
ICLR 2026|美图提出位置编码场 PE-Field,让 DiT 感知和控制 3D 空间
随着AI创作从娱乐性质走向专业内容生产,业界对可控性的要求正在急剧攀升。保持人物一致性、复现复杂镜头语言、实现画面精准控制和局部空间编辑……这些能力逐渐成为AI创作的底层支撑。但现实是,视角旋转、物体移动、镜头推拉、空间补全等任务,大多还得靠Prompt控制或多阶段Pipeline来勉强完成,稳定性和可控性都存在明显短板。
所以,让生成模型具备更强的“空间理解能力”,成了AI视觉领域的一个重要攻坚方向,“Novel View Synthesis(新视角生成)”也因此备受关注。
近期,美图影像研究院(MT Lab)联合University of Texas at Austin(德克萨斯大学),提出了一种基于扩散Transformer(DiT)的3D位置编码框架——
Positional Encoding Field(PE-Field)
ICLR 2026

论文链接:2510.20385
开源代码和模型:GitHub - MTLab/PE-Field
DiT里的Patch Token,其实比想象中“独立”
在Diffusion Transformer(DiTs)中,图像通常会被划分为带有位置编码(Positional Encodings, PEs)的Patch Token,以此将Transformer的序列建模能力延伸到视觉空间。问题是,现有DiT主要在2D平面上处理位置编码,说白了位置编码更多是充当“位置标记”,对于更复杂的空间结构、几何关系、视角变化,建模能力相当有限。
研究团队在分析DiT如何处理视觉内容时,发现了一个有趣的现象:Patch Token在一定程度上表现出
独立性

图片1: DiT图像块级独立性

图片2:直接新视角合成(NVS)结果
PE-Field:将2D位置编码,扩展至3D场
受这个现象的启发,研究团队设计了Positional Encoding Field(PE-Field)框架。它的核心思路是:通过引入
深度感知
层次化控制
深度感知编码(Depth-aware Encodings)
DiT的常规位置编码只有X(横向)和Y(纵向),PE-Field则巧妙地引入了Z轴方向的深度信息。这样DiT就具备了“体积推理”的潜力——能感知场景里物体的前后远近,对三维深度结构有了更清晰的认知。
层次化编码(Hierarchical Encodings)
一般情况下,DiT里一个Token对应一个Patch。但为了实现更精细的控制,PE-Field采用了层次化的编码策略,允许DiT在更细的粒度上对几何结构进行建模。这样一来,模型不再是“大块大块”地理解画面,而是能深入到更微观的层面。
基于这两个核心模块,PE-Field让DiT在核心网络架构改动不大的情况下,就能自然地学习和建模3D几何特征,这在实际部署中是相当有优势的。
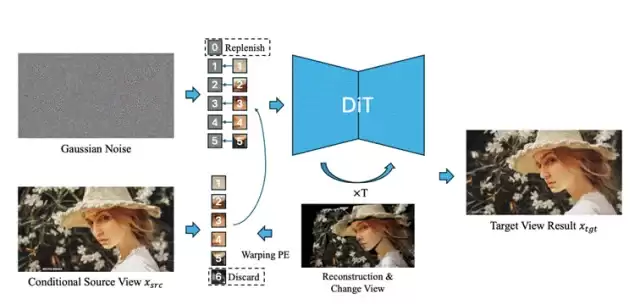
图片3:整体框架
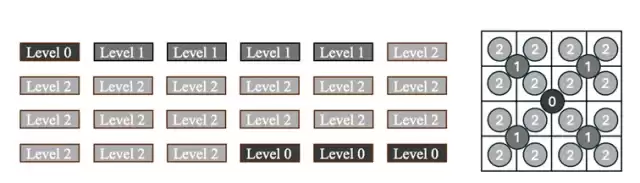
图片4:层次化位置编码
实验结果显示,引入了PE-Field的DiT模型在单张图像的新视角合成任务中交出了相当有竞争力的成绩:只需调整位置编码,就能生成质量较高的多视角结果。更重要的是,PE-Field的泛化能力也令人眼前一亮,在特定物体的3D编辑、物体移除等可控空间图像编辑任务中,展现出了不错的灵活性和适用性。

图片5:新视角合成结果可视化

图片6:与基于提示词的图像编辑方法的比较

图片7:其他应用场景-物体位置编辑与物体消除
面向真实创作场景:从前沿研究到产品落地
生成式AI正在加速融入专业化的内容创作。尤其在视频生成、3D重建等领域,对空间关系建模能力的要求越来越高。美图提出的PE-Field,正是基于对位置编码与空间结构关系的深入探索,为DiT的3D感知与空间控制提供了新的研究方向。
当然,理论研究的意义最终还是落在实际应用上。近年来,美图影像研究院(MT Lab)围绕生成式AI与影像Agent方向持续铺开技术能力,将人像美容、视频处理、专业创作辅助等AI能力广泛落地在美图秀秀、美颜相机、Wink、RoboNeo、开拍等产品中。他们的思路很清晰:让技术能力真正产品化,才能使生成式AI进入高频的创作流程。未来,依托从前沿影像技术研发到实际应用的商业化闭环,美图有望进一步推动智能创作在专业场景与大众场景的落地,为用户带来兼具创作自由度与个性化表达的产品体验。




