
Fable 5被禁3天后Anthropic认怂,连夜急派员工赴华盛顿谈判:GPT 5.5有同款漏洞
来源:互联网
时间:2026-06-16 14:34:29
作为 Anthropic 有史以来向公众发布的最强 AI 模型,Fable 5 从上线到“下线”,仅仅撑了三天。这三天里,它登顶聊天机器人竞技场,在编程基准测试上以两位数的优势碾压 OpenAI 的 GPT 5.5,还头一回让付费订阅用户尝到了 Mythos 级别推理能力的甜头。然后,6 月 12 日,特朗普政府的一纸指令,直接把它从架子上撤了下来。
Anthropic 的态度很明确:这笔账算得不对。他们公开表示,政府引用的那个所谓漏洞,根本不足以作为整个模型下架的理由。眼下,Fable 5 能不能回归,全看 Anthropic 跟政府就出口管制分类的谈判结果了。
## 最新进展:Anthropic 派遣员工谈判中
最新消息是,在外媒报道中,有知情人士透露,在白宫的指令实质上让自家旗舰产品“断线”之后,Anthropic 的高级成员正在华盛顿特区跟特朗普政府努力协商。报道还提到,特朗普政府对 Anthropic 处理“越狱”投诉的方式相当不满,指责他们“沟通不够严肃”。
不过,知情人士也说了,自上周五白宫首次主动联系以来,Anthropic 的技术人员已经跟白宫官员开了几轮线上会议。双方的消息人士都表示,还挺想尽快把这事儿解决的。
至于模型为什么被下架,现在也是众说纷纭。有消息指出,亚马逊似乎是向白宫指出 Fable 5 和 Mythos 5 存在潜在安全漏洞的公司之一。报道称,上周四晚到周五上午,亚马逊和其他五家公司通知白宫,说已经成功演示了那种令人担忧的越狱操作,亚马逊的 CEO 安迪·贾西也亲自跟特朗普政府成员联络了。
另一边,根据 Semafor 援引匿名消息源的报道,白宫还担心“一个与中国有关的组织”已经拿到了一个 Mythos 级别模型的访问权限。Semafor 指出,Anthropic 本身是不允许来自中国的用户访问其 AI 模型的。
面对这些消息,亚马逊的发言人回应说:“政府就潜在安全风险向我们咨询,这并不罕见。我们不会透露这类讨论的具体细节。”而 Anthropic 的发言人则表示,在白宫围绕越狱和出口管制问题的对话中,压根儿没提中国访问 Mythos 这茬儿。这家 AI 公司也确实禁止中国境内用户访问其产品。
## 白宫公开态度:解决安全问题、 Fable 重新向大众发布
需要说明一点,Fable 5 和 Mythos 5 都是所谓的“Mythos 级”模型,基于与 Claude Mythos Preview 相同的核心技术构建,属于向付费 Claude 账户开放的公开产品。Fable 5 是 6 月 9 日发布的,也是 Anthropic 第一款面向公众的 Mythos 级模型。它提供了一百万 token 的上下文窗口和 128000 个输出 token。Anthropic 原本打算向 Pro、Max、Team 和 Enterprise 订阅者免费开放到 6 月 22 日,结果政府一纸令下,这个促销窗口三天就关了。
说到 Mythos Preview,那是 Anthropic 在 4 月发布的模型。当时公司声称它过于强大,极易被滥用,可能危及全球网络安全,所以采取了极其严格的发布管控,仅供少数几家特定公司使用,不做公开发布。而被下架的 Fable 5 和 Mythos 5,本来应该是 Mythos Preview 的“驯化版”——通过大量显性的安全护栏,让它变得安全可控。
然后就是上周五下午,Anthropic 接到了白宫的电话,被告知 Fable 5 和 Mythos 5 继续在线构成了某种“国家安全威胁”,要求他们在 90 分钟内下线。之后具体发生了什么还不清楚,但不久后,一封出口管制令送到了 Anthropic:要求公司不得允许非美国公民使用其最顶尖的先进 AI 模型产品。
这意味着,连 Anthropic 自己的外籍员工都被禁止使用这些模型。特朗普政府援引一个越狱漏洞作为撤下 Fable 5 和整个 Mythos 5 模型系列的理由。几小时后,这些模型就彻底下线了。
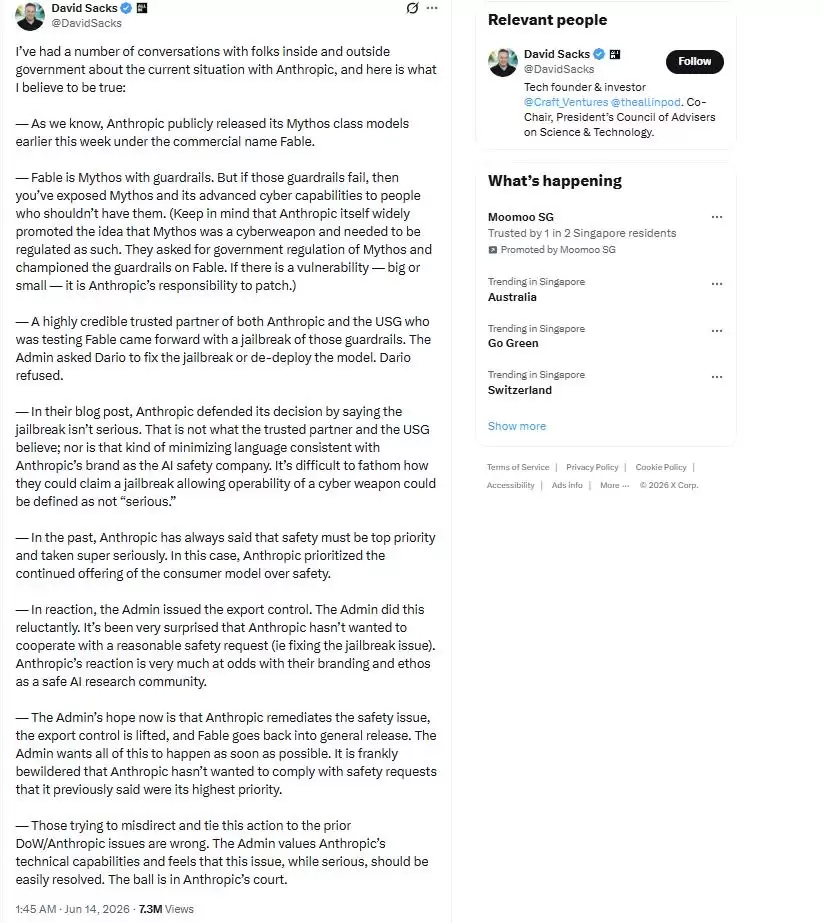
6 月 14 日,特朗普的顾问 Da vid Sacks 在 X 平台上发帖,透露了白宫做出出口管制决定的前因后果。据 Sacks 指控,一个同时与 Anthropic 和白宫合作、且高度可信的合作伙伴在测试 Fable 时,发现了针对它的越狱方法。当政府把这事儿告知 Anthropic 时,公司联合创始人兼 CEO Dario Amodei 表示,这个越狱算不上严重风险,并拒绝修复。
帖子里继续写道:“过去,Anthropic 一直强调安全是重中之重,对待安全也非常认真。但这次,他们把消费模型的持续提供放在了安全之上。白宫现在的希望是:Anthropic 解决安全问题,出口管制令解除,Fable 重新面向大众发布。”
这也不是 Anthropic 头一回跟白宫起冲突了。他们之前游说反对特朗普政府抢先制定州级 AI 监管法规,还因为公司模型在自主武器上的使用问题陷入僵局,正在起诉五角大楼。不过 Sacks 表示,这些先前的冲突并没有影响政府对 Mythos 的决定。“那些试图转移话题、把这件事跟之前的事扯上关系的人,搞错了。白宫重视 Anthropic 的技术能力,也认为这个问题虽然严重,但应该可以轻松解决。”
 ## 被“全面超越”的 GPT 5.5,也有相同漏洞?
对于白宫调查结果有多严重,Anthropic 之前已经明确提出了异议,说识别的漏洞很微小、是公开已知的,而且 GPT 5.5 根本不需要任何越狱技术就能达到同样的效果。
“我们审查了那个特定技术的演示,它被用来识别少量此前已知的、微小的漏洞。这些漏洞看起来都相对简单,我们发现其他公开可用的模型也能在没有越狱的情况下发现它们。”Anthropic 在 6 月 12 日的声明里这么说。他们表示,公司为 Fable 建立了强大的安全护栏,大大降低了它被用于网络安全相关任务(以及其他用途)的可能性,以至于很多用户都抱怨它护栏太宽了。
Anthropic 还指出,特朗普政府只向他们提供了口头证据,证明存在一种潜在的、很窄的非通用越狱,本质上就是要求模型读取特定的代码库并修复任何软件缺陷。他们审查了一份可能是政府指令依据的报告,并且证实报告里展示的能力水平,在其他模型(包括 OpenAI 的 GPT-5.5)里也广泛存在,而且每天都被维护系统安全的安全防护人员正常使用。
这场风波的直接影响之一,就是那些原本在评估 Fable 5、准备用于生产环境的开发者,现在只能退而求其次,用 GPT 5.5 或 Anthropic 早期的 Opus 模型。
要知道,Fable 5 和 GPT 5.5 之间的基准差距可不小。在衡量模型解决开源代码库中真实软件工程问题的 SWE-Bench Pro 上,Fable 5 得分 80.3%,而 GPT 5.5 只有 58.6%,差了 22 个百分点。在同一个基准的精调子集 SWE-Bench Verified 上,Fable 5 更是达到了 95.0%。对编码密集型的工作流来说,这种降级是实实在在的。SWE-Bench Pro 上 22 个百分点的差距,意味着一个能解决五分之四真实软件问题的模型,与一个只能处理大约五分之三问题的模型之间的鸿沟。
编程基准测试也显示了类似的差距。Fable 5 在 Code Arena 上领先 98 个 Elo 分,得分 1665,而 GPT 5.5 是 1501。在专门测试最难编程任务的 FrontierCode Diamond 基准上,Fable 5 得分 29.3%,GPT 5.5 仅为 5.7%。在更广泛的聊天机器人竞技场排行榜上,Fable 5 位列第一,GPT 5.5 排名第四。
当然,GPT 5.5 也有自己的优势。在评估交互式终端编码任务(而非代码库级别的问题解决)的 Terminal-Bench 2.0 上,GPT 5.5 得分 82.7%,而 Fable 5 大约是 88.0%。这个差距相对小一些,而且这个基准测试的技能不同:更偏向实时执行命令和调试,而不是阅读和修补大型代码库。另外,GPT 5.5 的定价是每百万输入 token 5 美元、每百万输出 token 30 美元,是 Fable 5 定价(分别是 10 美元和 50 美元)的一半。对于运行高容量应用、且性能差异不像成本那么关键的开发者来说,即便两个模型都能用,GPT 5.5 也是更实际的选择。
### **参考链接:**
https://thenextweb.com/news/anthropic-fable-5-vs-openai-gpt-5-5-benchmark-comparison
https://www.semafor.com/article/06/13/2026/white-house-move-to-limit-anthropic-linked-to-concerns-about-chinese-access-to-mythos
## 被“全面超越”的 GPT 5.5,也有相同漏洞?
对于白宫调查结果有多严重,Anthropic 之前已经明确提出了异议,说识别的漏洞很微小、是公开已知的,而且 GPT 5.5 根本不需要任何越狱技术就能达到同样的效果。
“我们审查了那个特定技术的演示,它被用来识别少量此前已知的、微小的漏洞。这些漏洞看起来都相对简单,我们发现其他公开可用的模型也能在没有越狱的情况下发现它们。”Anthropic 在 6 月 12 日的声明里这么说。他们表示,公司为 Fable 建立了强大的安全护栏,大大降低了它被用于网络安全相关任务(以及其他用途)的可能性,以至于很多用户都抱怨它护栏太宽了。
Anthropic 还指出,特朗普政府只向他们提供了口头证据,证明存在一种潜在的、很窄的非通用越狱,本质上就是要求模型读取特定的代码库并修复任何软件缺陷。他们审查了一份可能是政府指令依据的报告,并且证实报告里展示的能力水平,在其他模型(包括 OpenAI 的 GPT-5.5)里也广泛存在,而且每天都被维护系统安全的安全防护人员正常使用。
这场风波的直接影响之一,就是那些原本在评估 Fable 5、准备用于生产环境的开发者,现在只能退而求其次,用 GPT 5.5 或 Anthropic 早期的 Opus 模型。
要知道,Fable 5 和 GPT 5.5 之间的基准差距可不小。在衡量模型解决开源代码库中真实软件工程问题的 SWE-Bench Pro 上,Fable 5 得分 80.3%,而 GPT 5.5 只有 58.6%,差了 22 个百分点。在同一个基准的精调子集 SWE-Bench Verified 上,Fable 5 更是达到了 95.0%。对编码密集型的工作流来说,这种降级是实实在在的。SWE-Bench Pro 上 22 个百分点的差距,意味着一个能解决五分之四真实软件问题的模型,与一个只能处理大约五分之三问题的模型之间的鸿沟。
编程基准测试也显示了类似的差距。Fable 5 在 Code Arena 上领先 98 个 Elo 分,得分 1665,而 GPT 5.5 是 1501。在专门测试最难编程任务的 FrontierCode Diamond 基准上,Fable 5 得分 29.3%,GPT 5.5 仅为 5.7%。在更广泛的聊天机器人竞技场排行榜上,Fable 5 位列第一,GPT 5.5 排名第四。
当然,GPT 5.5 也有自己的优势。在评估交互式终端编码任务(而非代码库级别的问题解决)的 Terminal-Bench 2.0 上,GPT 5.5 得分 82.7%,而 Fable 5 大约是 88.0%。这个差距相对小一些,而且这个基准测试的技能不同:更偏向实时执行命令和调试,而不是阅读和修补大型代码库。另外,GPT 5.5 的定价是每百万输入 token 5 美元、每百万输出 token 30 美元,是 Fable 5 定价(分别是 10 美元和 50 美元)的一半。对于运行高容量应用、且性能差异不像成本那么关键的开发者来说,即便两个模型都能用,GPT 5.5 也是更实际的选择。
### **参考链接:**
https://thenextweb.com/news/anthropic-fable-5-vs-openai-gpt-5-5-benchmark-comparison
https://www.semafor.com/article/06/13/2026/white-house-move-to-limit-anthropic-linked-to-concerns-about-chinese-access-to-mythos 



