
DeepSeek多模态技术范式公布,以视觉原语思考
五一假期前夕,AI圈又迎来一个重磅消息。DeepSeek在技术开源的道路上,再次迈出了关键一步。
昨天,DeepSeek创始人陈小康在社交平台上的一个动态,已经让业界嗅到了多模态新进展的气息。随后,部分用户率先在网页端和App上体验到了这项能力。而就在刚刚,DeepSeek在GitHub上正式开源了其多模态模型,并同步发布了详尽的技术报告。
这份新鲜出炉的报告,揭示了一种堪称开创性的多模态推理新范式。

下面,我们就来深入解读这份由DeepSeek、北京大学和清华大学联合发布的技术报告,看看他们究竟如何攻克了多模态推理中的一个核心难题。
背景:“看清”和“想清”是两件事
背景:“看清”和“想清”是两件事
这篇题为《Thinking with Visual Primitives》(以视觉原语思考)的论文,直指当前多模态大模型的一个普遍软肋:模型或许能“看见”图像,却未必能“想清楚”图像中的关系。
举个例子,给出一张人群密集的照片,询问“图中有多少人”,即便是顶尖模型也可能数错。向模型展示一张复杂的电路图,问“左边的红色电容在右边电感的左侧还是右侧”,得到的回答往往含糊其辞甚至自相矛盾。问题的根源,很多时候并非模型“看不清”,而是在“思考”过程中,模型无法精准地锁定和追踪它正在讨论的视觉对象。
DeepSeek将这个问题定义为“指代鸿沟”(Reference Gap),并为此提供了一套完整的解决方案。
要理解这个鸿沟,可以想象你正通过电话向一位看不到你屏幕的朋友描述复杂的棋盘布局。你说“左边那个棋子要吃掉中间偏右的那个棋子”,但对方完全无法对应具体是哪两颗棋子。这正是现有大模型在多步推理中的困境:它们用自然语言构建“思维链”,但自然语言本身具有模糊性。“左边那个大的”、“靠近中央的红色物体”这类描述,在信息密集的场景中根本无法精确定位。模型的注意力在推理链条中容易“漂移”,导致越推越乱,最终结论出错。
此前学术界的努力主要集中在提升模型的“视力”上,例如采用高分辨率切分、动态分块等技术,以弥合“感知鸿沟”。然而,这篇论文明确指出,强大的感知能力并不能自动转化为精确的指代能力。“看见”和“能说清楚指的是哪个”,本质上是两件不同维度的事。
架构:站在V4-Flash的肩膀上
架构:站在V4-Flash的肩膀上
这项工作以DeepSeek最新发布的V4-Flash模型作为语言主干。这是一个总参数量达284B、推理时激活13B参数的混合专家模型。视觉编码部分则采用了DeepSeek自研的视觉Transformer,支持任意分辨率的图像输入。
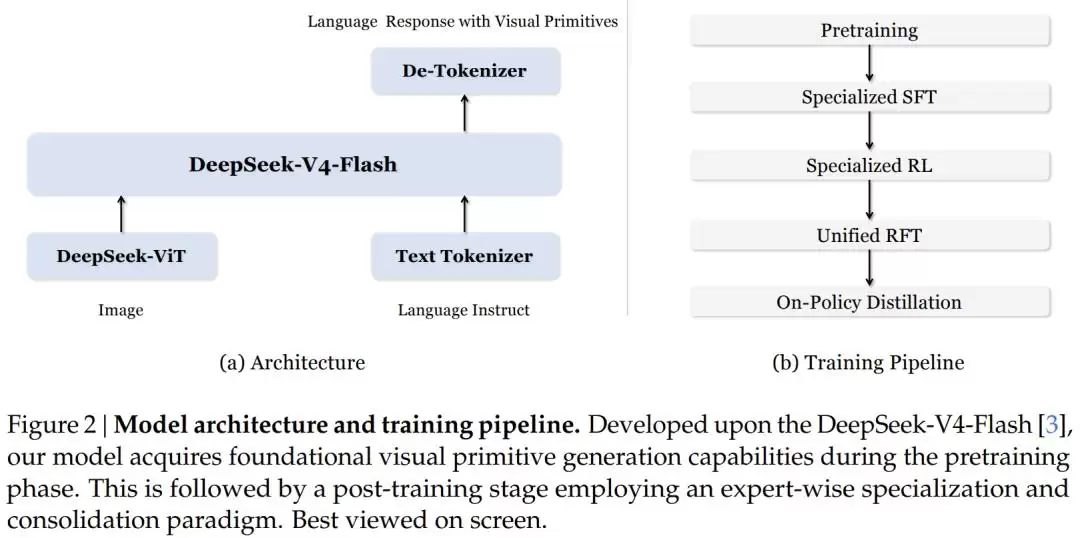
值得注意的是,团队的核心贡献在于提出了一套全新的“训练哲学”:如何用极少的视觉标记,教会模型在推理过程中实现对视觉对象的精确指代。
核心创新一:将坐标转化为“思维单元”
核心创新一:将坐标转化为“思维单元”
这项研究最核心的思路,可以用一句话概括:将点坐标和边界框(Bounding Box)提升为推理的基本单元,让它们像文字一样,自然地穿插在模型的思维链中。
传统做法中,边界框通常是推理结束后的输出结果。模型先完成思考,再告诉你“目标位于图片左上角坐标[100,200,300,400]”。这更像是一种事后标注,而非思考工具。
DeepSeek的做法截然不同。模型在推理的每一步,只要提及一个视觉对象,就会同步输出其坐标信息。例如,它的思考过程可能是这样的:
“扫描图片寻找熊,找到一只<|ref|>熊<|/ref|><|box|>[[452,23,804,411]]<|/box|>,它正在爬树,不在地面上,排除。再往左下看,找到另一只<|ref|>熊<|/ref|><|box|>[[50,447,647,771]]<|/box|>,站在岩石边缘,符合条件。”
这类似于人类在清点物品时会用手指逐一指点。在这里,坐标不再是最终的答案,而是推理过程中用于消除歧义的“思维锚点”。模型的逻辑链条被牢牢地固定在图像的物理坐标上,从而避免了注意力漂移。
这套机制包含两种“视觉原语”:边界框(<|box|>)用于需要精确定位和尺寸信息的对象;点坐标(<|point|>)则用于更抽象的空间指代,比如描绘迷宫探索的轨迹或追踪曲线的路径。
核心创新二:高达7056倍的视觉压缩
核心创新二:高达7056倍的视觉压缩
另一项令人印象深刻的技术创新,来自架构层面的极致压缩。
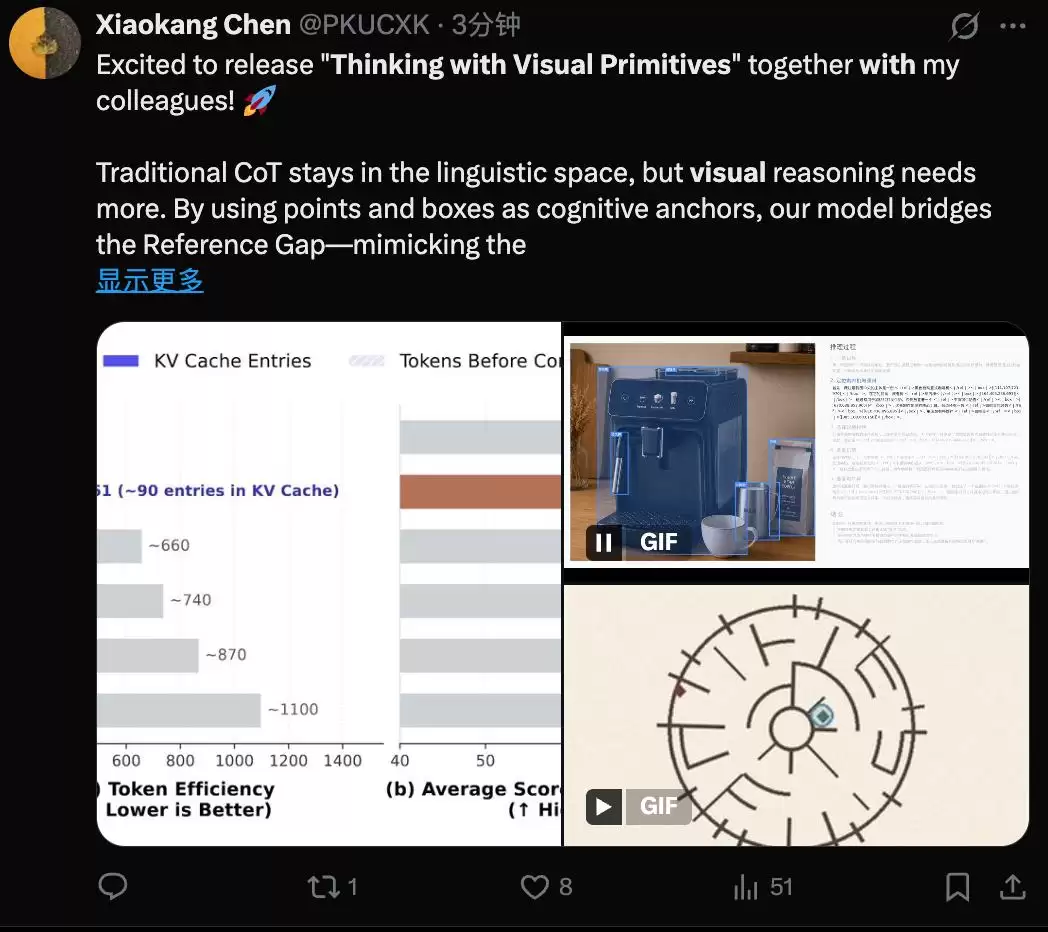
对于一张756×756像素的图片,传统方案需要将大量视觉标记输入语言模型。而DeepSeek的流程是:图像先经过视觉Transformer处理,生成2916个图像块标记;随后经过3×3的空间压缩,合并为324个标记输入语言模型;最后,依托V4-Flash内置的“压缩稀疏注意力”机制,将键值缓存进一步压缩4倍,最终仅保留81个视觉键值条目。
从原始像素到最终的缓存条目,整体压缩比达到了惊人的7056倍。
这意味着,处理一张800×800的图片,该模型仅需约90个键值缓存条目。相比之下,Claude Sonnet 4.6需要约870个,Gemini-3-Flash则需要约1100个。论文的核心论点在于:精确的空间指代能力,可以在相当程度上弥补视觉标记数量的不足。模型未必需要“看得更多”,但必须“指得更准”。
核心创新三:精心设计的冷启动数据
核心创新三:精心设计的冷启动数据
技术创新的第三个维度,体现在训练数据的构建策略上。
团队首先爬取了近10万个与目标检测相关的数据集,经过语义和几何质量两轮严格筛选,最终保留了约3.17万个高质量数据源,生成了超过4000万条训练样本。
在“视觉原语思考”专项数据上,团队设计了四类核心任务:
第一类是计数任务

第二类是空间推理与视觉问答

第三类是迷宫导航
第四类是路径追踪
训练流程:“先分家,再合体”
训练流程:“先分家,再合体”
在后训练阶段,团队采用了“先专家化,后统一”的策略。
第一步,分别使用边界框数据和点坐标数据训练两个专家模型,避免两种模态在数据量不足时相互干扰。
第二步,对两个专家模型分别进行强化学习,采用GRPO算法。奖励函数设计得非常精细:格式奖励(输出格式是否正确)、质量奖励(由大模型评判思考内容与答案是否一致)、精度奖励(任务特定指标)三路并行。例如,计数任务采用平滑的指数衰减奖励而非简单的对错二分;迷宫任务的奖励则分解为因果探索进度、探索完整性、穿墙惩罚、路径有效性和答案正确性五个子项,旨在为模型提供密集且信息丰富的学习信号。
第三步,利用两个专家模型产生的轨迹数据进行统一的强化微调,并从预训练模型重新初始化,得到统一的模型。
第四步,通过“在线策略蒸馏”技术,弥合统一模型与专家模型之间的性能差距——让学生模型自己生成推理轨迹,然后最小化其输出分布与专家分布之间的KL散度。
实验结果:在“最难的那类题”上实现超越
实验结果:在“最难的那类题”上实现超越
论文在11个基准测试上进行了全面评测,对比对象包括Gemini-3-Flash、GPT-5.4、Claude Sonnet 4.6、Gemma4-31B、Qwen3-VL-235B等主流模型。
结果概要如下:
在计数任务上,该模型在Pixmo-Count(精确匹配)上得分89.2%,超越Gemini-3-Flash的88.2%,并大幅领先GPT-5.4的76.6%和Claude Sonnet 4.6的68.7%。在细粒度计数任务上,以88.7%的得分超过Qwen3-VL的87.2%,位列第一。
在多个空间推理基准上,整体表现与头部模型持平或略有超越,在MIHBench和SpatialMQA上均排名第一。
最具代表性的差距出现在拓扑推理任务上。在迷宫导航任务中,该模型得分66.9%,而GPT-5.4为50.6%,Gemini-3-Flash为49.4%,Claude Sonnet 4.6为48.9%——所有前沿模型都仅能答对一半左右,而该模型将准确率提升了约17个百分点。在路径追踪任务中,该模型56.7%的得分也显著高于GPT-5.4的46.5%和Gemini-3-Flash的41.4%。
论文也诚实地指出:“所有前沿模型在拓扑推理任务上均表现欠佳,说明多模态大模型的推理能力仍有相当大的提升空间。”
下面展示了几个定性分析的示例:
局限与未来方向
局限与未来方向
论文并未回避当前模型的几个已知局限性。
首先,当前模型需要明确的“触发词”才会启用视觉原语机制——它尚不能自主判断何时该使用这种“用手指点”的思考方式。
其次,受输入分辨率限制,在极其细粒度的视觉场景中,视觉原语的位置精度偶尔会不足。团队认为,与现有高分辨率感知方案结合是自然的下一步。
最后,利用点坐标解决复杂拓扑推理问题,其跨场景的泛化能力目前仍有提升空间。
结语:一种新的“思考姿势”
结语:一种新的“思考姿势”
这篇论文的价值,远不止于在几个评测榜单上取得领先。
它提出的问题——“推理过程中语言指代的歧义性是多模态模型的根本瓶颈之一”——在此前并非学界的主流叙事。主流努力方向往往是追求更大的模型规模、更高的图像分辨率、更多的训练数据。
而这项研究开辟了另一条路径:并非让模型“看更多”,而是让模型“指更准”。用坐标替代模糊的语言描述,用空间锚点来稳定逻辑链条。从这个角度看,《Thinking with Visual Primitives》更像是在为多模态推理增添一种基础性的“思考姿势”——一种人类在处理复杂视觉任务时不假思索就会采用,但AI却长期缺失的姿势:用手指点着想。




