
SenseNova U1 - 商汤日日新推出的原生统一多模态模型
最近AI圈有个新动向挺有意思:商汤的SenseNova U1模型开源了。这可不是一次简单的版本更新,它背后代表的技术路线,或许正在重新定义我们对“多模态”的想象。
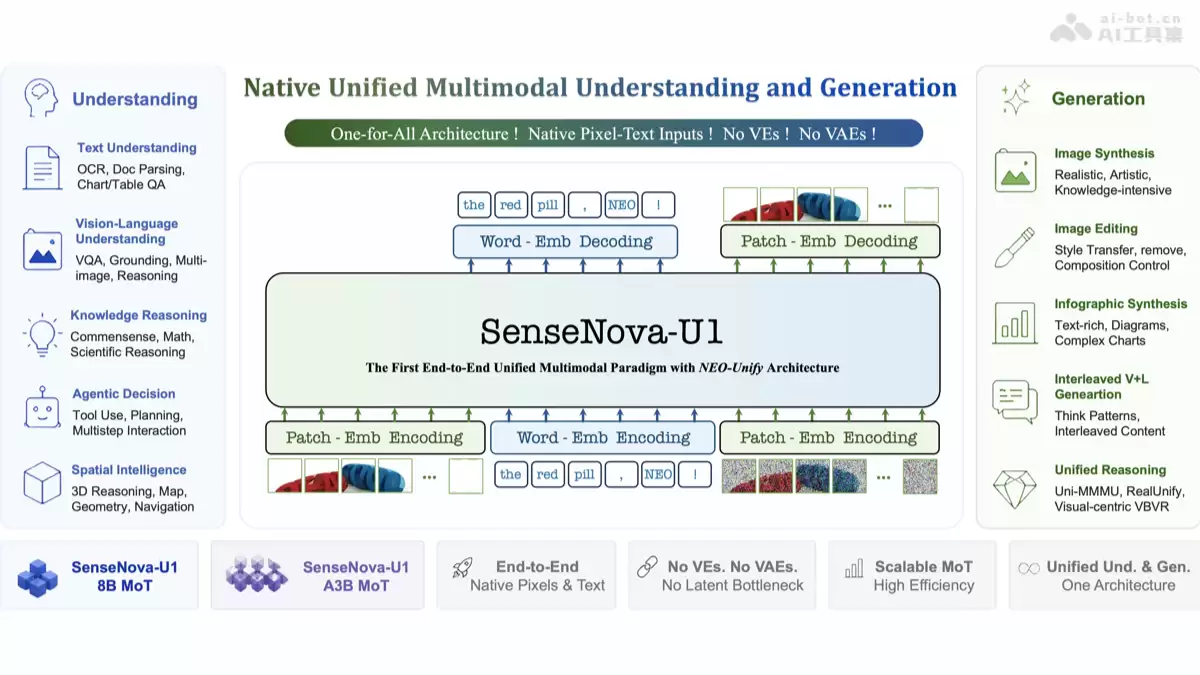
简单来说,SenseNova U1是商汤基于其NEO-Unify架构推出的原生统一多模态模型。它的核心突破在于,首次在单一架构内,真正实现了理解、推理与生成三大能力的统一。这听起来有点抽象?别急,我们慢慢拆解。
传统多模态模型是怎么做的?通常是“拼接”路线:一个视觉编码器负责“看”图,一个大语言模型负责“理解”和“说”话,中间再加个适配器来翻译。这种模式就像用胶水把几个独立的模块粘在一起,信息在传递过程中难免有损耗和延迟。
而SenseNova U1走的是另一条路——从“第一性原理”出发,彻底重构。它干掉了传统的视觉编码器和VAE(变分自编码器),直接把图像像素和文本信息,放在同一个表征空间里进行端到端建模。这就好比,它不再需要把中文翻译成英文再理解,而是天生就懂“图文混合”的这门语言。
这种原生统一的架构,带来了几个立竿见影的优势:信息流转路径更短,推理速度自然更快;模型内部没有“翻译”损耗,理解与生成的协同也更精准。根据官方数据,其8B版本在多项基准测试中达到了同量级开源模型的SOTA(最优水平),甚至能比肩部分商业闭源模型,而推理延迟却显著更低。
SenseNova U1的主要功能
那么,这个“统一”的模型具体能干什么?它的能力矩阵相当全面:
- 从基础的OCR文字识别、文档解析,到复杂的图表问答、视觉问答乃至多图关联推理,都不在话下。
多模态理解:
- 不仅能生成写实或艺术风格的图像,更能处理知识密集型的内容,比如合成一张包含复杂数据的信息图。编辑能力上也支持风格迁移、目标移除、构图控制等精细操作。
图像生成与编辑:
- 这是它“统一性”的直观体现。模型可以像人类写文章一样,自然地交替输出文字和图片。同时,它在需要结合视觉与文本的数学、常识与科学推理任务上,也展现出了强大能力。
交错生成与统一推理:
SenseNova U1的技术原理
实现这些功能,靠的是底层技术的彻底革新。我们可以重点关注以下几点:
- 这是根本。它摒弃了添加视觉编码器(VE)的常规做法,从源头将视觉和语言视为统一信号进行处理。
NEO-Unify原生架构:
- 像素和文本token在同一个空间内被直接建模和优化,消除了模态间的“转译”瓶颈。
统一表征空间:
- 采用了混合专家(MoE)思想演进而来的Mixture of Tokens机制,能更高效地调度计算资源,处理不同模态和任务。
原生MoT机制:
- 图像和文本作为“复合体”直接输入模型,在同一个前向传播流程中完成从感知到生成的全部计算。
端到端训练:
SenseNova U1的关键信息
对于想要尝鲜的开发者,这里有一些实用信息:
- 商汤科技(SenseTime)。
开发团队:
- 已开源,代码和模型可在GitHub和HuggingFace获取。
开源协议:
- 主要提供了两个版本:8B参数的稠密模型(SenseNova-U1-8B-MoT)和激活参数量约3B的MoE稀疏模型(SenseNova-U1-A3B-MoT)。
模型规格:
- 需要GPU环境,具体显存需求需参考官方文档。此外,使用者需具备基础的模型部署与环境配置能力。
使用要求:
SenseNova U1的核心优势
综合来看,SenseNova U1的竞争力主要体现在以下几个方面:
- “一个模型干所有事”的设计,避免了多模块拼接带来的复杂性和性能损耗,推理延迟优势明显。
架构统一,效率至上:
- 8B的“轻量版”就能在多项任务上达到开源SOTA,并挑战更大规模的闭源模型,性价比很高。
轻量高能:
- 在3D推理、几何理解等空间任务上表现优异。更值得一提的是,其对复杂信息图的排版和文字渲染能力,已接近商用水平。
空间与排版智能突出:
SenseNova U1的同类竞品对比
放在当前多模态开源模型的格局里看,SenseNova U1的定位非常清晰。我们将其与另外两个热门模型做个简单对比:
| 对比维度 | SenseNova U1 | Qwen3VL | Janus |
|---|---|---|---|
开发团队 | 商汤科技 | 阿里云 | DeepSeek |
架构特点 | NEO-Unify原生统一,无VE/VAE | 视觉编码器+LLM拼接 | 解耦视觉编码统一架构 |
模型规模 | 8B / A3B MoE | 8B / 30B-A3B MoE等 | 1.3B / 7B |
理解能力 | OCR/VQA/空间推理/文档解析 | 强视觉理解,OCR/VQA领先 | 多模态理解与推理 |
生成能力 | 图像生成+编辑+信息图+交错生成 | 主要聚焦理解,生成需独立模型 | 图像生成与编辑 |
开源状态 | 开源(Lite版) | 开源 | 开源 |
可以看出,SenseNova U1最大的差异点在于其“原生统一”的架构,使其在保持强大理解能力的同时,具备了原生、高质量的图像生成与编辑能力,这是许多以“理解”见长的模型所不具备的。
SenseNova U1的应用场景
这样的技术特性,能落地到哪些实际场景呢?想象空间很大:
- 自动处理扫描件、PDF,精准提取其中的文字、表格、图表信息,并支持直接问答。
智能文档解析:
- 输入产品描述和风格要求,直接生成高质量的海报、信息图,且排版和字体渲染可控。
营销内容生成:
- 实现“所说即所得”的修图,比如移除照片中多余的物体、转换整体风格等。
精准图像编辑:
- 辅助撰写图文并茂的长文、教程或社交媒体内容,自动配图且图文关联度高。
多模态内容创作:
- 作为机器人的统一“大脑”,从通过摄像头感知环境,到推理决策,再到控制机械臂执行任务,可以在一个模型闭环内完成。
机器人具身智能:
总而言之,SenseNova U1的出现,不仅仅是一个新模型发布,更代表了一种技术范式的探索。它试图证明,通往更强大、更高效AI的道路,或许不在于堆叠更多的模块,而在于回归本质,寻求更深层次的统一。对于开发者和研究者来说,这无疑提供了一个值得深入审视和借鉴的新样本。




