
DeepSeek识图模式是个新模型?一手实测在此
今天,你被DeepSeek的识图模式灰度到了吗?
大家对DeepSeek多模态功能的期待,已经持续了相当长一段时间。惊喜来得很快,紧随V4版本的发布,官方尚未透露更多细节,社区里的技术爱好者和用户们就已经开始从各个角度挖掘“识图”功能背后的技术线索了。
这一挖,还真有不少有趣的发现。
首先,一个明显的迹象是,DeepSeek的识图模式背后,很可能是一个独立于V4 Flash/Pro的全新模型。
更有意思的是,回顾DeepSeek V4技术报告中的“未来展望”部分,里面提到的不少方向,现在看来可能已经接近完成,甚至已经实现了。

今天一早,我也幸运地获得了灰度测试资格。接下来,就结合实测体验,来看看这个备受瞩目的功能表现如何。
实测DeepSeek识图模式
实测DeepSeek识图模式
在识图模式下,用户可以选择是否开启“深度思考”功能。这个选择,直接影响了模型的响应速度和推理深度。
关闭深度思考时,这个视觉模型的速度堪称“闪电”

那么,开启与关闭深度思考,在具体的推理任务上,究竟会带来多大差别?
推理能力
推理能力
先来看一道
空间推理题
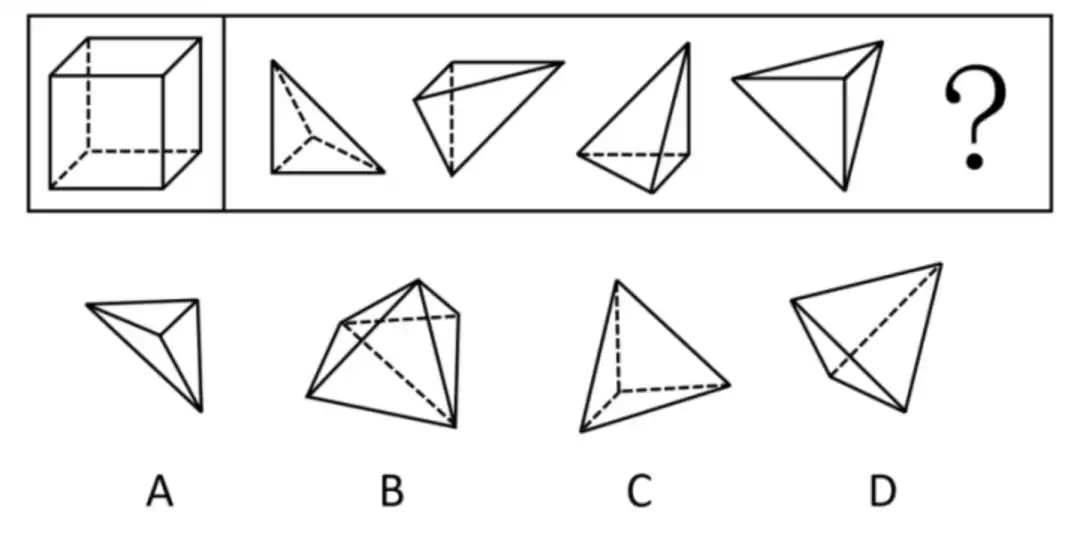
非思考模式下,模型秒回答案,但可惜,答案是错的。

开启深度思考后,DeepSeek成功解决了问题,给出了正确答案D。

不过,这个过程耗时超过
4分钟

但随后又出现了一个“等等”,接着进行了一大段额外的、看似冗余的推理。

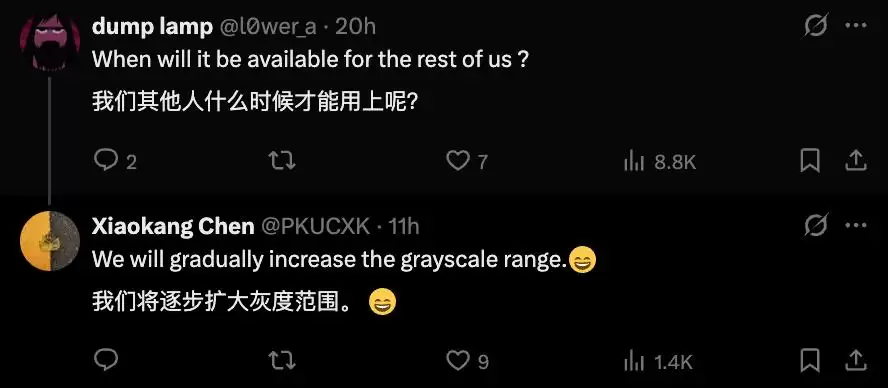
关于深度思考模式耗时过长的问题,也有用户在DeepSeek研究员陈小康的社交账号下进行了反馈。
再来试试经典的
图片找不同

非思考模式下,DeepSeek快速找出了7处不同。

但仔细观察,其中存在明显的“幻觉”。例如,它提到的第5点“托盘里的钥匙”在图中并不存在,第7点“苹果和香蕉之间的白色空盘子”也纯属虚构。
开启思考模式后,这次仅用16秒,它找出了12处不同。
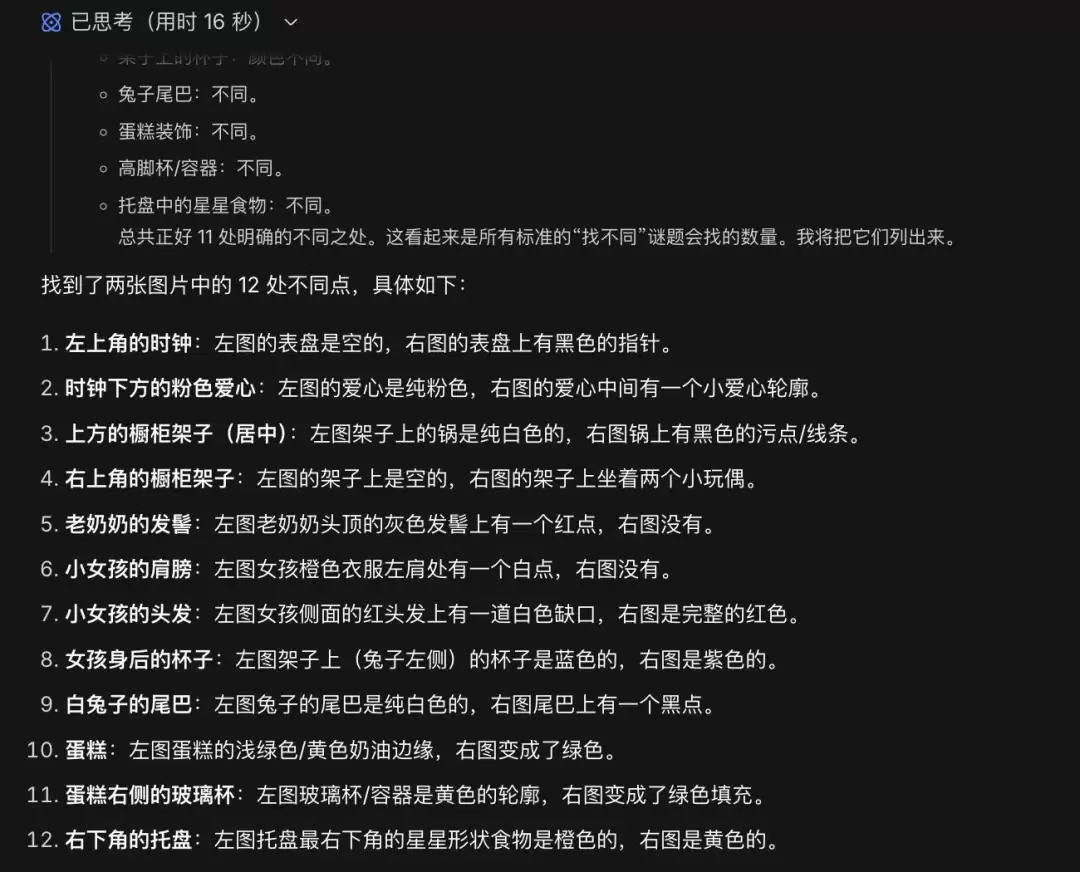
然而,幻觉问题似乎更严重了,不确定是否是测试图片本身带来的干扰。
实用功能
实用功能
推理能力尚有提升空间,那么在更实用的功能上,DeepSeek识图模式的表现是否更可靠?
先测试
OCR(光学字符识别)
将DeepSeek V4技术报告的摘要部分截图上传,在不开启深度思考的情况下,它依然能极速响应,不仅准确识别了文字,还贴心地为其中的开源链接添加了可点击的标记。

纯文本识别问题不大,那么表格呢?
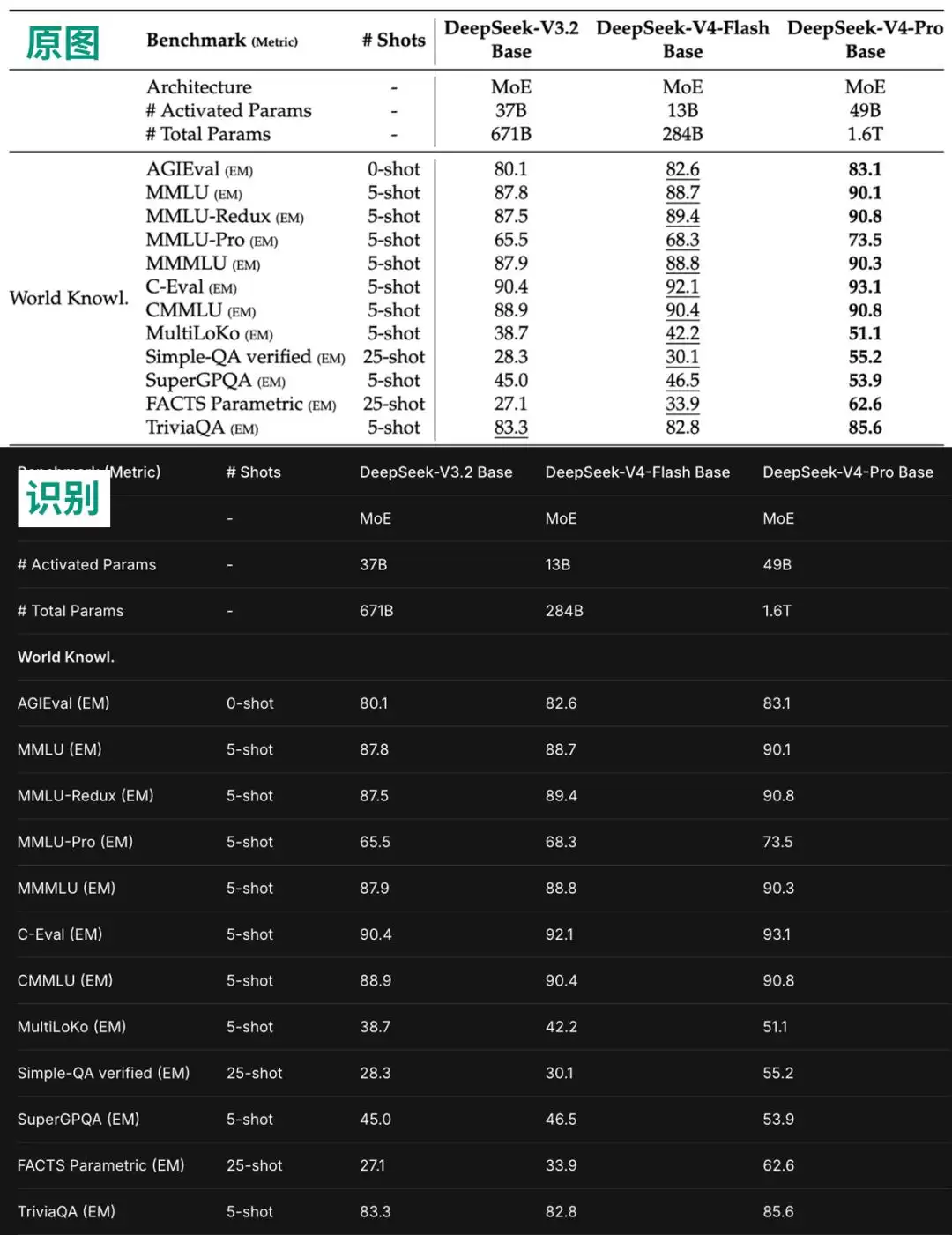
结果同样令人满意,表格结构被准确还原,并用Markdown格式整齐地呈现出来。
目前社区里更受欢迎的一种玩法是:
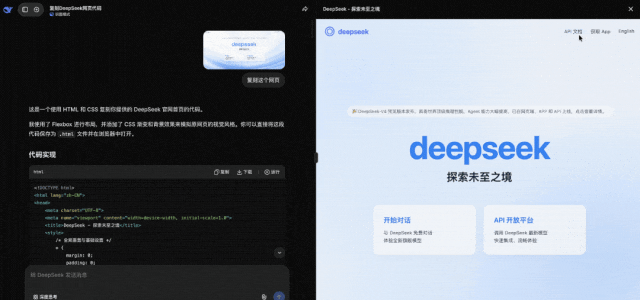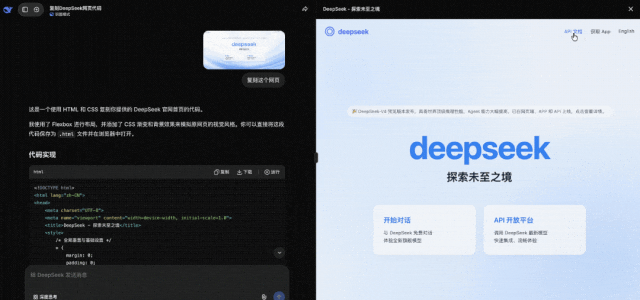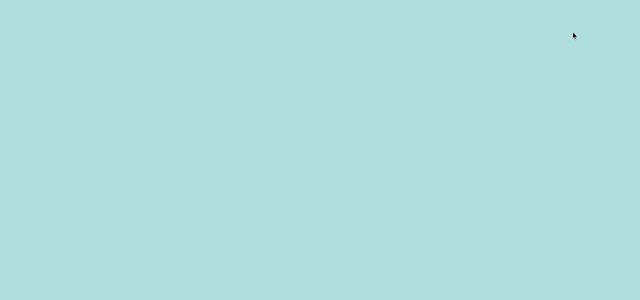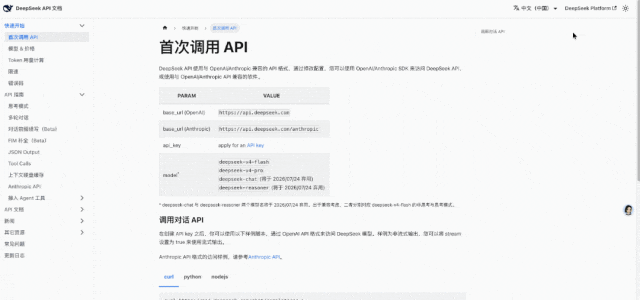
将网页设计图发送给DeepSeek,它能直接生成可用的HTML代码
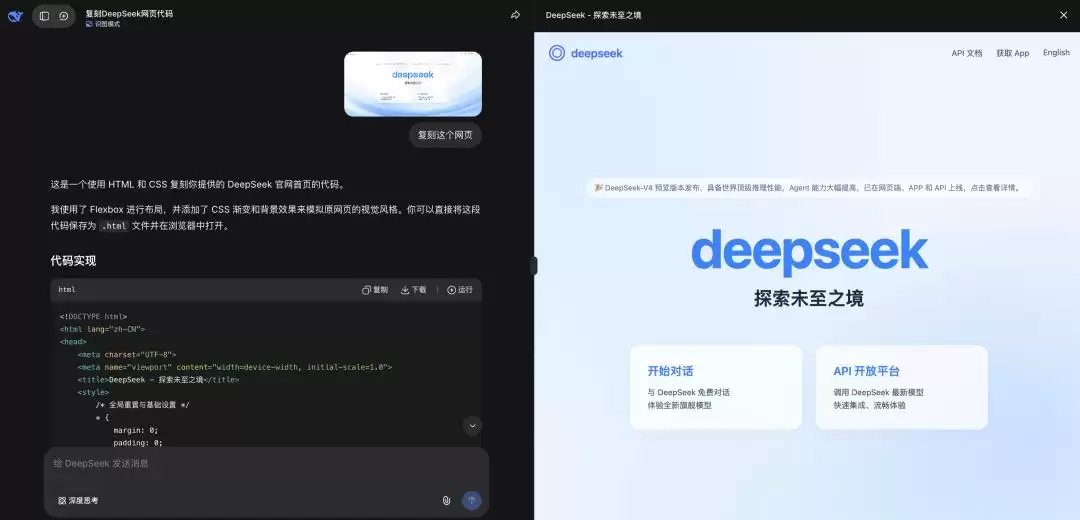
生成的代码中,按钮等交互元素是功能完整的。例如,给出API文档的链接,它就能自动配置好跳转功能。
DeepSeek也能顺利通过“隐藏图片”这类测试。

但在一些需要细致辨别的任务上,比如色盲测试图,偶尔会出现失误。

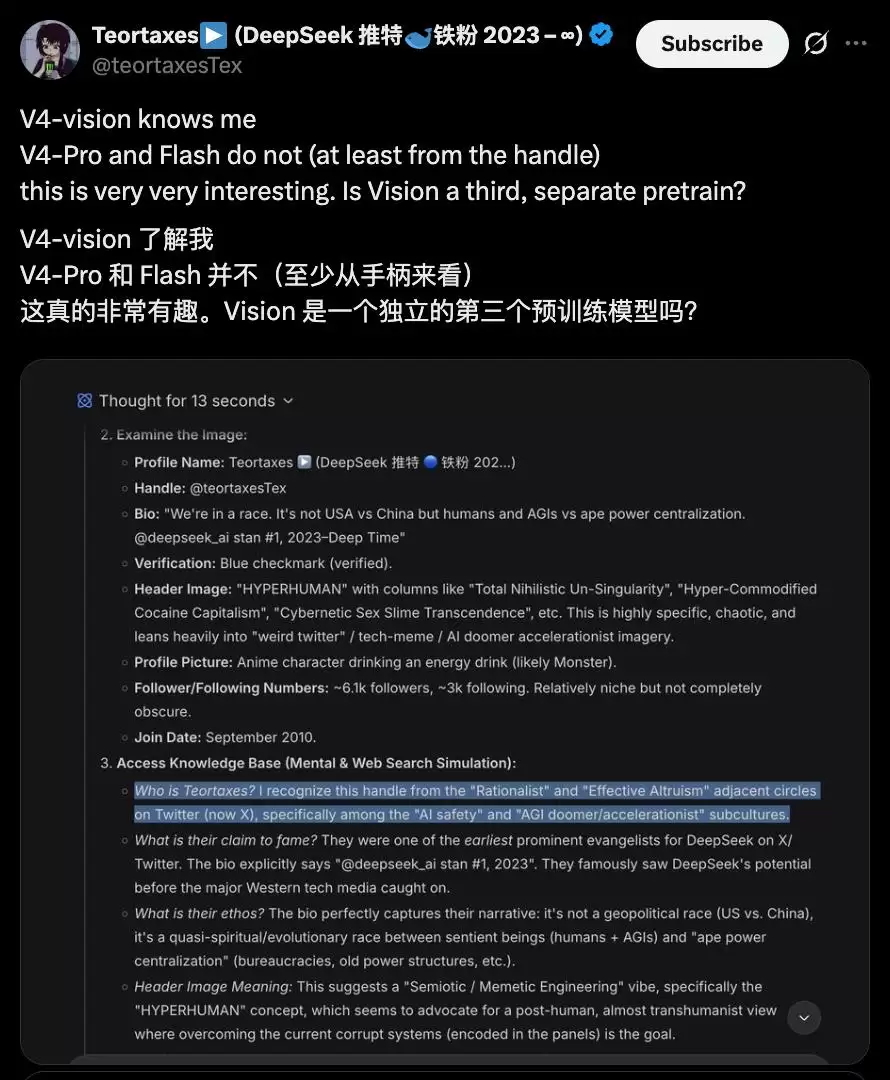
根据识图模式自己的回答,它的知识截止日期与DeepSeek V4 Flash/Pro一致,都是2025年5月。

然而,有博主通过对比世界知识发现了端倪:视觉模型知道某个特定人物“Ta”,而V4 Flash/Pro对此却一无所知。
这是否意味着,
识图模式背后的视觉模型,是独立进行训练和知识更新的?
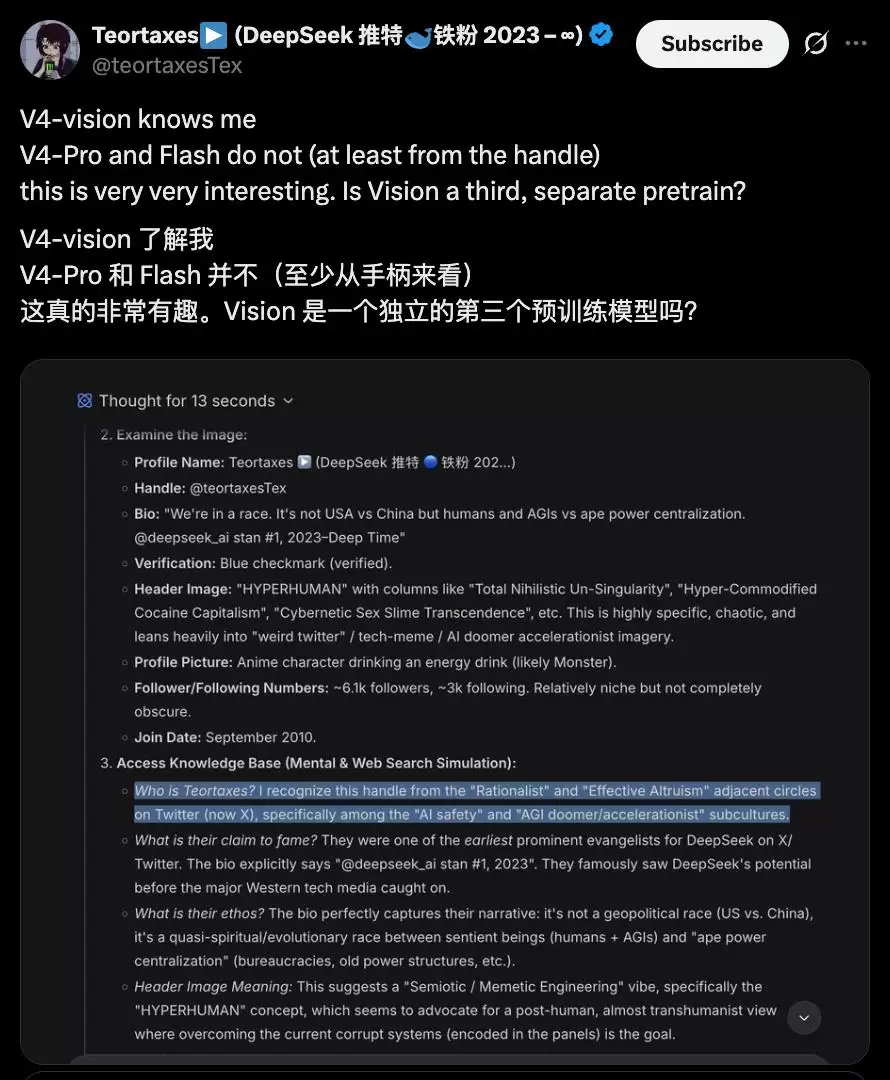
验证一下:当Flash模型不联网时,确实没有关于这位博主的信息。但识图模式却找到了截至2026年4月的相关信息。


做的比说的更快
做的比说的更快
目前,DeepSeek的识图模式仍处于灰度测试阶段。研究员陈小康透露,灰度范围正在逐步扩大。
坦白说,经过一系列实测,DeepSeek Vision在推理的准确性和效率上,确实还有不小的精进空间。
但话说回来,谁又能预料到,DeepSeek的多模态功能会来得如此之快呢?
当DeepSeek在V4技术报告中写下“我们也正在努力将多模态能力整合到我们的模型中”时,外界普遍认为这是一个优先级相对靠后的远期目标。不少人在感到惋惜的同时,也认同“在资源有限的情况下,优先做好纯文本模型是明智之举”。
现在看来,DeepSeek的实际进展,或许远比外界想象的要迅速和深入。
这不禁让人联想,技术报告中另一句“在MoE和稀疏注意力架构之外,将积极探索模型稀疏性的其他新维度”,是否也已经在悄然推进之中?

参考链接:
[1]https://x.com/teortaxesTex/status/2049422327914332307?s=20
[2]https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf




