
英伟达开始搞机器人自己研究机器人那套了……
好好好,英伟达又有新花样了——这次他们盯上了“自动做实验”这件事。
刚刚,英伟达、CMU和Berkeley联合搞了一个叫
ENPIRE

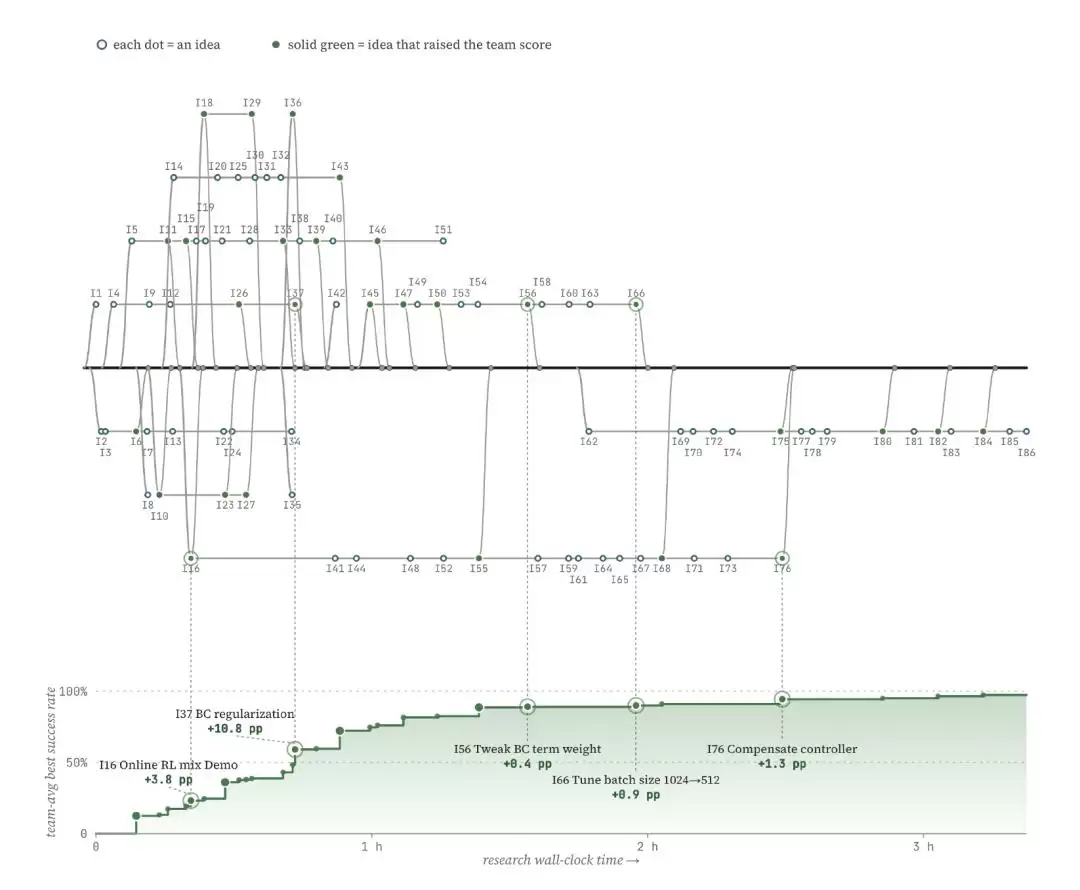
具体画风是这样的:实验室先搭好场景,剩下的就全交给Codex和机器人自己折腾。效果嘛,还真不赖。在最具代表性的Pin Insertion任务中,仅用了3小时,机器人把针插进4毫米孔洞的成功率,直接从0拉到了99%。
全程没有任何人类参与。项目负责人之一的Jim Fan发推说:“GEAR实验室的一部分现在已经在彻夜自我改进了。我们只需要早上来读报告。”
当然,也有网友一针见血地总结:“高情商:彻夜自我改进;低情商:没日没夜地烧token。”
具身智能研究的Harness
具身智能研究的Harness
先澄清一下,ENPIRE并不是让Agent直接写控制代码来操纵机器人。它更像一个机器人研究员,需要真实世界里重置实验、检索文献、提出方案、验证结果,再优化下一轮迭代。
和以往那些“代码即策略”的方法不同,ENPIRE的最终产物不是一段控制脚本,而是真正能部署到机器人上的Policy。
给现实环境搭建自动化框架,这件事难就难在:现实世界和代码世界是两码事。
在代码世界里,写错了大不了删掉重来,实验跑崩了重启就行。但机器人研究不一样——实验失败了,物体会歪掉,场景会乱掉,机器人甚至可能把东西碰飞。如果每轮实验都要靠研究员手动复位、记录结果、整理数据,Agent根本不可能24小时连续做研究。
所以ENPIRE做的,本质上就是给AI研究员搭建了一套自动化实验台。论文里把它称为
Harness Framework
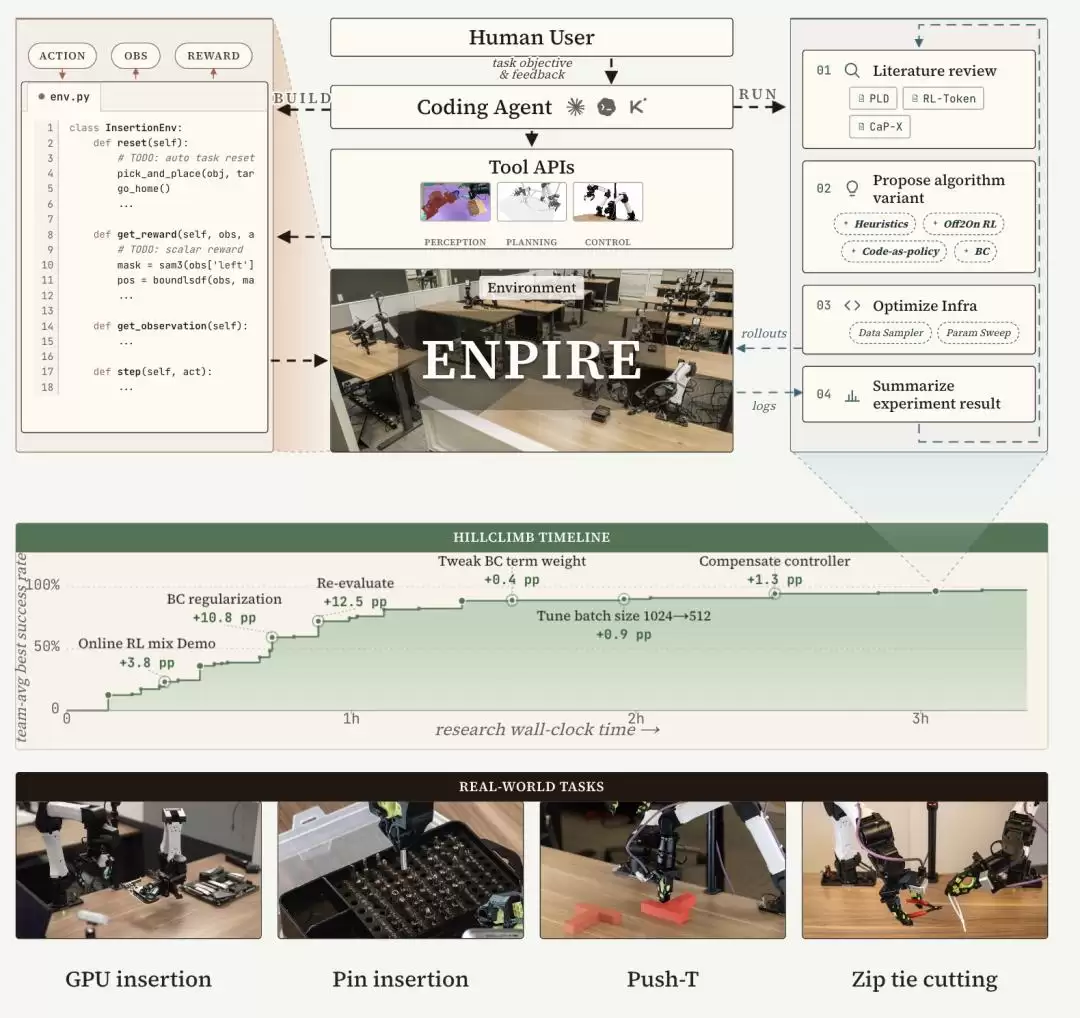
这套基础设施由四个模块组成,正好对应ENPIRE这个名字:
- :负责搭建实验环境,包括安全边界、自动复位和自动评分。
EN(Environment)环境模块
- :Agent根据任务目标提出新方案,行为克隆、强化学习、启发式规则,甚至混搭,都可以尝试。
PI(Policy Improvement)策略改进
- :把新策略部署到真实机器人上执行,记录轨迹、视频和传感器信号。
R(Rollout)部署测试
- :多个Agent协作的核心。8个Agent各占一台机器人,通过Git共享代码,互相借鉴有效方案,淘汰失败路线。
E(Evolution)进化
四个模块串起来,就形成了一个完整闭环:提出想法→训练策略→真机测试→自动评分→总结经验→再提出新想法。整个过程不需要人工值守,Agent自己负责做实验,也自己负责从实验里学习。
而这其中最关键的一环,其实是Environment模块。因为它解决的是具身智能研究里最令人头疼的问题:
怎么让实验自动跑起来。
在仿真环境里,复位往往只需要一句 env.reset()。但现实世界没有 env.reset()。
一次实验失败后,机器人必须先恢复场景的初始状态,下一轮实验才能开始。以GPU插拔任务为例,机器人需要先把GPU从主板上拔出来,再移动到指定位置释放,然后退回初始状态——整个过程涉及复杂的力控操作,稍有不慎就可能损坏GPU针脚。
自动评分同样不简单。比如在扎带穿扎任务中,Agent需要判断“扎带尾巴到底有没有穿过扎带头?”为了解决这个问题,它甚至自己设计了一套视觉检测方案:顶部和侧面两个摄像头同时观察目标区域,各自进行图像分割;只有当两个视角都确认扎带尾端穿过扎带头,系统才判定实验成功。整个检测延迟被压缩到150毫秒以内,已经接近人类视觉反应速度。

这些自动复位、自动评分、安全控制接口一旦调通,就会被固化为标准API。后续Agent做研究时,不再需要关心底层实验流程。由此,真实世界终于第一次变成了一个可以被反复调用、持续优化的研究环境。
好的Agent不比研究员差
好的Agent不比研究员差
当然,光有实验平台还不够。真正有意思的问题是:当你把机器人、GPU和Token都准备好之后,Agent到底会不会做研究?
ENPIRE给出的答案是:会,而且还真像那么回事。
论文在四个高难度灵巧操作任务上进行了验证:Push-T(推动T形积木到目标位置)、Pin Insertion(把针插进4毫米孔洞)、GPU Insertion(把GPU插进主板插槽)以及Zip-tie(扎带穿扎与剪切)。最终四个任务全部达到了99%的成功率。
但比结果更有意思的,是Agent达到这个结果的
过程
整个过程中,Agent就跟人类研究员一样,一步一步往上试,一路把成功率从接近零推到接近100%。没有人告诉它应该加什么模块,也没有人规定实验顺序。所有方案都来自它自己提出的假设,再通过真实实验验证。如果把这些记录隐藏起来,只看研究过程,很难说这和一个机器人博士生在实验室里做研究有什么本质区别。
更有意思的是,Agent甚至会根据任务特点主动改变研究路线。在Zip-tie任务中,它很快发现端到端训练效果不好——因为这个任务实在太长了:找到剪刀→抓起剪刀→找到扎带→对准位置→完成剪切。整个操作链跨越多个阶段,单纯依赖端到端策略很难学好。于是Agent自己换了一条路线:先利用VLA模型(Vision-Language-Action)完成粗定位,再调用工具API执行精细操作。某种程度上,它甚至自己做了一次系统架构设计。
如果要找一个最直接的参照物,那就是Karpathy前段时间提出的“Autoresearch”。两者本质上都在做同一件事:让AI自动提出想法、运行实验、比较结果,再根据结果继续迭代。区别在于,Autoresearch发生在数字世界,代码写崩了可以重来,实验跑错了可以重启,算力几乎是唯一成本。而ENPIRE第一次把这套研究循环搬进了物理世界——机器人不是代码,你没法对一台撞坏的机械臂执行Git Revert。真实世界里,摩擦力在变化,物体位置在变化,光照在变化,传感器也会产生噪声。
ENPIRE的核心价值,
就是通过自动复位、自动评分和安全控制接口,把原本混乱的物理世界包装成Agent能够反复调用的实验环境。
另一个有意思的发现,是所谓的“物理Scaling”。过去大模型Scaling的是参数、数据和算力,ENPIRE开始Scaling实验数量。论文里,8个Agent分别占用8台机器人,同时探索不同路线。结果Pin Insertion任务达到目标成功率的时间,从单机器人模式下的1.5小时缩短到40分钟。
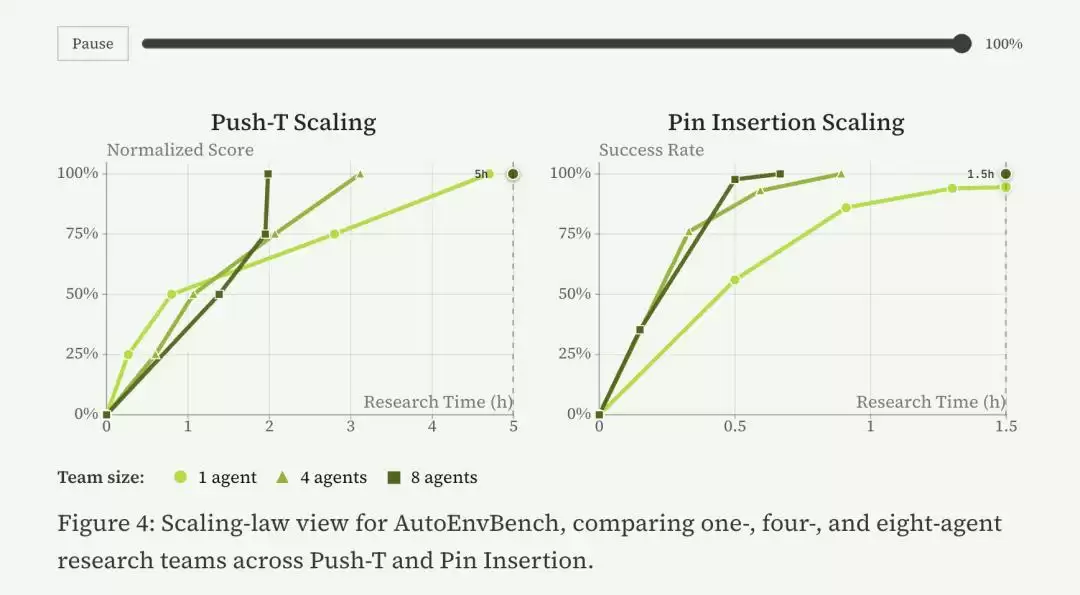
换句话说,如果过去的大模型是在扩展GPU集群,那么ENPIRE扩展的则是机器人舰队。
当然,这种Scaling并不便宜。随着Agent数量增加,每个Agent都需要阅读其他Agent的代码、理解别人的发现、总结经验并同步知识。Token消耗增长得比机器人数量更快。论文甚至专门提出两个指标来衡量这种代价:
Mean Robot Utilization
Mean Token Utilization
看到这里,大概也能理解为什么Jim Fan会这么兴奋——因为他们发现,研究本身似乎也开始具备了可扩展性。甚至连经验传承都出现了:论文里有个很有意思的实验,Agent在Pin Insertion任务中积累的经验被整理成一份文字总结,然后直接塞进GPU Insertion任务的Prompt里。结果后续研究效率明显提升。注意,这里迁移的既不是模型权重,也不是训练数据,而是一份研究笔记——和人类实验室传帮带时做的事情,几乎一模一样。
大平行的最后一块拼图
大平行的最后一块拼图
今年5月,Jim Fan在红杉资本AI Ascent大会上提出了
“大平行”(The Great Parallel)
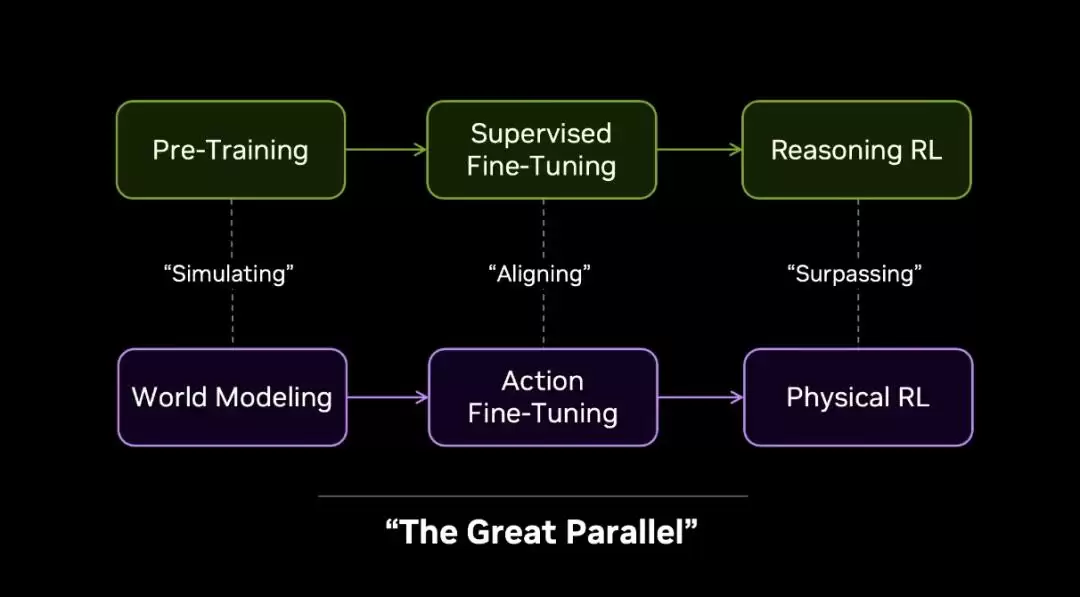
对照语言模型经历的四个阶段——预训练、对齐微调、强化学习推理、自主研究——机器人也在走同样的四步,只不过每一步的介质从文本变成了物理世界。前三步英伟达已经有了对应的布局:预训练阶段有EgoScale(用两万小时人类第一视角视频训练运动先验)和DreamZero(一种全新的世界动作模型,用视频世界模型预测下一物理状态,替代语言模型预测下一token);对齐阶段用少量传感化人类数据做动作微调;强化学习阶段有Dream Dojo(一个纯神经仿真器,不用物理引擎,直接用视频世界模型生成模拟环境,让机器人在“梦境”里做RL)。
但第四步——自主研究——在物理世界一直没有可执行的实现。ENPIRE,就是这一步。
一作
肖文力
肖文力是CMU机器人系博士生,导师是
石冠亚

肖文力、
谢佳
Tonghe Zhang
Haotian Lin
Jim Fan在推特上对ENPIRE的描述,大概是整篇论文最有画面感的概括:
我们给8个Codex agent一个机器人舰队、一批GPU和充足的token预算。然后人类退场。机器人舰队开始活过来:它们学会寻找视觉线索,重置场景,练习新技能,修改控制栈,在线读论文,辩论,反思,卡壳,再直接在硬件上重试。我们所做的一切,就是给Codex一个通往原子世界的API。剩下的是涌现。
ENPIRE将全部开源。理论上,每个人都可以搭建自己的“自运行机器人实验室”。前提是——你得买得起那8台机器人、英伟达的GPU,以及跑coding agent的token。
参考链接
[1]https://x.com/_wenlixiao/status/2066913196641071464
[2]https://research.nvidia.com/labs/gear/enpire/#fleet-scaling




