
数据建模怎么做?一文解析8种经典数据建模方法
AI越深入业务场景,数据治理的底子就越藏不住。标准统不统一、口径一不一致、链路清不清晰,最终都会在分析结果和模型效果上见真章。
在整个数据治理体系里,数据建模绝对属于关键环节。
它远不止是把数据结构化成表那么简单,更深层的价值在于,为分析、预测和决策搭建起一个稳固的框架。
很多人一听到“数据建模”,第一反应是“太专业了,搞不来”。但真把那些方法拆开来看,会发现常用的套路并没有那么玄乎。不同的问题场景,自然有对应的模型解法。核心是要搞清楚:它擅长解决哪类问题?具体怎么入手?落地时有哪些坑要避开?
今天这篇文章,
就把8种经典的数据建模方法一次性讲透
先说一个前提:数据建模从来不是孤立的活儿,它和数据标准、数仓建设、报表应用是一条完整的链路。模型要想真正跑起来,前面的基础工作往往比模型本身更关键。
一、回归建模
当目标预测是一个连续数值时,回归建模通常是最先想到的方法。
它的逻辑很直接,
核心就是找出自变量和因变量之间的关联,然后利用这种关系去做预测。
回归建模主要用来解决这类问题:
- 预估未来一段时间的销售收入
- 量化价格上调或下调对销量的影响
- 分析广告投入和转化量之间的关联强度
- 判断不同因素对最终业绩的贡献占比
真正上手时,有几个环节需要格外关注:
- 变量选择要有业务依据,不能无脑堆砌
- 缺失值和异常值必须在建模前排干净
- 多重共线性是个隐形杀手,需要提前诊断
- 模型拟合优度再高,也不代表业务因果关系一定成立
回归建模的价值,远不止于给出一个具体的预测数。更重要的是,它能帮业务看清楚,到底是哪些因素在真正驱动着结果。
二、分类建模
当问题不再是“值是多少”,而是“属于哪一类”时,就该分类建模出场了。
常用的分类方法包括
决策树、随机森林、支持向量机、朴素贝叶斯、逻辑回归
分类建模的强项在于,它特别容易和业务动作直接挂钩。
结果一旦出来,后续的策略就能无缝衔接。比如高流失风险用户自动进入挽留名单,高风险订单被标记出来走向人工审核,高潜客户则推送至重点跟进池。
在实际项目中,分类建模的瓶颈往往不在于算法选型,而在于前期的数据准备工作。
做分类建模时,建议把注意力放在这几件事上:
- 类别分布是否严重失衡?需要做采样或加权处理
- 特征构建的过程中有没有无意中引入未来信息(数据泄漏)
- 评估不能只看“准确率”,对不平衡问题要关注召回率、精确率、F1值
- 输出结果要能被业务方看懂,并且愿意拿去用
三、聚类建模
很多人容易把聚类和分类搞混,但二者的逻辑完全不同。
分类是已知类别去判断归属,属于“有监督学习”;聚类是在事先不知道类别的前提下,让数据自己“物以类聚”。
它最典型的应用场景,就是用户分群。
常见算法有 K 均值聚类、层次聚类、DBSCAN 等。选择哪一种,取决于数据本身的形态、样本规模以及最终的商业目标。
聚类建模能解决的问题包括:
- 用户分层,支撑精细化运营
- 探索商品的天然组合
- 对区域市场做结构化划分
- 识别出那些“不太一样”的异常群体
但有一点必须清醒:聚类结果本身不会自动告诉你“这组人叫啥、该怎么办”。
四、主成分分析建模
当变量多到眼花、字段杂得理不清,而且很多指标之间高度相关时,主成分分析(PCA)就派上了大用场。
它的核心目标是降维——在尽量保留原始信息的前提下,把一堆变量压缩成少数几个综合性的新变量。
举个常见场景:企业评估门店表现时,可能收集了几十个指标——客流、转化率、复购率、毛利、连带率、活动参与度……如果一股脑全塞进模型,不仅计算复杂,还是信息冗余的重灾区。
主成分分析正好可以把这些指标提炼成几个核心维度,后续建模和解释都会清爽很多。
主成分分析适合以下情境:
- 指标太多,分析维度过于散乱
- 变量之间相关性过强
- 希望降低模型复杂度
- 想构建一个综合性评分或指数
不过它也有个“小脾气”,就是解释性有时不那么直观。
五、因子分析建模
因子分析和主成分分析看起来有点“长得很像”,但目标是两码事。
主成分分析关注的是数据压缩,而因子分析更在意挖掘出变量背后那些共同的、不可观测的潜在因素。
比如在用户满意度调研中,问卷里设计了十几个问题,表面上是不同维度的考察,实际上很可能都在反映几个潜在的底层因子:产品体验、服务响应效率、价格感知、品牌信任度。因子分析就是帮你把这些“潜台词”从一堆数据里提炼出来。
它常被用在:
- 用户满意度及体验研究
- 员工敬业度或组织氛围调研
- 品牌认知与形象测量
- 对复杂指标体系进行结构化简化
因子分析的核心价值,是帮你在零散指标中找到底层结构。
做因子分析需要注意几点:
- 样本量不能太小,否则结果不稳定
- 变量之间最好存在一定关联性,否则萃取不出共同因子
- 因子命名需要结合业务语境,不能生搬硬套统计结果
- 只看统计显著性不够,更要考察业务解释价值
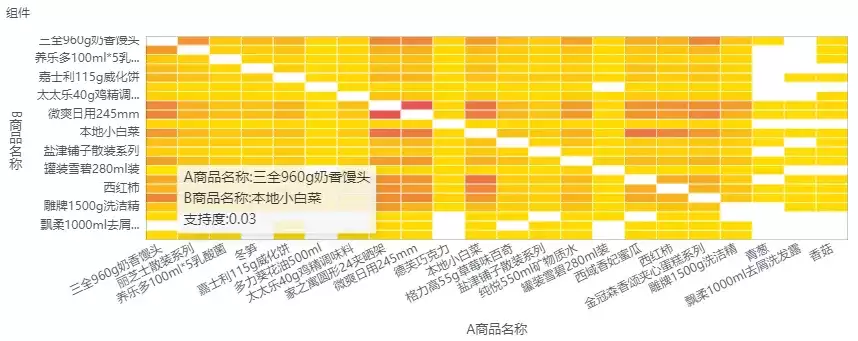
六、关联规则建模
说到关联规则建模,最经典的例子就是“购物篮分析”。
它要回答的问题是:哪些东西经常被一起购买?比如,买了咖啡的人,也倾向于顺手拿一盒奶精;买了婴儿湿巾的顾客,购物车里大概率也躺着纸尿裤。
这个领域的核心指标是支持度、置信度和提升度。
关联规则建模特别适合这类业务场景:
- 商品智能搭配推荐
- 促销组合方案的策划
- 识别交叉销售机会
- 挖掘用户行为路径中的规律
在实际业务中,真正有价值的不只是算出规则列表,而是把这些洞察及时、有效地呈现给运营和业务团队。
但也要提个醒:规则多不等于规则有用。
七、时间序列建模
只要数据带时间戳,并且你想捕捉趋势、周期、季节性和波动规律,时间序列建模就是首选。
和普通回归模型不同,时间序列模型非常强调数据之间的时间依赖关系。
时间序列建模要做好,最关键的是两手抓:
一是数据必须连续,二是口径必须稳定。
在这个场景里,上游数据链路的稳定性,直接决定了预测效果的上限。
做时间序列建模时,强烈建议先摸清这几件事:
- 数据是否存在缺口、异常跳点或结构性变化
- 是否有明显的季节性、节假日等周期性效应
- 是否需要按区域、门店等维度分层预测
- 预测结果是否能和业务动作(如补货、备货、营销)产生联动
八、聚类分析建模
严格来说,聚类分析和前面提到的聚类建模本质上是同一类思路,但在实际工作中,人们往往把它更偏向理解为一种探索式的分析手法。
前者更强调输出一个明确的分群结果,后者更强调通过数据内部结构来发现模式。
举个例子:你拿到一批设备运行数据,没有任何故障标签,也不知道该怎么定义“异常”类型。这时候先用聚类分析跑一遍,看看数据会自然分成几类,各类之间的差异在哪里,往往能帮你快速建立对数据的认知。再比如在市场研究中,对消费者样本进行聚类分析,也可以帮你提前识别出人群结构,为后续的分类、回归或策略制定做准备。
聚类分析建模适合用来做这些事:
- 项目前期探索数据分布
- 发现潜在的群体和隐含模式
- 为后续建模提供分层依据或标签基础
- 识别出那些“格格不入”的异常样本
它的价值不在于“一步到位”,而是帮你先把数据看懂。
九、写在最后
回顾这8种经典方法,每一条都在解决不同类型的问题。方法不同,适用场景也各有侧重,但它们的共同点是——都很实用,并且在企业真实分析场景中间出场频率极高。
说到底,数据建模不是为了把方法论学得多复杂、堆得多花哨,而是为了更高效地理解业务逻辑、支撑科学决策、推动策略落地。
希望这篇文章能帮你快速搭建起一个清晰的框架,知道常见的方法该怎么选、怎么用,也能在真正动手建模时,少走一些弯路。




