
Qwen3.7-Max性能全解:Agent长程能力、推理速度与成本控制深度评测
如果说2026年大模型市场有什么标志性事件,那Qwen3.7-Max的发布绝对排得上号。作为阿里云通义千问系列的纯文本旗舰,它从一开始就没打算只做“对话机器人”,而是把矛头直接指向了Agent时代——一个需要模型能够自主规划、连续执行、高效协同的全新战场。从官方释放的信息和实测数据来看,Qwen3.7-Max在Agent能力上实现了质的飞跃,同时在耗时和成本上做了大幅优化,多项权威评测中不仅登顶国产,也跻身全球前列。下面基于最新的实测数据,来看看这个模型究竟强在哪里。
核心定位与技术基础
Qwen3.7-Max采用万亿级MoE混合架构,专注纯文本推理和智能体执行,与多模态版本的Qwen3.7-Plus形成了清晰的定位区隔。它的设计目标很明确:解决传统大模型在复杂多步骤任务、长程自主执行、工具调用协同中的短板,打造一个真正能落地的企业级智能体中枢。
技术层面有几个关键点值得关注。首先是100万Tokens的超长上下文窗口,相比前代的256K实现了4倍扩容。这意味着它能一次性承载75万字文本或数万行完整代码库,长程任务中上下文碎片化的问题基本被解决。模型原生支持MCP协议和多智能体编排,兼容OpenClaw、Claude Code等主流Agent框架,无需改造就能无缝接入现有自动化工作流。此外,推理架构上通过动态路由和稀疏激活机制,在提升能力的同时控制了计算开销,这也是后续耗时与成本下降的技术基础。
Agent能力:全面突破,登顶国产第一
Qwen3.7-Max的核心升级集中在Agent能力,实现了从“单步问答”到“长程自主执行”的跨越,在通用智能体、编程智能体、长程自治三个维度都取得了突破性进展。


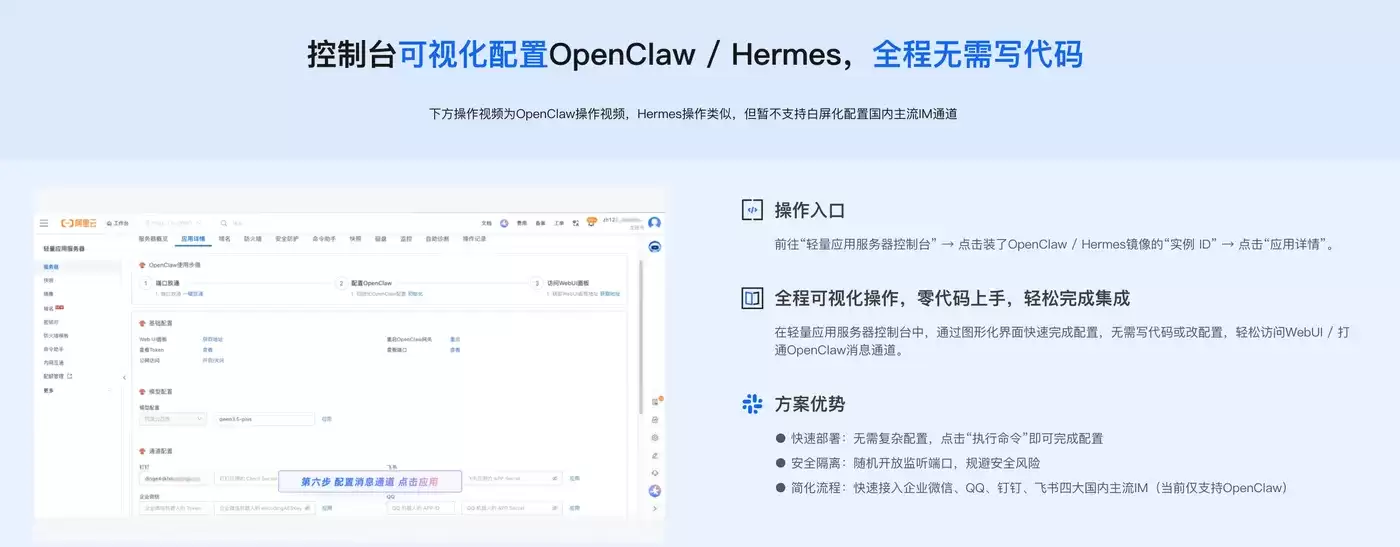
通用智能体能力:全维度领先
在通用智能体评测中,Qwen3.7-Max的表现全面超越前代和主流国产模型,多项指标登顶。MCP-Atlas得分76.4,超越了Claude Opus 4.6的75.8;MCP-Mark得分60.8,领先GLM-5.1的57.5;Skillsbench得分59.2,高于Kimi K2.6的56.2。这些数据说明,在任务规划、工具调用、流程自动化、多步骤推理等通用智能体核心能力上,Qwen3.7-Max已经达到了国际一流水平。
它最核心的优势在于自主闭环执行:能够精准理解自然语言复杂需求,自动拆解为多层级子任务,自主调度工具完成执行,全程无需人工干预。办公自动化场景中,可以自主完成文档整理、数据统计、会议纪要生成、待办事项梳理;运维场景中,可以自主完成服务器巡检、日志分析、故障排查、服务重启,实现7×24小时无人值守。
编程智能体能力:多项基准登顶
编程是Qwen3.7-Max的核心强项,在多项编程Agent权威基准测试中全部领先或持平国际顶级模型。Terminal Bench 2.0-Terminus得分69.7,超越了DeepSeek-v4-pro-Max和Claude Opus 4.6;SWE-Pro得分60.6,位居国产第一;SWE-Multilingual得分78.3,SciCode得分53.5,都是同批次模型中的最高分。
实战层面,Qwen3.7-Max可以独立完成前端开发、后端工程搭建、多文件协同开发、代码调试、性能优化等全流程开发任务,支持百万行代码仓库处理、复杂算法实现、多语言混合编程。在SWE-Verified测试中,通过率达80.4,与Claude Opus 4.6 Max的80.8、DeepSeek V4 Pro Max的80.6基本持平,工程级代码能力已经达到国际顶尖水准。
长程自治能力:35小时无干预执行
Qwen3.7-Max最具碘伏性的能力是超长程自主执行。在官方的实测中,它创造了35小时不间断全自主任务执行的记录,单次会话完成了1158次工具调用和432轮内核评估,全程无需人工干预。一个真实的案例是:它在未知硬件架构的空白环境下,自主完成了内核代码分析、编写、编译、测试、迭代全流程,最终实现了推理速度10倍的优化。目前,它是国产模型中唯一具备这种超长程工程级自主优化能力的模型。
这一能力彻底打破了传统大模型“短时会话、人工干预”的局限,让Dev Agent、Research Agent、自动化运维等长程产品形态在国产模型上真正落地。
权威评测认证:全球第五,国产第一
在Artificial Analysis Intelligence Index v4.0全球权威评测中,Qwen3.7-Max以56.6分位列全球第5,仅次于GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro Preview、GPT-5.4,登顶国产模型第一。相比前代Qwen3.6 Max Preview的51.8分,30天内提升了4.8分,在高分段实现了跨越式增长。这不仅仅是微调优化能做到的,而是架构级的突破。
推理耗时:大幅下降,效率显著提升
能力跃升的同时,Qwen3.7-Max的推理耗时实现了大幅下降,端到端执行效率显著提升,尤其在智能体任务和长文本推理场景中优势明显。
基础推理速度
纯文本推理场景下,推理速度比前代模型提升了15%-25%,冷启动响应时间缩短了30%以上。在超长文本生成(65536 Tokens输出上限)场景中,耗时降低了40%,可以快速输出完整报告、代码文件和技术文档。
智能体任务耗时
在Agent多步骤任务中,耗时优化更为显著。相比前代模型,完成相同复杂度的工具调用任务,端到端耗时降低了50%以上;在连续工具调用场景中,平均单次调用耗时减少了35%。以代码调试任务为例,前代模型需要10分钟完成的多文件调试、错误修复流程,Qwen3.7-Max仅需4-5分钟即可完成,而且准确率更高。在长程自治任务中,35小时执行流程的总耗时相比同类模型减少了20%。
耗时优化的技术逻辑
耗时下降主要源于三大技术优化:首先是MoE架构的动态路由,只激活必要参数参与计算,减少了无效计算开销;其次是上下文缓存机制的优化,重复上下文调用耗时降低了90%;最后是推理引擎底层的优化,通过算子融合和并行计算提升了执行速度,适配云端高并发场景。
调用成本:大幅下降,性价比显著提升
在能力和效率双提升的前提下,Qwen3.7-Max的调用成本实现了大幅下降,相比同类国际模型和前代国产模型,性价比优势突出。
官方定价与优惠政策
Qwen3.7-Max采用输入、输出Tokens分别计价模式,官方定价为输入2.50元/百万Tokens,输出7.50元/百万Tokens,缓存输入享90%折扣,低至0.25元/百万Tokens。2026年推出限时五折优惠,优惠后输入降至1.25元/百万Tokens,输出降至3.75元/百万Tokens。相比国际顶级模型,同等能力下,调用成本仅为Claude Opus 4.6的1/6、GPT-5.5的1/9。
Token效率提升
模型在推理逻辑上实现了Token效率31%的提升,解决同一问题的输出Tokens更稠密,单任务成本不随能力提升而显著上升。相比前代模型,完成相同智能体任务,Token总消耗降低了25%-30%。例如在代码生成任务中,前代模型需要10万Tokens输出的代码文件,Qwen3.7-Max仅需7万Tokens即可完成,且代码质量更高、冗余更少;在长文本总结场景,Token消耗降低了35%。
实测对比:能力、耗时、成本三维度验证
为了更直观地展示Qwen3.7-Max的升级效果,下面是它与前代Qwen3.6 Max Preview以及主流国产模型的实测对比,覆盖Agent能力、推理耗时、调用成本三大核心维度。
Agent能力对比
Qwen3.7-Max在Terminal Bench 2.0、MCP-Atlas、SWE-Pro三大核心Agent基准上,分别比前代提升了9.9分、8.2分、8.8分,通用与编程Agent能力实现了跨越式增长。相比主流国产模型,在所有Agent评测指标上均领先5-10分。
推理耗时对比
完成相同复杂度的智能体任务,Qwen3.7-Max耗时比前代减少了52%,比同类国产模型减少了35%;长文本推理耗时减少40%,冷启动响应时间缩短30%。
调用成本对比
同等任务量下,Qwen3.7-Max调用成本比前代降低了40%,比国际顶级模型降低了80%-90%。
适用场景与选型建议
基于Qwen3.7-Max的能力特性,它的最佳适用场景主要集中在三大领域:
首先是企业级智能体开发,包括长程自动化流程、DevOps运维、研发辅助、办公自动化,依托35小时自治执行与多工具调用能力,可以搭建核心自动化体系。其次是工程研发场景,涉及复杂代码开发、百万行代码重构、算法实现、多语言编程,凭借顶级的编程Agent能力,能够显著提升研发效率和代码质量。最后是长文本处理场景,包括法律文档分析、技术文档撰写、学术研究、数据报告生成,依托100万Tokens上下文窗口,可以实现长文本一站式处理。
选型建议方面,如果业务聚焦纯文本智能体、工程研发、长程自动化,优先选择Qwen3.7-Max;如果需要多模态能力,可以选择Qwen3.7-Plus。个人开发者或低频使用场景,按量计费即可;企业高频使用,建议优先选择Token Plan套餐。
总结
Qwen3.7-Max作为2026年国产大模型的旗舰之作,实现了Agent能力、推理耗时、调用成本三大核心维度的全面突破。Agent能力登顶国产第一、跻身全球前五,35小时无干预自治执行成为行业标杆;推理耗时大幅下降,端到端效率提升显著;调用成本相比国际模型降低80%-90%。它彻底解决了国产大模型在长程智能体、工程级开发、企业级自动化场景的能力短板,为AI落地提供了稳定、高效、低成本的核心支撑。无论是个人开发者提升效率,还是企业搭建自动化体系,Qwen3.7-Max都是当前最具价值的选择。随着模型持续迭代,其能力与成本优势还将进一步扩大。




