5相较于前代表现出显著提升。这些任务要求模型在极少监督下,对可能存在歧义或错误的数据进行推理,并正确实现现代统计方法,其难度相当于专家数天的工作量。
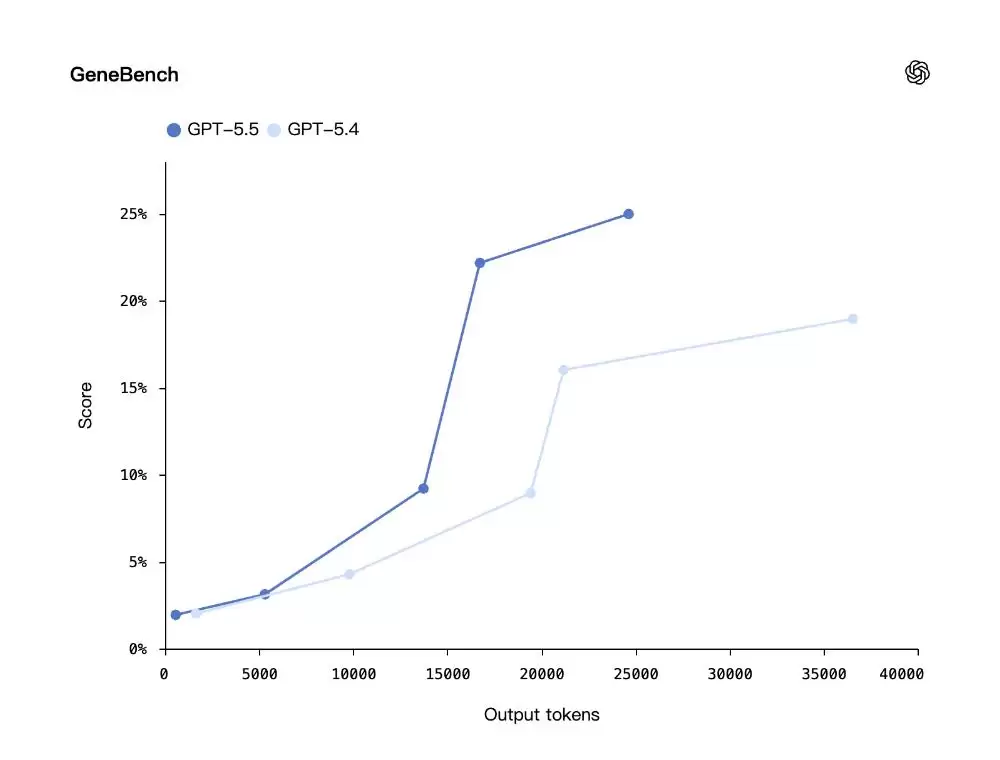
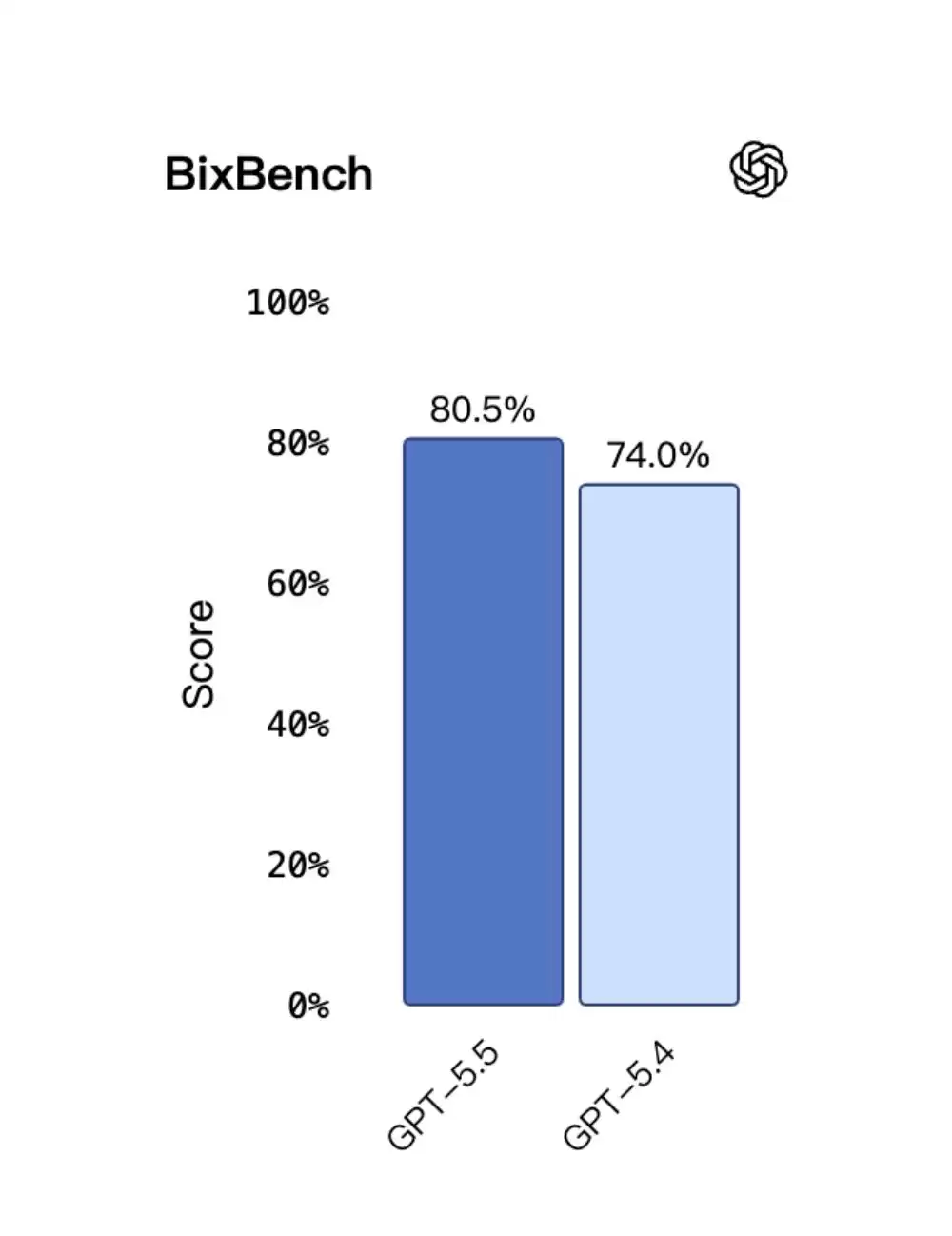
同样,在真实世界生物信息学基准测试BixBench上,GPT‑5.5在已公布分数的模型中处于领先地位。
能力越强,责任越大。OpenAI团队强调,为GPT‑5.5配备了
迄今为止最强大的安全防护措施
结语:OpenAI向自主执行更进一步
结语:OpenAI向自主执行更进一步
GPT-5.5的发布,清晰地标志着OpenAI的战略重心正从纯粹的对话与生成,转向具备自主执行能力的智能体。
在行业追逐参数规模与算力的浪潮中,GPT-5.5选择了一条更务实的路径:用更高的效率做更多的事。它在编程、知识工作和科学研究中展现的能力表明,效率与智能可以并存。
其展现出的性价比、强大的多工具协同能力以及加固的安全防线,无疑为开发者和企业用户提供了一个更强大、更可靠的生产力引擎。AI助理真正接管复杂工作的时代,似乎又近了一步。




