
低成本复刻Fable5的路子找到了:OrcaRouter多模型组队,性能反超
这年头,AI圈最不缺的就是“得不到的白月光”。
在过去的一段时间里,很多人一边对着
Claude Fable 5
怎么掀的?靠一手精妙的“拼图游戏”。
AI网关
OrcaRouter
Routing DSL
一个典型的案例:Opus 4.8打不过Fable 5,GPT-5.5也单挑不过,但这两个模型拼在一起,结果就反超了。哪怕不混编,同一个Opus 4.8自己跟自己组队,综合得分也能从58.5%拉到约
65.5%
成本却低了一大截
来看具体数据。
反直觉的结果:组合 > 任何单兵
拿一组测试数据来说明(注:以下为示意性数据,用于说明趋势,非官方跑分)。在100道任务中,评分了
93道
结果很清楚:组合面板(多模型并行+仲裁)的得分,普遍高于它的每一个成员模型。
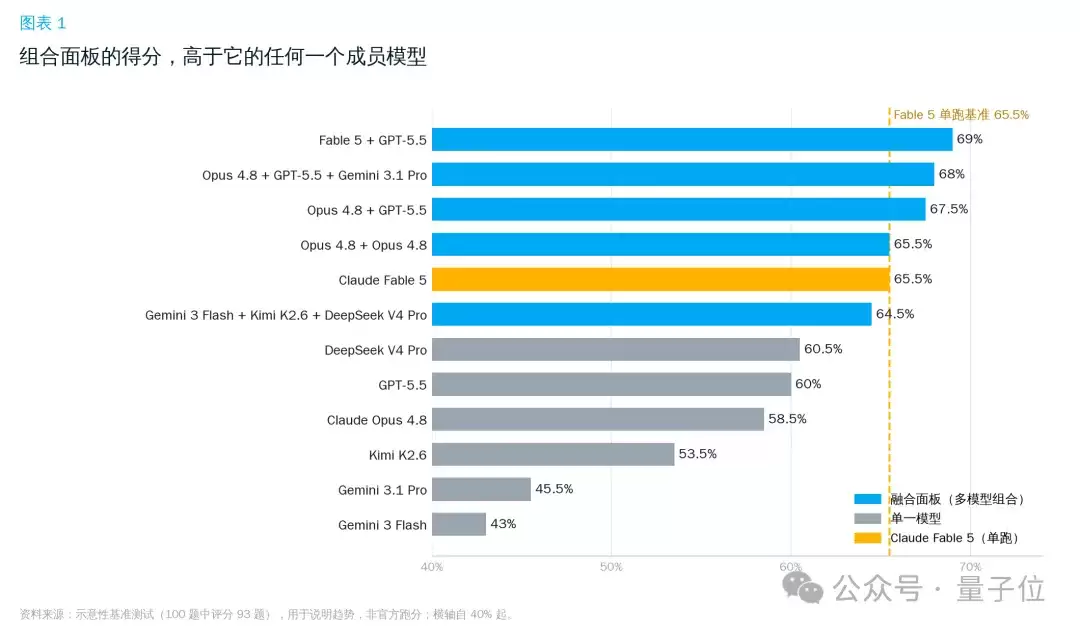
这里有几个关键发现:
- 任意一个“组合面板”,都打过了它自己的每一个成员。比如Opus 4.8 + GPT-5.5(约67.5%)同时高于Opus单跑(约58.5%)和GPT-5.5单跑(约60%),拉开了7~9个点;
- 多个组合追平、甚至超过了Fable 5单跑(约65.5%);
- 连“自我组合”(Opus×2,约65.5%)都能追平Fable 5;一组便宜模型(Gemini 3 Flash+Kimi K2.6+DeepSeek V4 Pro,约64.5%)也几乎贴脸——。
成本却低了一大截
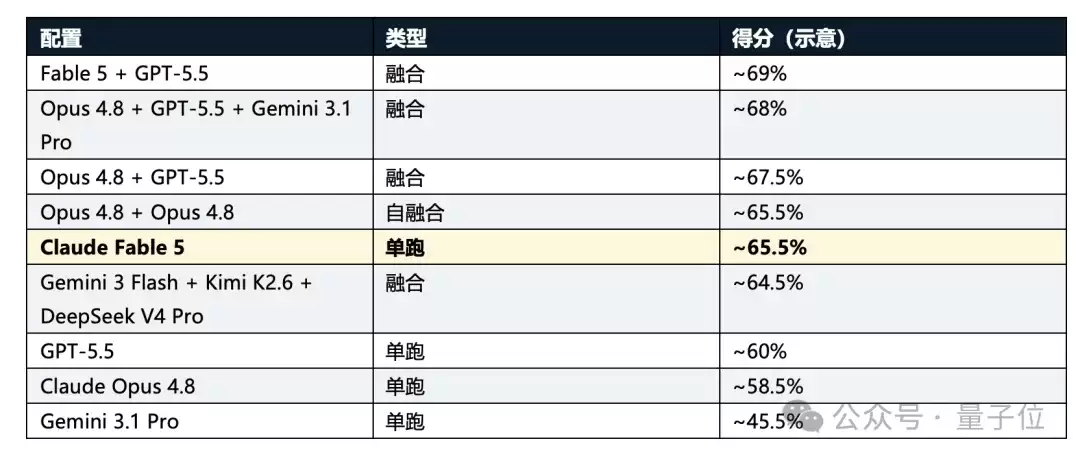
再把DSL按难度智能分流跑成完整端点,差距就更直观了(同为示意数据)。
很明显,赢的并不是“更强的模型”,而是
“更聪明的编排方式”
为什么“人多力量大”对模型也适用
这个道理其实很简单,就像让三个工程师同时解题,再挑出最好的答案一样。
不同模型的知识盲区和犯错方式各不相同:各自独立作答时,错误是分散且不重叠的;再用“裁判”或“投票”机制把对的挑出来,整体正确率自然就被拉了上去。所以,模型间的分歧其实是
信号
从这些分歧中挑出最优解
怎么做到的:用最简单的配置,解最复杂的调度
OrcaRouter把这套编排逻辑的“钥匙”交给了用户自己来写。
规则用YAML编写,条件使用Google的CEL表达式(安全沙箱、只读、微秒级求值),自上而下匹配,第一条命中即生效。整条请求的处理路径如下:
按难度路由的配置大概长这样:
rules:
id: hard
when: difficulty > 0.8 # 难题 → 上顶配
use: { model: "anthropic/claude-opus-4-8", reasoning_effort: "high" }
id: easy
when: difficulty < 0.3 # 简单请求 → 走便宜模型
use: { model: "google/gemini-3-flash" }
default:
delegate: balanced
而真正实现“满血复活”的关键一招,是
parallel(并行扇出)+ arbiter(仲裁)
use:
parallel: # 2~5个模型并行作答
- { model: "anthropic/claude-opus-4-8" }
- { model: "openai/gpt-5.5" }
- { model: "google/gemini-3.1-pro" }
arbiter:
strategy: best_of_n # 让一个"裁判模型"挑最优
model: "anthropic/claude-sonnet-4-6"
目前支持四种仲裁策略,对应四种不同的“定胜负”方式:

担心组合也可能翻车?可以再加一层
置信度级联
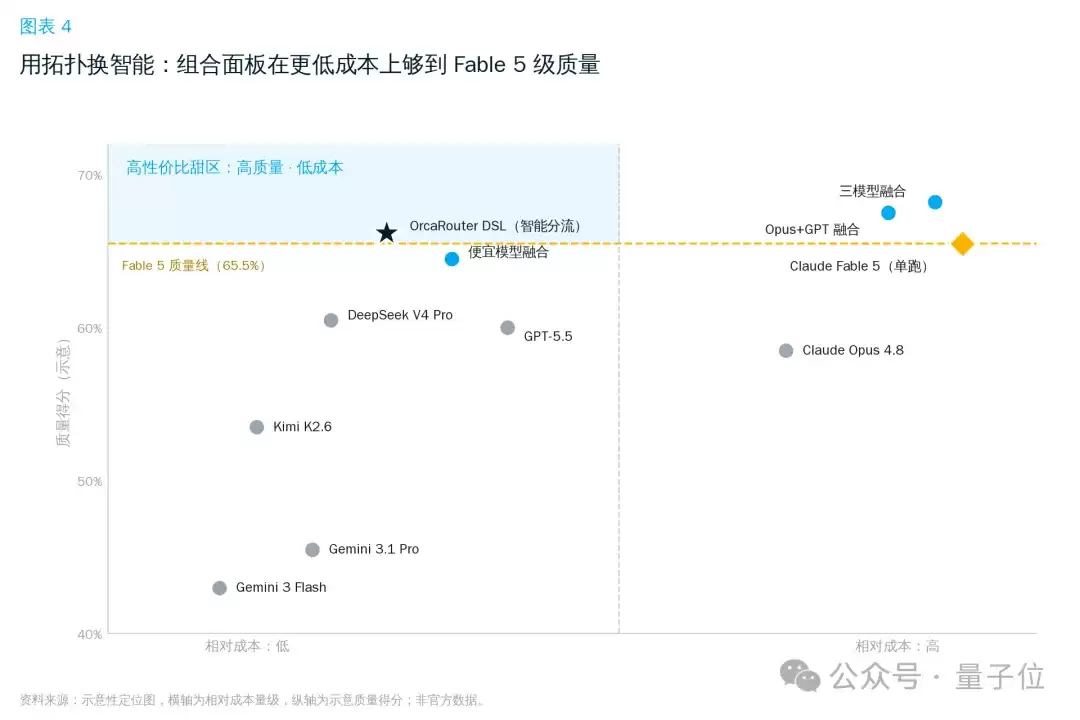
更省、更稳:用拓扑换智能
并行扇出意味着“每条腿都计费”,但账要这么算:你只在难的那一小撮请求上才扇出,简单请求照样走便宜模型。而一组便宜模型拼出的面板就能逼近Fable 5——
用拓扑结构买智能,而不是用更高的单价买智能
上手极简
入口在控制台:routing → create router → routing strategy → DSL。
配套自带lint校验、dry-run试跑、影子模式(只评估不生效,先看A/B差异和成本变化)、灰度放量(0~100%滑杆)和回滚审计。改路由这种高危操作,被包了一层安全网,可以零风险跑起来再放量。
需要说明的一点是:按难度/任务的智能路由现已上线;而“多模型并行扇出+仲裁”的运行时目前处于灰度/预览阶段(计费链路逐步验证中)。可以先写好规则、用影子模式观察,等开放后一键生效。
结语
当整个圈子都在为下一个未知数倾注赌注时,一种更具确定性的工程范式正在悄然成型。协作大于单兵,网络优于孤岛。
几个现成的模型组合起来就能赢最强单体——胜负手已经不只是“你调用了谁”,
“你怎么编排”
“怎么用”这件事,也许该和“用哪个”放在同一个优先级了
(注:本文图表均为示意性数据,仅用于说明趋势,非官方跑分;多模型融合运行时目前处于灰度/预览阶段。)




