
Qwen3.7 API 与 Token Plan 调用实战:从零到生产的完整指南
Qwen3.7 API 与 Token Plan 调用实战:从零到生产的完整指南
先说一个实际场景。上周团队接到一个需求:给内部运维平台接入大模型能力,实现日志智能分析、故障根因定位和自动化修复建议。技术选型会上,大家争论不休——选哪个模型?怎么调用?成本怎么控制?API 稳定性如何保障?
这其实是很多团队都会面临的困境:大模型能力很强,但从“知道”到“用上”之间,还有一长串工程问题要解决。这篇文章就从实际项目出发,把整个流程——从百炼平台注册、API Key 管理、到 Qwen3.7-Max/Plus 模型调用、Token Plan 订阅配置——完整走一遍,附带 Python 和 Ja va 的代码示例、成本对比分析,以及生产环境最容易踩的几个坑。
1. 场景:为什么我们需要 Qwen3.7 API
回到刚才说的运维平台场景。日志分析和故障定位这类任务,对模型的推理能力要求很高。传统的规则引擎很难应对复杂、多变的异常模式,而大模型正好能补上这块短板。
1.1 Qwen3.7-Max 核心能力
Qwen3.7-Max 是阿里云通义千问系列 2026 年发布的旗舰模型,专为智能体(Agent)时代设计。它不只是一个对话模型的升级版,而是从“说得好”到“做得到”的一次范式跃迁。
核心能力数据如下:
| 能力维度 | 评测基准 | 得分 | 说明 |
|---|---|---|---|
| 推理 | GPQA Diamond | 92.4 | 超越 Claude Opus-4.6(91.3) |
| 编程智能体 | SWE-Verified | 80.4 | 业界顶尖水平 |
| 编程智能体 | SWE-Pro | 60.6 | 复杂工程任务 |
| 终端编程 | Terminal-Bench 2.0 | 69.7 | 超越 DeepSeek V4 Pro |
| 工具调用 | MCP-Mark | 60.8 | 国产第一 |
| 长周期执行 | 自主运行 | 35小时 | 1158次工具调用 |
最值得关注的是那个 35 小时自主执行能力:Qwen3.7-Max 仅凭一份硬件说明书,在无人干预的情况下,连续工作 35 小时、执行 1158 次工具调用,将芯片推理速度提升 10 倍。这不是演示 Demo,是真实的生产级表现。
1.2 Qwen3.7 模型矩阵
Qwen3.7 系列目前提供两个主力模型,定位差异很明显:

选型建议其实很直接:
- 需要最强推理和编程能力 → Qwen3.7-Max
- 需要多模态理解(图片/视频) + 高性价比 → Qwen3.7-Plus
- 简单任务、追求速度和低成本 → Qwen3.6-Flash
回到我们的运维平台需求,日志分析和故障定位需要强推理能力,最终选择了 Qwen3.7-Max。
2. 百炼平台注册与 API Key 管理
2.1 注册流程
从零开始接入 Qwen3.7 API,第一步是完成阿里云百炼平台的注册和开通。
完整路径:阿里云账号 → 实名认证 → 开通百炼 → 创建 API Key
具体步骤:
- 访问阿里云百炼控制台
- 使用阿里云账号登录(没有账号先注册)
- 完成实名认证(个人填身份证,企业填营业执照)
- 首次进入控制台,点击“免费体验”开通服务
- 同意服务协议,10 秒左右完成开通
百炼新用户可获得 100 万 Tokens 免费额度(Qwen3.7-Max),有效期 90 天。这个额度足够完成前期测试和验证,不用急着充钱。
2.2 创建 API Key
开通服务后,需要创建 API Key 才能调用接口:
- 进入百炼控制台左侧菜单 → “API-KEY 管理”
- 点击“创建 API Key”
- 选择归属业务空间(建议默认)和权限(建议全部)
- 点击确定,系统生成
sk-前缀的密钥字符串
有一个关键提醒:API Key 生成后仅展示一次,务必立即复制保存。页面刷新后无法再次查看完整密钥。如果忘了保存,只能删除旧密钥重新创建。这个细节很多新手容易忽略,导致后续排查问题时还得再折腾一次。
2.3 配置环境变量
将 API Key 配置到环境变量,避免硬编码在代码中导致泄露风险。这是生产环境的基本安全要求,没有商量余地。
# macOS/Linux:添加到 ~/.bashrc 或 ~/.zshrc
export DASHSCOPE_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# 使配置生效
source ~/.zshrc
# Windows:通过系统设置 → 环境变量 添加
# 或在 PowerShell 中临时设置
$env:DASHSCOPE_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
2.4 验证 API 连通性
在写业务代码之前,先用 curl 验证 API Key 和网络连通性,快速排除配置问题。这一步能省掉不少后续排查的时间。
# 测试 Qwen3.7-Max API 连通性
curl -X POST "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions" \
-H "Authorization: Bearer $DASHSCOPE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.7-max",
"messages": [
{"role": "user", "content": "你好,请用一句话介绍你自己"}
]
}'
如果返回包含 "choices" 字段的 JSON 响应,说明 API 连通正常。如果返回 401 错误,检查 API Key 是否正确;如果返回 400 错误,检查请求体格式。
3. Qwen3.7-Max API 调用实战
3.1 OpenAI 兼容协议
百炼平台全面兼容 OpenAI API 协议。这意味着你只需要修改三个参数就能把现有 OpenAI 代码迁移过来:
| 参数 | OpenAI 原值 | 百炼替换值 |
|---|---|---|
| base_url | https://api.openai.com/v1 | https://dashscope.aliyuncs.com/compatible-mode/v1 |
| api_key | sk-xxx(OpenAI Key) | sk-xxx(百炼 Key) |
| model | gpt-4 | qwen3.7-max |
这个兼容性设计非常友好,迁移成本几乎为零。如果你之前用过 OpenAI 的 SDK,切换到 Qwen3.7 基本就是改个配置的事。
3.2 Python 调用示例
Python 是 AI 开发的主流语言,使用 openai SDK 调用百炼是最常见的方式。以下代码涵盖非流式和流式两种模式,完整可运行。
# pip install -U openai
from openai import OpenAI
import os
# 初始化客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ========== 非流式调用 ==========
def call_sync():
"""非流式调用:等待完整响应返回,适合批量处理"""
response = client.chat.completions.create(
model="qwen3.7-max",
messages=[
{ "role": "system", "content": "你是一个专业的运维工程师助手。"},
{ "role": "user", "content": "分析以下日志中的异常:ERROR Connection timeout to database master after 30s"}
],
temperature=0.7,
max_tokens=2048
)
print("【非流式响应】")
print(f"模型: {response.model}")
print(f"内容: {response.choices[0].message.content}")
print(f"Token 用量: 输入{response.usage.prompt_tokens}, 输出{response.usage.completion_tokens}")
# ========== 流式调用 ==========
def call_stream():
"""流式调用:逐字输出,适合实时交互场景"""
stream = client.chat.completions.create(
model="qwen3.7-max",
messages=[
{ "role": "system", "content": "你是一个专业的运维工程师助手。"},
{ "role": "user", "content": "分析以下日志中的异常:ERROR Connection timeout to database master after 30s"}
],
temperature=0.7,
max_tokens=2048,
stream=True
)
print("【流式响应】")
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print()
if __name__ == "__main__":
call_sync()
print("-" * 50)
call_stream()
3.3 Ja va 调用示例
企业级项目大量使用 Ja va,以下代码使用 OkHttp 直接调用 REST API,无需额外 SDK 依赖,适合集成到 Spring Boot 项目中。
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import ja va.util.List;
import ja va.util.Map;
import ja va.util.concurrent.TimeUnit;
public class Qwen37MaxClient {
private static final String BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions";
private static final String API_KEY = System.getenv("DASHSCOPE_API_KEY");
private final OkHttpClient httpClient = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(120, TimeUnit.SECONDS) // Qwen3.7-Max 思考模式可能耗时较长
.writeTimeout(30, TimeUnit.SECONDS)
.build();
private final ObjectMapper mapper = new ObjectMapper();
/**
* 非流式调用 Qwen3.7-Max
*/
public String chat(String systemPrompt, String userMessage) throws Exception {
Map requestBody = Map.of(
"model", "qwen3.7-max",
"messages", List.of(
Map.of("role", "system", "content", systemPrompt),
Map.of("role", "user", "content", userMessage)
),
"temperature", 0.7,
"max_tokens", 2048
);
String jsonBody = mapper.writeValueAsString(requestBody);
Request request = new Request.Builder()
.url(BASE_URL)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.post(RequestBody.create(jsonBody, MediaType.parse("application/json")))
.build();
try (Response response = httpClient.newCall(request).execute()) {
if (!response.isSuccessful()) {
throw new RuntimeException("API 调用失败: " + response.code() + " - " + response.body().string());
}
JsonNode root = mapper.readTree(response.body().string());
return root.path("choices").path(0).path("message").path("content").asText();
}
}
public static void main(String[] args) throws Exception {
Qwen37MaxClient client = new Qwen37MaxClient();
String result = client.chat(
"你是一个专业的运维工程师助手。",
"分析以下日志中的异常:ERROR Connection timeout to database master after 30s"
);
System.out.println("响应内容: " + result);
}
}
3.4 流式 vs 非流式选择
| 场景 | 推荐模式 | 原因 |
|---|---|---|
| 聊天对话界面 | 流式 | 用户体验好,逐字输出 |
| 批量数据处理 | 非流式 | 代码简单,便于错误处理 |
| API 后端服务 | 非流式 | 结果完整,便于解析 |
| 智能体长任务 | 流式 | 实时观察执行过程 |
Qwen3.7-Max 支持思考模式(Think Mode),在思考模式下模型会先进行深度推理再给出回答。思考模式的输出 Token 包含思维链和最终回答两部分,计费时均按输出 Token 计算。这个细节在后面成本部分还会再讲。
4. Token Plan 订阅模式详解
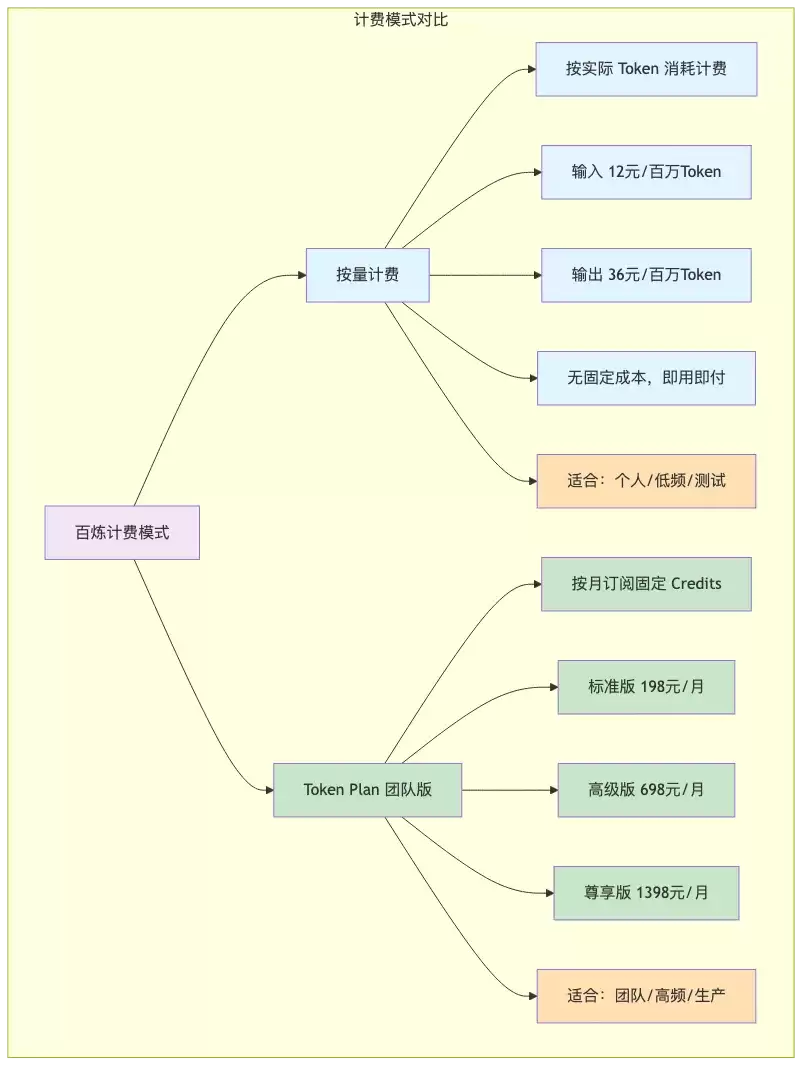
4.1 按量计费 vs Token Plan
当团队从测试走向生产,成本控制就变成了核心问题。百炼提供两种计费模式:
4.2 三档套餐详解
Token Plan 团队版提供三个档位,以 Credits 统一计量:
| 套餐 | 月费 | Credits 额度 | 适用场景 |
|---|---|---|---|
| 标准坐席 | 198 元 | 25,000 Credits | 轻度使用 AI 辅助的办公人员 |
| 高级坐席 | 698 元 | 100,000 Credits | 日常高频 AI 编程或办公 |
| 尊享坐席 | 1,398 元 | 250,000 Credits | 重度依赖 AI 的核心开发者 |
Credits 抵扣规则:
- 优先从坐席套餐月度额度抵扣
- 坐席额度用尽后,从共享用量包抵扣(5,000 元/个,625,000 Credits)
- 全部用尽后服务暂停至下一计费周期
以 qwen3.6-plus 为例,单次请求的 Credits 消耗预估:
| Token 类型 | 数量 | 消耗 Credits |
|---|---|---|
| 输入 Tokens | 8,349 | 1.67 |
| 缓存 Tokens | 40,794 | 0.82 |
| 输出 Tokens | 573 | 0.69 |
| 合计 | — | 约 3.18 |
4.3 Token Plan 专属特性
Token Plan 订阅用户享有以下专属权益:
- 专属 API Key:以
sk-sp-开头,与通用 API Key(sk-开头)隔离 - 专属 Base URL:
https://token-plan.cn-beijing.maas.aliyuncs.com/compatible-mode/v1 - 高峰期不降速:多租户隔离架构,调用高峰期间不排队
- 数据安全:承诺不使用对话数据训练模型
- 多模型切换:支持 qwen3.7-max、qwen3.7-plus、deepseek-v4-pro、kimi-k2.6 等
需要注意一个限制:Token Plan 团队版目前仅支持华北2(北京)地域,且仅限在 AI 编程工具和 OpenClaw 类型 Agent 中使用。不支持 Dify、n8n、Coze 等工作流平台,也不支持 Postman 等 API 测试工具和自定义应用程序。如果你打算集成到自己的业务系统里,这一点要提前确认清楚。
4.4 Token Plan 配置步骤
Token Plan 使用专属 API Key 和 Base URL,配置方式与按量计费不同,需要单独设置。
# Token Plan 专属配置
from openai import OpenAI
import os
# Token Plan 使用专属 API Key(sk-sp- 前缀)和专属 Base URL
client = OpenAI(
api_key=os.getenv("TOKEN_PLAN_API_KEY"), # sk-sp-xxx
base_url="https://token-plan.cn-beijing.maas.aliyuncs.com/compatible-mode/v1"
)
response = client.chat.completions.create(
model="qwen3.7-max",
messages=[{ "role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
4.5 成本计算器
什么场景下 Token Plan 更划算?我们来算一笔账。
假设使用 Qwen3.7-Max,按量计费价格为输入 12 元/百万 Token、输出 36 元/百万 Token。典型场景下输入与输出 Token 比例约为 3:1。
| 月调用量级 | 按量计费月成本 | Token Plan 月成本 | 节省比例 |
|---|---|---|---|
| 50 万 Token | 约 15 元 | 198 元(标准版) | 按量更划算 |
| 200 万 Token | 约 60 元 | 198 元(标准版) | 按量更划算 |
| 500 万 Token | 约 150 元 | 198 元(标准版) | 接近持平 |
| 1000 万 Token | 约 300 元 | 198 元(标准版) | Token Plan 省 34% |
| 3000 万 Token | 约 900 元 | 698 元(高级版) | Token Plan 省 22% |
| 8000 万 Token | 约 2400 元 | 1398 元(尊享版) | Token Plan 省 42% |
结论很清晰:月调用量超过 500 万 Token 时,Token Plan 开始显现成本优势。此外,Token Plan 还有高峰期不降速、数据安全等非价格优势,生产环境建议优先考虑。
5. 生产环境避坑指南
坑1:API Key 泄露风险
API Key 硬编码在代码中,一旦提交到 Git 仓库就可能泄露。有过团队因此产生了数万元的异常调用费用,教训不可谓不深刻。
解决方案:
- 始终使用环境变量存储 API Key
- 代码中通过
os.getenv()读取,绝不硬编码 - 使用
.env文件时,确保.gitignore中包含.env - 为不同环境(开发/测试/生产)使用不同的 API Key
- 百炼支持创建临时 API Key(有效期 60 秒),适合第三方授权场景
# .gitignore 中务必添加
.env
.env.local
.env.production
坑2:流式输出的超时配置
Qwen3.7-Max 在思考模式下,模型可能需要较长时间进行推理后才开始输出。默认的 HTTP 超时配置往往不够,导致请求中断。
解决方案:
# Python:设置合理的超时时间
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
timeout=180.0 # 思考模式建议至少 180 秒
)
// Ja va:OkHttp 超时配置
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(180, TimeUnit.SECONDS) // 思考模式需要更长读超时
.writeTimeout(30, TimeUnit.SECONDS)
.build();
坑3:Token 计费边界
很多开发者以为只有最终回答才计费,但实际上思考模式下的思维链 Token 也按输出价格计费。
关键规则:
- 输入 Token:按输入单价计费
- 输出 Token:包含思维链 + 最终回答,均按输出单价计费
- 缓存 Token:显式缓存按输入单价的 10% 计费,隐式缓存按 20%
- Batch 调用:输入和输出均按实时推理价格的 50% 计费
- 上下文缓存与 Batch 折扣不能同时生效
省钱建议:对于重复性高的系统提示词,开启上下文缓存可节省 80%-90% 的输入成本。
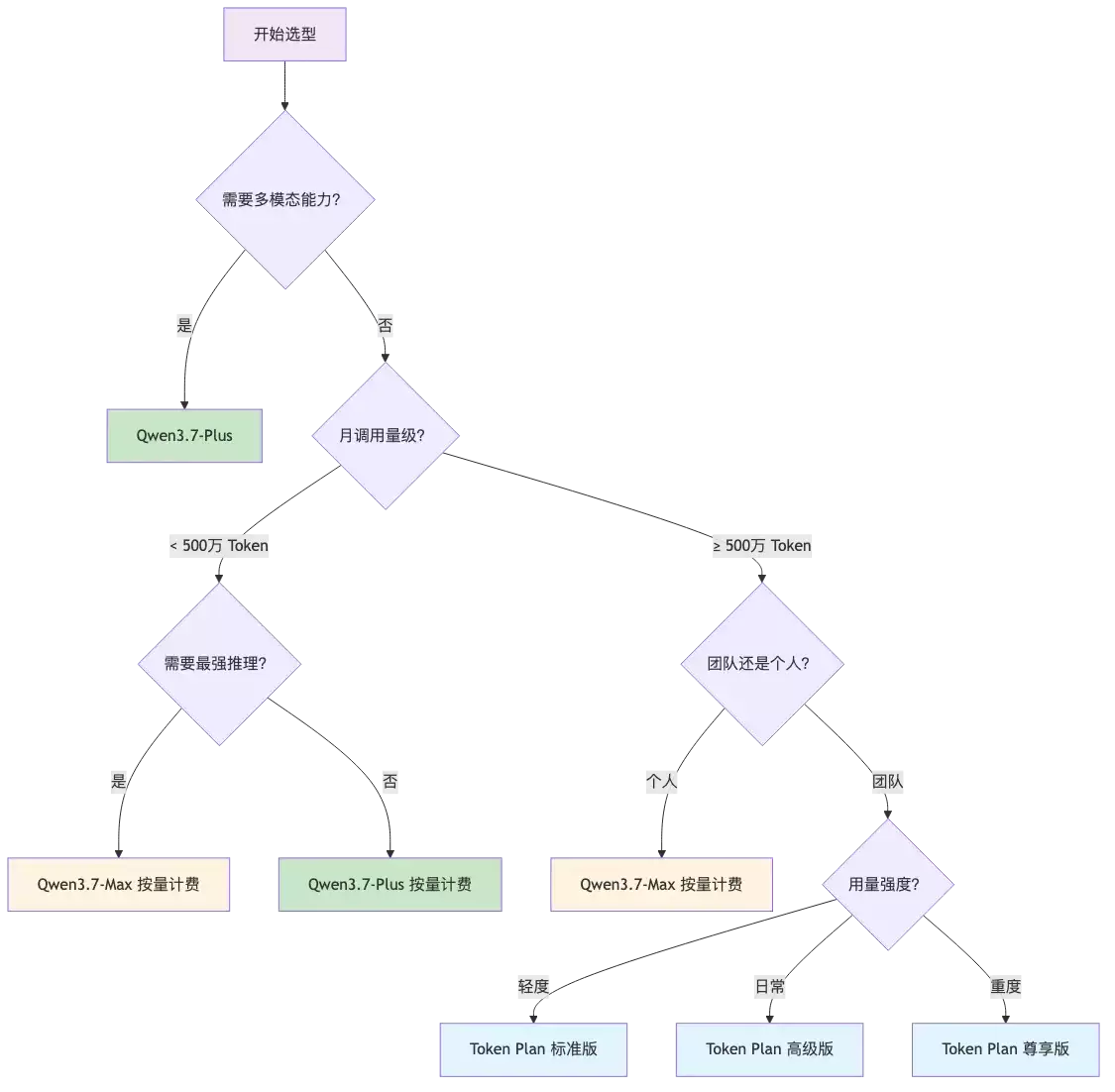
坑4:Qwen3.7-Max vs Plus 选型
盲目选择最贵的 Max 模型,很容易导致成本浪费。
选型建议:
| 需求 | 推荐模型 | 原因 |
|---|---|---|
| 复杂推理、数学证明 | Qwen3.7-Max | GPQA Diamond 92.4 分 |
| 多文件编程、代码重构 | Qwen3.7-Max | SWE-Verified 80.4 分 |
| 图片/视频理解 | Qwen3.7-Plus | Max 不支持多模态 |
| 日常对话、简单编程 | Qwen3.7-Plus | 性价比高,输入仅 2 元/百万 Token |
| 简单问答、分类任务 | Qwen3.6-Flash | 速度最快,成本最低 |
特别注意:Qwen3.7-Max 是纯文本模型,不支持图片和视频输入。如果需要多模态能力,必须选择 Qwen3.7-Plus。
坑5:并发限制与重试策略
高并发场景下,API 请求可能被限流,返回 429 错误。
解决方案:
# 使用指数退避重试策略
import time
from openai import OpenAI, APITimeoutError, RateLimitError
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
max_retries=3 # SDK 内置重试
)
def call_with_retry(messages, max_retries=5):
"""带指数退避的 API 调用"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.7-max",
messages=messages,
temperature=0.7
)
return response
except RateLimitError:
wait_time = 2 ** attempt # 指数退避:1s, 2s, 4s, 8s, 16s
print(f"触发限流,{wait_time}秒后重试...(第{attempt+1}次)")
time.sleep(wait_time)
except APITimeoutError:
print(f"请求超时,重试中...(第{attempt+1}次)")
continue
raise Exception(f"重试{max_retries}次后仍然失败")
6. 成本对比与选型建议
6.1 不同调用量级成本对比
以 Qwen3.7-Max 按量计费为例(输入 12 元/百万 Token,输出 36 元/百万 Token,假设输入输出比 3:1):
| 场景 | 月输入 Token | 月输出 Token | 按量月费 | 推荐 Token Plan | 月费 | 方案 |
|---|---|---|---|---|---|---|
| 个人学习 | 50 万 | 17 万 | 12 元 | — | — | 按量计费 |
| 小项目 | 300 万 | 100 万 | 72 元 | — | — | 按量计费 |
| 团队开发 | 1000 万 | 333 万 | 240 元 | 标准版 | 198 元 | Token Plan |
| 日常生产 | 3000 万 | 1000 万 | 720 元 | 高级版 | 698 元 | Token Plan |
| 高频生产 | 8000 万 | 2667 万 | 1920 元 | 尊享版 | 1398 元 | Token Plan |
6.2 选型决策树
6.3 推荐方案
| 用户类型 | 推荐方案 | 月预算 | 说明 |
|---|---|---|---|
| 个人开发者 | 按量计费 + 免费额度 | 0-100 元 | 先用免费额度测试,再按需付费 |
| 小团队(3-5人) | Token Plan 标准版 × 3 | 594 元 | 每人独立坐席,预算可控 |
| 中型团队(5-15人) | Token Plan 高级版 × 5 | 3,490 元 | 高频使用者配高级坐席 |
| 企业级(15人+) | Token Plan 尊享版 + 共享用量包 | 5,000+ 元 | 核心开发者配尊享,加购共享包兜底 |
7. 总结与下一步
回顾一下核心要点:
- :Qwen3.7-Max 适合强推理和编程场景,Qwen3.7-Plus 适合多模态和高性价比场景
模型选型
- :百炼平台兼容 OpenAI 协议,迁移成本极低,只需改三个参数
API 接入
- :月调用量超 500 万 Token 时,Token Plan 比按量计费更划算
成本控制
- :API Key 必须通过环境变量管理,绝不硬编码
安全第一
- :思考模式下读超时至少设 180 秒,避免请求中断
超时配置
- :思维链 Token 也按输出计费,开启上下文缓存可大幅节省输入成本
计费细节
这篇文章解决了“怎么调用”的问题,接下来可以深入探讨:
- MCP Server 开发实战:如何让 Qwen3.7-Max 调用你的业务工具
- AI Agent 框架实战:基于 Qwen3.7-Max 构建自主执行的智能体
- 百炼平台高级特性:Batch 调用、上下文缓存、Fine-tuning 实践




