
传统 REST 接口设计:为什么它仍然是后端系统最稳的基本功
过去几年,GraphQL、gRPC、tRPC、BFF、AI Agent 接口一个个轮番登场,热闹得很。但真到了大多数业务系统里,REST 依然是那个最常见、最容易落地、协作成本最低的选择。
原因非常简单——REST 足够朴素。
它直接跑在 HTTP 上,不需要客户端和服务端去约定什么复杂的协议,也不用团队一上来就搭好整套 IDL、网关和代码生成体系。前端、移动端、后端、测试、运维,谁看谁懂。只要接口文档把 URL、Method、参数、返回值和状态码写清楚,大家基本就能愉快地合作了。
但也正因为 REST 看起来简单,很多项目最后会写成“披着 HTTP 外衣的随意 RPC”。所有接口都写成 POST /doSomething,状态码永远返回 200,错误都塞在 message 里,资源命名随心所欲,分页和过滤各搞一套。短期来看跑得挺顺,但时间一长,维护起来简直噩梦。
所以我们今天不聊课本那套,就说说传统业务系统里真正实用的 REST 设计习惯。
REST 的核心:围绕资源设计
REST 最核心的思想,不是用 JSON 传数据,也不是通过 HTTP 调接口,而是围绕资源来建模。资源可以是用户、订单、商品、文章、评论、文件、任务。设计接口时,URL 表达资源是什么,HTTP Method 表达对这个资源做什么动作。
比如订单资源:
GET /orders 查询订单列表
POST /orders 创建订单
GET /orders/1001 查询单个订单
PUT /orders/1001 整体更新订单
PATCH /orders/1001 部分更新订单
DELETE /orders/1001 删除订单
你看,看到接口就大概知道在操作什么资源、做什么动作,清晰明了。
相比之下,下面这种写法就很不 REST 了:
POST /getOrderList
POST /createOrder
POST /updateOrderStatus
POST /deleteOrder
不是说不能用,而是把动作都塞进 URL 里,HTTP Method 完全失去了语义。接口少的时候无所谓,系统一复杂,命名就乱成一锅粥了。
一个典型 REST 请求流程
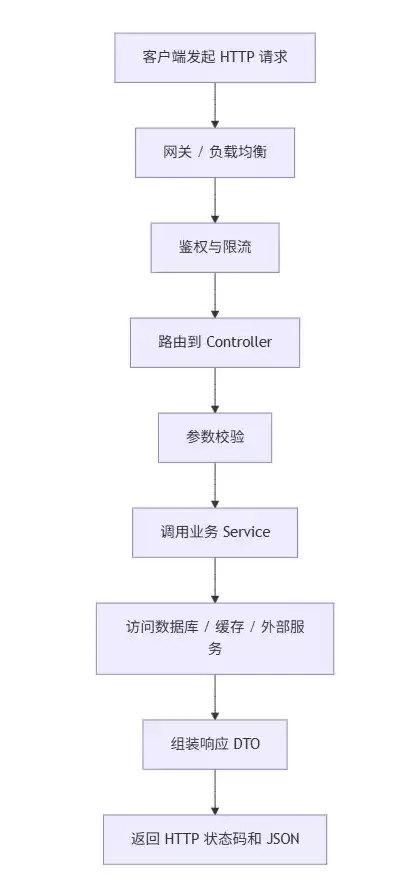
一个合格的 REST 接口,绝不只是 Controller 里能返回数据那么简单。在请求流程的每一层,都要有清晰的职责边界:网关负责通用流量,Controller 处理协议和参数,Service 执行业务逻辑,Repository 做数据访问,DTO 负责对外表达。
HTTP Method 别乱用
传统 REST 里最容易混乱的,就是 Method。
常见约定如下:
| Method | 含义 | 是否应该幂等 |
|---|---|---|
| GET | 查询资源 | 是 |
| POST | 创建资源或提交动作 | 否 |
| PUT | 整体替换资源 | 是 |
| PATCH | 局部更新资源 | 通常是 |
| DELETE | 删除资源 | 是 |
幂等的意思很简单:同一个请求执行一次和执行多次,最终结果是一样的。
比如:
DELETE /orders/1001
执行一次是删除订单,再执行一次,仍然是“订单不存在”,最终状态没有变化,所以它是幂等的。
而:
POST /orders
每执行一次都可能创建一个新订单,所以不是幂等的。
实际业务里,有些动作很难完全归类为一个资源,比如支付订单、取消订单、提交审批。这时候就把动作建模成子资源或者业务操作:
POST /orders/1001/payment
POST /orders/1001/cancellation
POST /approval-tasks/2001/submission
千万别为了形式上的完美,硬把所有业务都拧成一个 PUT /orders/1001。工程设计既要讲语义,也要讲可读性。
状态码不要永远是 200
很多系统喜欢这么干:响应体里 code 是 500,message 写着 server error,但 HTTP 状态码却永远是 200 OK。这对调试、网关、监控、SDK、缓存都很不友好,简直就是给自己挖坑。更合理的做法是:让 HTTP 状态码表达协议层结果,让响应 body 表达业务细节。
常用状态码:
| 状态码 | 含义 |
|---|---|
| 200 | 请求成功 |
| 201 | 创建成功 |
| 204 | 成功但无响应体 |
| 400 | 参数错误 |
| 401 | 未登录或 token 无效 |
| 403 | 已登录但无权限 |
| 404 | 资源不存在 |
| 409 | 资源冲突 |
| 422 | 语义校验失败 |
| 429 | 请求过多 |
| 500 | 服务端异常 |
错误响应可以统一成这样:
{
"error": {
"code": "ORDER_STATUS_INVALID",
"message": "当前订单状态不允许取消",
"requestId": "req_01HZX8K7"
}
}
code 给程序判断,message 给人看,requestId 给排障用。
查询、分页、排序,统一约定
列表接口是 REST 系统里最容易跑偏的地方。
建议大家统一使用 query string:
GET /orders?status=paid&createdAfter=2026-05-01&page=1&pageSize=20&sort=-createdAt
常见约定:
page / pageSize:传统分页
limit / offset:偏移分页
cursor / limit:游标分页
sort=-createdAt:按创建时间倒序
sort=createdAt:按创建时间正序
如果数据量大,或者列表会频繁新增,游标分页比 page 分页更稳:
GET /orders?cursor=eyJpZCI6MTAwMX0=&limit=20
返回:
{
"items": [],
"nextCursor": "eyJpZCI6MTAyMX0=",
"hasMore": true
}
千万别让每个接口各自发明一套分页字段。统一约定能直接降低前后端沟通成本。
接口版本管理必须提早规划
一旦接口被客户端用上了,就不能随意改动了。
常见的版本方式有三种:
/api/v1/orders
Accept: application/vnd.company.v1+json
?apiVersion=1
业务系统最常用的是 URL 版本:
GET /api/v1/orders
它不一定最优雅,但最直观,网关、文档、测试都容易处理。
版本管理的重点不是路径怎么写,而是不要破坏已有客户端。新增字段通常是兼容的,删除字段、改变字段含义、改变枚举值、改变错误结构,都是高风险变更。
鉴权和权限,不是一回事
REST 接口里经常混淆两个概念:
Authentication:你是谁
Authorization:你能做什么
前者通常通过 token、session、API key、OAuth2 完成。后者要结合角色、资源归属、租户、数据权限去判断。
比如:
GET /orders/1001
Authorization: Bearer
服务端不止要验证 token 是否有效,还要判断当前用户有没有权限访问这个订单。很多系统只做登录校验,不做资源级权限校验,结果只要用户猜到 ID,就能越权访问别人数据,这是重大安全漏洞。
REST 的优点和它的天花板
REST 的优点很明显:
- 基于 HTTP,生态成熟;
- 对人友好,调试方便;
- 对缓存、袋里、网关支持好;
- 前后端协作成本低;
- 适合 CRUD 和大多数业务接口。
但它也有自己的天花板。
当客户端需要灵活选择字段、组合多个资源时,GraphQL 可能更合适。
当服务间追求高性能、强类型、低延迟通信时,gRPC 是更好的选择。
当系统内部动作强过程化,比如复杂工作流、批处理任务、命令调度时,RPC 风格也未必比 REST 差。
REST 不是银弹,它最适合稳定、清晰、资源导向的业务接口。
实践建议
URL 用名词,不要用动词。
GET /users/1而不是GET /getUser。状态码要有语义,不要全部返回 200。
请求和响应 DTO 要稳定,不要直接暴露数据库实体。
分页、排序、错误结构、时间格式要统一。
- 比如支付、退款、创建订单,可以使用
敏感操作要考虑幂等。
Idempotency-Key。
POST /payments
Idempotency-Key: 8f0b2b4a-7f2e-4d8a接口文档要和代码一起维护。
总结
传统 REST 之所以还在大量系统里大规模使用,不是因为它够新,而是因为它够稳。它把接口设计约束在一个非常简单的模型里:资源用 URL 表达,动作由 HTTP Method 表达,结果由状态码表达,细节由 JSON body 表达。
真正写好 REST,不靠什么复杂框架,而靠一致性。命名一致,状态码一致,错误结构一致,分页一致,权限判断一致,系统就会越来越好维护。
新技术当然值得学,但 REST 依然是后端工程师绕不开的基本功。很多系统的问题,不是 REST 过时了,而是从一开始,就没认真设计过 REST。




