
DeepSeekV4永久降价!缓存命中再打1折,实测编程成本骤降83%
DeepSeek又出手了,而且这次是连续两天、两次降价。在输入输出价格已经打了2.5折的基础上,针对命中缓存的输入部分,又来了个“折上折”,直接再打一折。
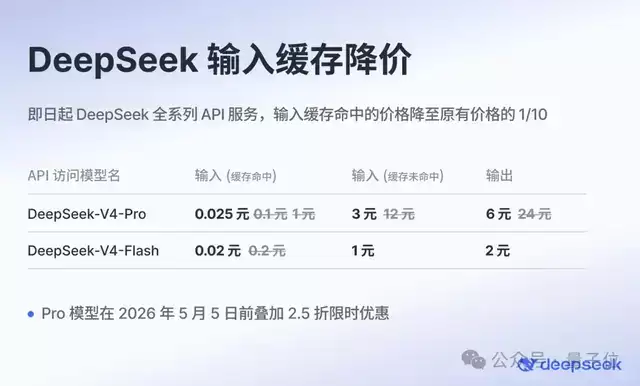
这里有个关键点值得划出来:输入缓存的折扣,并没有规定任何时限。
这一点也得到了DeepSeek研究员陈德里的确认——输入缓存是永久降价。官方还为此打上了“AGI for Everyone”的标签,意图相当明确。
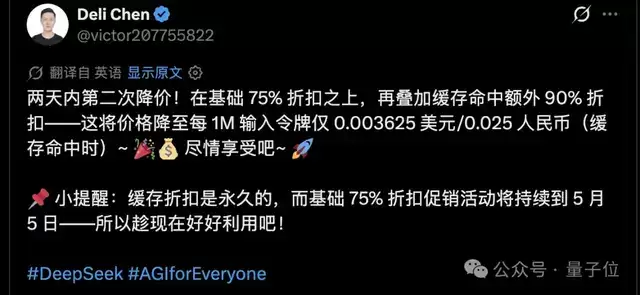
有行业学者评价,这一举措可能会彻底改变人们处理AI记忆和上下文的方式。毕竟,成本一直是制约长上下文应用普及的关键门槛之一。

现在回头再看当初发布时那句“迈入百万上下文普惠时代”的口号,似乎有了更实在的注脚。这不仅仅是技术能力的普惠,更是使用成本的普惠。

实测编程整体节省83%
那么,打折后到底能省多少钱?实际算下来,可能比表面看到的数字还要可观。
以Agent编程任务为例,这类场景有一个显著特点:输入token的比例远高于输出。同时,DeepSeek在缓存优化方面本就做得相当出色,其V4-Pro模型的输入缓存命中率大约在95%,V4-Flash也达到了91%左右。
这意味着,在实际花费中,绝大部分token都是按照“命中缓存的输入”这一最低档价格来计算的。细看价目表会发现,在这一档位上,V4-Pro每百万token只比V4-Flash贵了0.5分钱,性能与成本的权衡变得非常微妙。
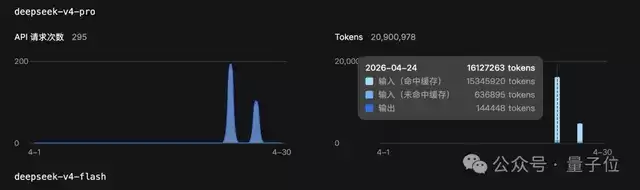
此前有测试显示,消耗约3500万token,花费了31.73元。

若将同样的数据交给DeepSeek模型按新价格计算,结果与真实花费相差无几。但关键在于,如果按照这次降价后的新价格来算,完成同样的工作只需要5.34元。
整体节省幅度高达约83%。换句话说,现在只需花费原来17%的成本,就能获得同等的产出。这个降幅,对于高频用户而言,感受会非常直接。
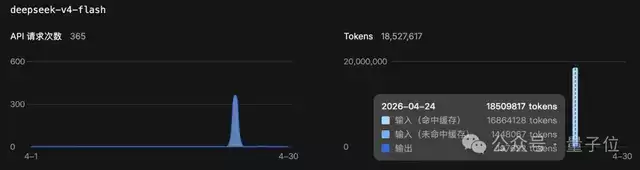
另一项实际测试也印证了这一点。在消耗了1300万V4-Pro token的任务中,缓存命中率小幅提升至96%左右,输出token的占比与降价前测试的情况基本一致。
最终实际花费为2.36元,与理论计算结果基本吻合。这充分说明了新定价策略的稳定性和可预测性。
价格屠夫回来了
DeepSeek再次祭出降价大招,在行业内引发震动,这已经不是第一次了。纵观其发展路径,这种激进的商业策略与其技术理念一脉相承:通过底层架构和算法的持续创新,不断压低模型推理的边际成本,并毫不犹豫地将这些成本优势转化为凌厉的市场竞争力。
回溯到2024年8月,DeepSeek就曾对其V3模型大幅降价,直接引发了阿里云、字节跳动等大厂的跟进,拉开了第一轮大模型token价格战的序幕。随后在R1模型发布时,又通过夜间空闲时段额外打折等策略,让价格战的温度再度攀升。
而这一次V4系列的价格调整,对海外用户产生的心理冲击可能更为强烈。如果按美元计价,那小数点后的位数,恐怕得多看几眼才能数清。
有网友总结得很到位,学生、AI初学者以及小型企业将成为最直接的受益者。极高的性价比,使得大规模、长时间调用模型进行实验、开发和部署,不再是一件需要精打细算、畏首畏尾的事情。
最后,别忘了官方公告里的那行小字。
市场已经开始期待,等到下半年DeepSeek大规模部署华&为算力之后,价格方面还能带来怎样的惊喜。这场围绕“普惠”的竞赛,显然才刚刚进入一个新的阶段。




