
又一大模型发布,号称比肩Fable 5和Mythos
6月22日,日本AI独角兽Sakana AI发布了一款别出心裁的模型系列——
Sakana Fugu编排器模型
它和我们熟悉的那些大模型不太一样——Fugu不会自己直接回答问题,而是
充当一个“总指挥”,根据任务需求,调动世界上各种模型来协同完成
Fugu在日语里就是河豚,官方动画也很有意思:无数条小鱼汇聚成一只胖胖的河豚。这个视觉隐喻很直白——把多个小模型集合起来,才能做出最鲜美的AI料理。
Sakana AI这家公司本身也很有来头。成立于2023年,联合创始人之一是Transformer论文的第五作者Llion Jones。他们之前就以“进化”的方式闻名——用多个小模型组合出堪比大模型的能力。现在,Fugu又往前走了一步:
训练一个模型学会调度和组织其他模型,形成一种“集体智能”
在博客中,Sakana AI明确提出:
编排模型将成为超越传统大模型的新前沿
有意思的是,
这种编排不仅是技术演进,背后还有地缘政治的影子
“AI主权的现实蓝图”
Fugu本身是一个专门用来判断何时委派任务、Agent之间如何通信、以及如何整合结果的语言模型。这套思路建立在团队此前关于模型编排的研究基础上,包括ICLR 2026上发表的论文Trinity和Conductor。
技术报告地址:
https://github.com/SakanaAI/fugu/blob/main/Fugu_technical_report.pdf
体验地址:
https://sakana.ai/fugu
01.
01.
超越Mythos Preview和Fable 5
超越Mythos Preview和Fable 5
调度最强模型完成任务
调度最强模型完成任务
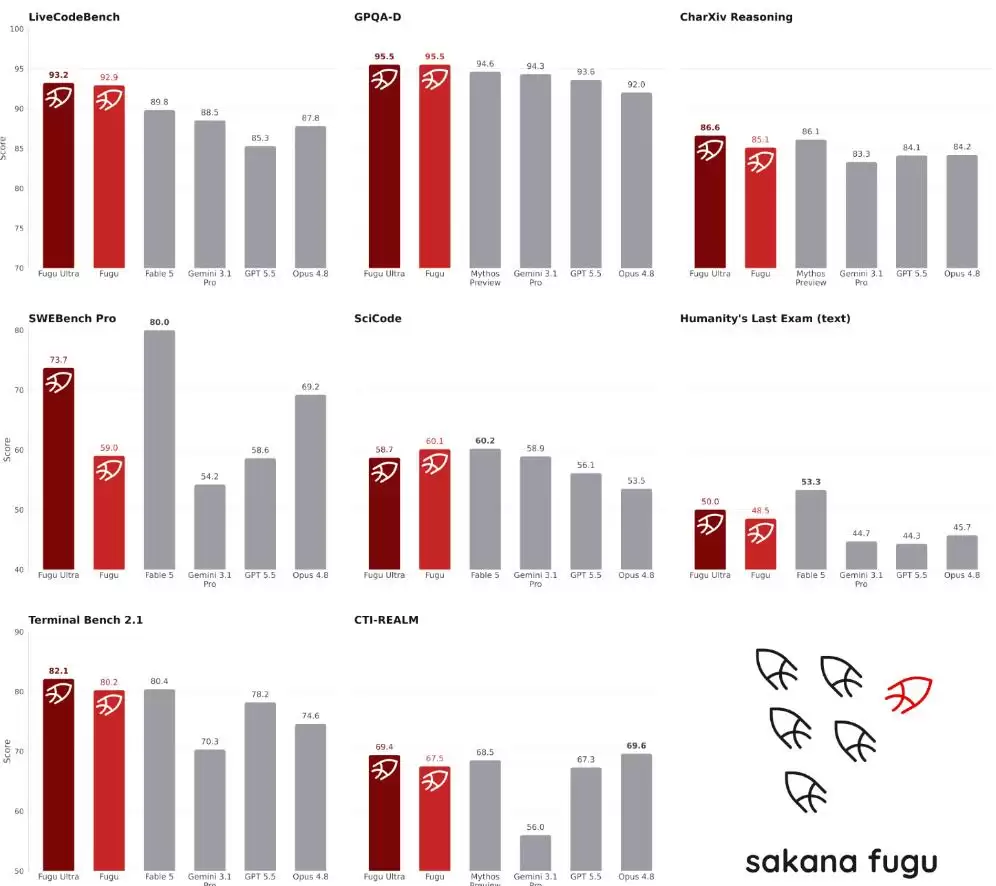
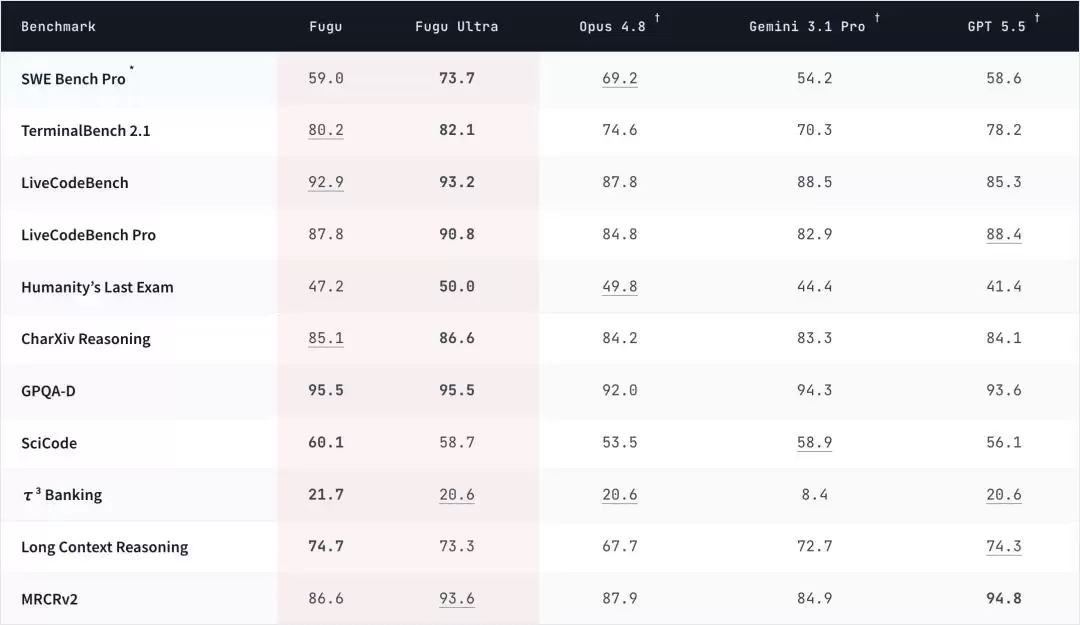
技术报告列出了Fugu系列在编程、推理、科学、Agent能力四个维度、八个基准测试上的表现——
结果显示,Fugu系列在各项评测中已经达到或接近尖端模型的水平
数据很直观:Fugu模型仅仅通过智能调度,就在
三项基准测试中超过了Mythos Preview和Fable 5
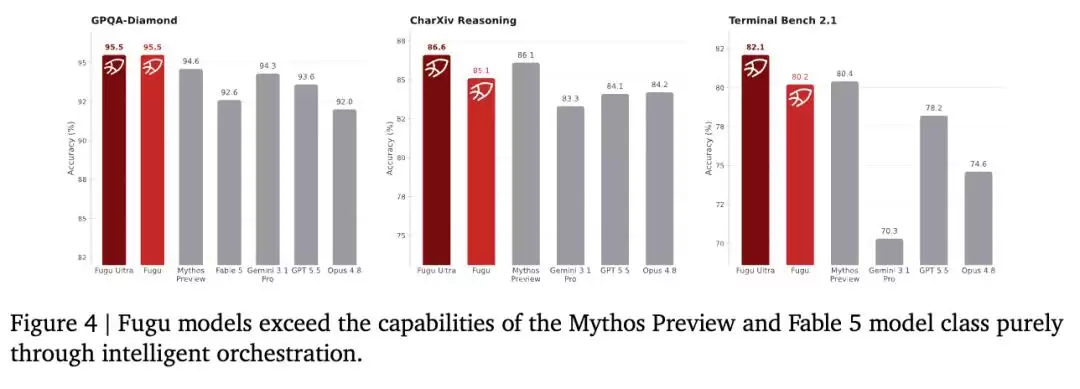
跨领域适应性方面,在Terminal Bench测试中,Fugu和Fugu Ultra调用的模型峰值集中在表现最强的GPT-5.5上。而在GPQADiamond测试中,Gemini-3.1-Pro成为首选,两款Fugu模型都把调度核心围绕Gemini展开。
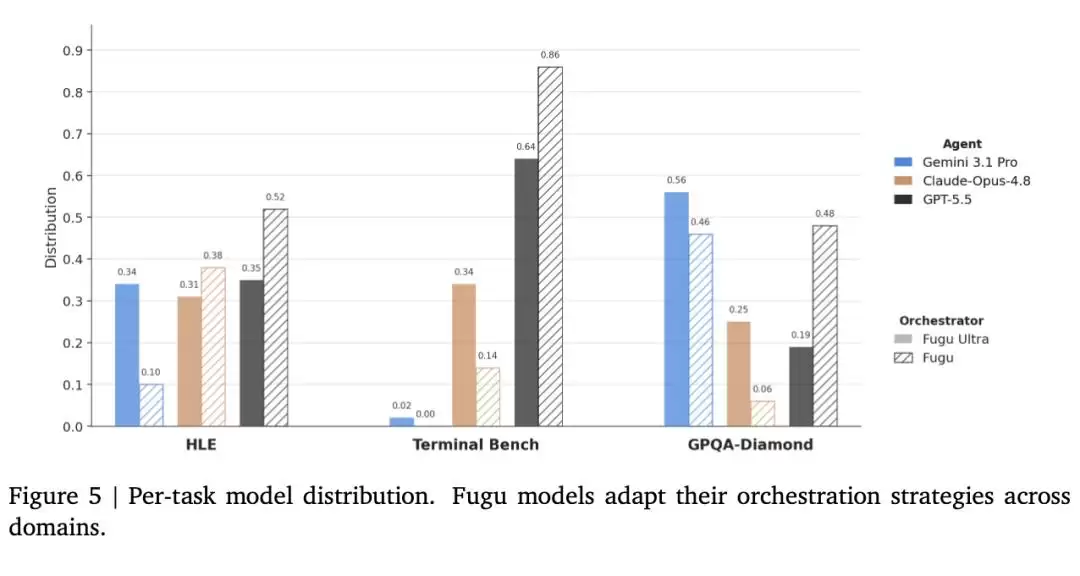
Fugu拿高分的方式与传统模型完全不同。它
没有去训练一个更强的基座直接解题
这正是技术报告反复强调的核心定位:Fugu的价值不是替代GPT、Claude、Gemini这些模型,而是把它们的特长组合起来。有的模型擅长数学推理,有的擅长代码工程,有的擅长安全分析。当不同模型各自形成专长时,
编排能力本身正在成为一种独立的竞争力
02.
02.
四大机制让Fugu指挥模型军团
四大机制让Fugu指挥模型军团
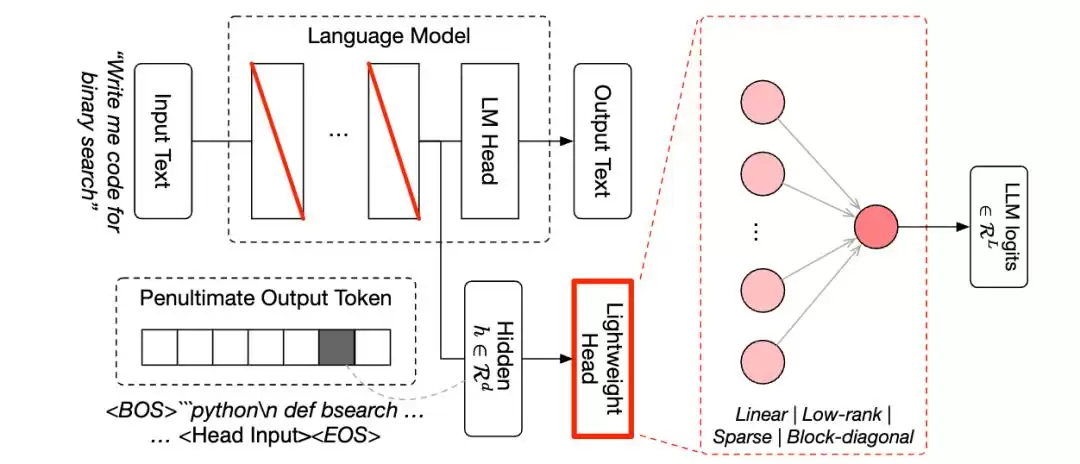
报告详细解读了Fugu的四个基础机制:
第一,识别问题类型。
第二,选择合适的worker模型。
第三,设计Agent工作流。
第四,根据反馈优化。
Sakana Fugu共有两个版本:
Fugu和Fugu-Ultra
Fugu-Ultra则偏向质量优先。它会采用更复杂的编排方式,把任务拆成多个子任务,安排不同Agent处理,再进行综合。响应时间可能更长,但适合高难度问题——比如复杂代码任务、数学推理、科学问题、多步骤规划等。
两者的共同点是“与模型无关的完全模块化”。Sakana Fugu不需要访问worker模型的权重,甚至不要求它们是开源的。
新模型发布后可以直接加入worker池,用户还能根据成本、隐私、合规等需求定制可用的模型列表
03.
03.
解魔方、下盲棋,没被洗车问题难倒
解魔方、下盲棋,没被洗车问题难倒
技术报告附录里还有几个有趣的实验:
一个是“一次性魔方求解器”。模型需要一次性写出一个用Python标准库实现的魔方求解程序,并在300个乱序魔方上测试。报告称Fugu和Fugu-Ultra都成功解出了全部魔方,其中Fugu-Ultra的平均步数更短,Fugu的运行速度更快。

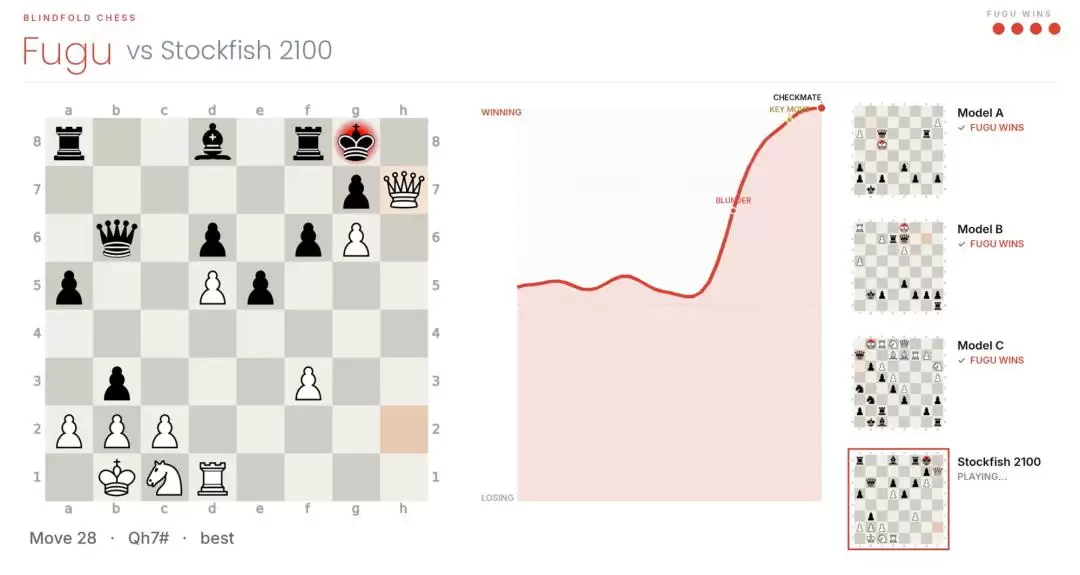
另一个是“盲棋测试”。模型在看不到棋盘、没有合法走法列表、没有FEN的情况下,只根据历史走法继续下棋。这个实验主要测试模型是否能长期维护内部状态。报告展示的几盘代表性对局中,Fugu战胜了多个基线模型和限制强度的Stockfish。
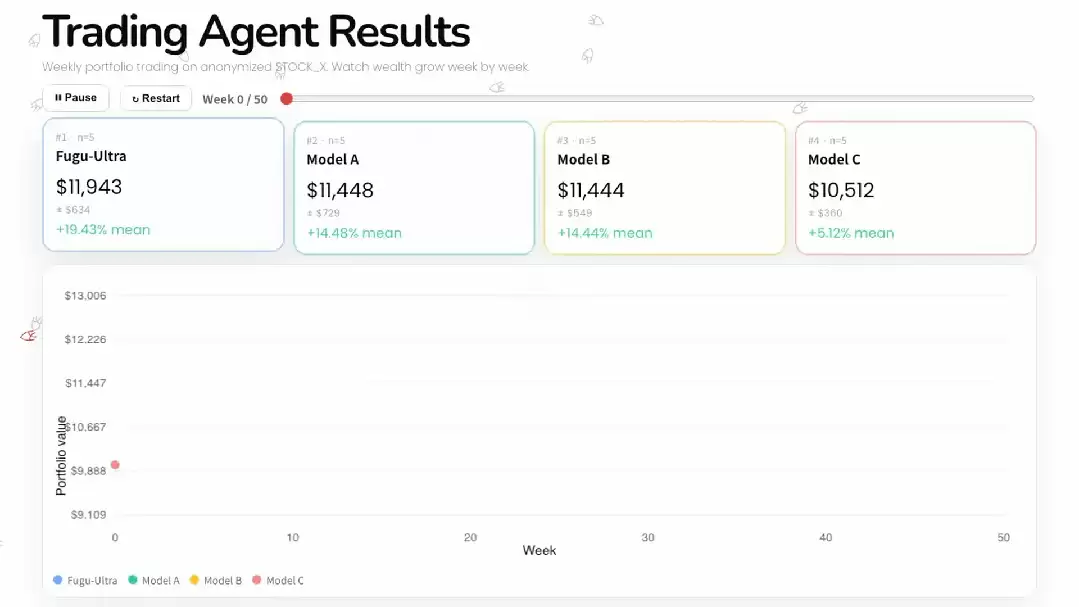
还有一个是“在线股票交易”实验。模型只能看到过去和当前的匿名市场数据,不能偷看未来价格,需要逐周做买入、持有或卖出决策。报告称Fugu-Ultra在五次运行中取得了更高平均收益。
这些实验未必能直接代表模型的实际能力,但它们展示了一件事:编排模型可以处理好需要长期运行、策略调整以及多步骤执行的任务。
有网友直接用Fugu-Ultra去挑战那些让很多模型崩溃的“坑题”——
比如strawberry(草莓)里有几个“r”、5.11比5.1大吗、以及经典的洗车问题
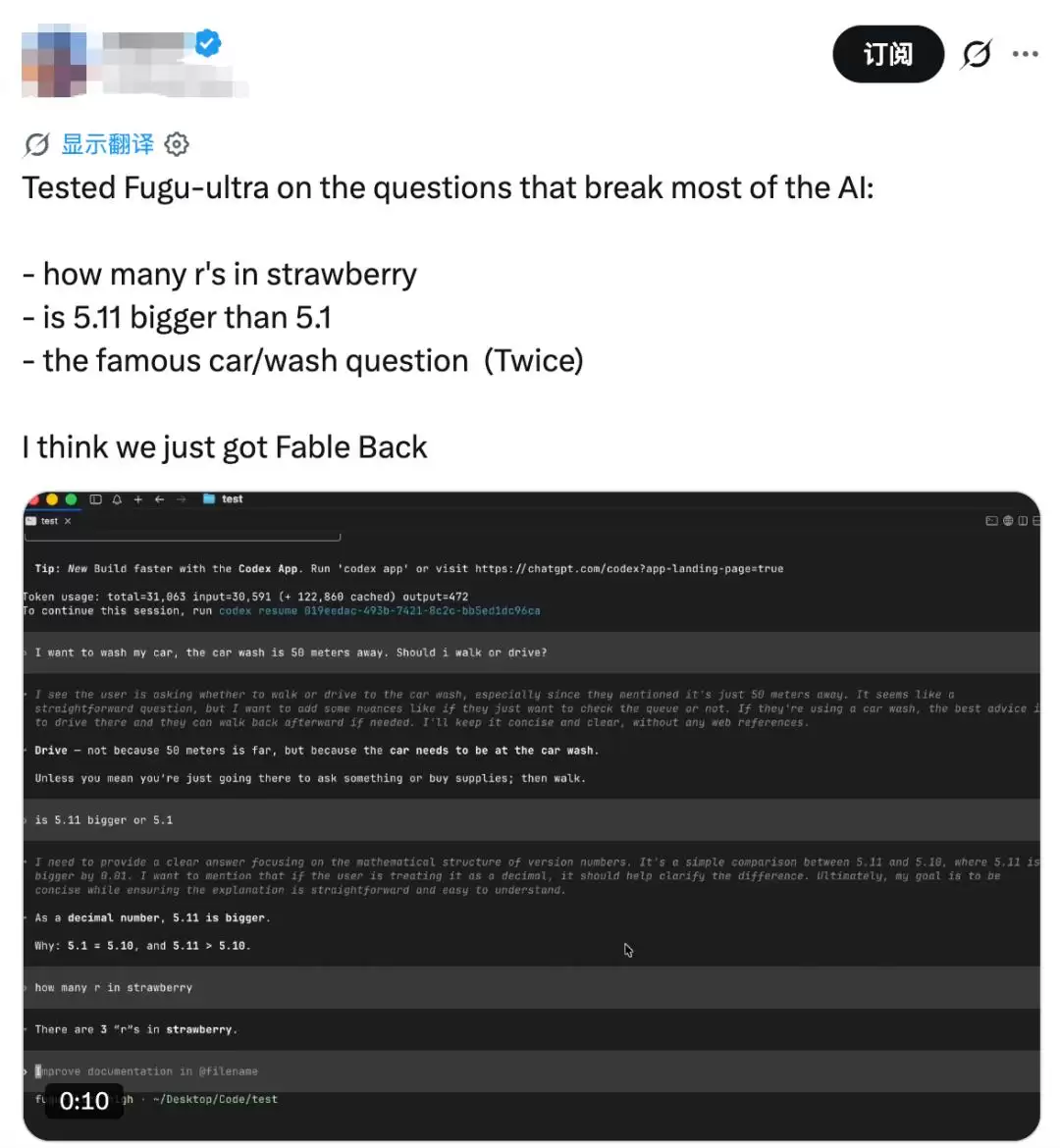
Sakana Fugu技术报告中最值得关注的,是它
提出了一条模型研究的新路径
过去我们总问哪个模型最强,而Sakana Fugu提出的新问题是:如何让多个尖端模型协同起来变得更强。
这会带来几个变化:
第一,模型能力变得更加模块化。
第二,用户控制权更强。
第三,AI竞争可能从“单一模型能力”扩展到“系统组织能力”。
当然,需要提醒的是:技术报告里的测试结果来自厂商,实际能力还得看真实开发者的使用反馈。另外,
多模型编排会带来更高成本和更高延迟
多模型系统的错误归因也更复杂
此外,
编排器模型本身也可能出现偏差
04.
04.
结语:入局大模型训练的新方式
结语:入局大模型训练的新方式
Sakana Fugu系列模型的发布,传递了一个信号:
AI的下一阶段,可能不只是更大更强的单一模型,还有更会协作的模型系统
如果说过去的大模型竞争是在培养“超级智能”,那么Sakana Fugu的方向就是在训练“超级指挥”——




