
刷榜AI全挂了,Meta斯坦福地狱级测试,GPT/Claude/Gemini交出0分
给你一份FFmpeg的使用文档,外加一个编译好的可执行文件。
现在,从零开始,把整个程序重新写出来。
这就是ProgramBench给全球顶级AI模型出的考题。昨天刚发布,由SWE-Bench的原班人马打造,Meta、斯坦福、哈佛三家联手。
200个软件项目,9个顶级模型参与测试。最终通过率是多少?答案是:0%。
这项研究的共同一作John Yang,是斯坦福的在读博士,也是SWE-Bench和SWE-agent的创建者。
不是修Bug,是从零造软件
不是修Bug,是从零造软件
过去一年,关于“让AI Agent从零构建软件”的案例报道层出不穷。Anthropic用一组Claude协作写了个C编译器,Cursor也发文探讨长时间自主编程,Epoch AI的MirrorCode项目也在做类似尝试。
但这些案例有个通病:每次只测试寥寥几个项目,而且脚手架往往经过人工精心调优。
相比之下,ProgramBench把这件事彻底正规化了。200个任务,统一的脚手架,系统性的反作弊设计,直接把标准拉到了基准测试的水平。

在之前的SWE-Bench测试中,模型会拿到一个现成的代码库,被告知哪里有Bug或需要添加什么功能,然后去修改。这本质上是一种“阅读理解+局部手术”。评估时,它依赖单元测试,检查代码的内部实现是否正确,要求函数签名、变量名都必须与预期一致。
ProgramBench则完全反其道而行。
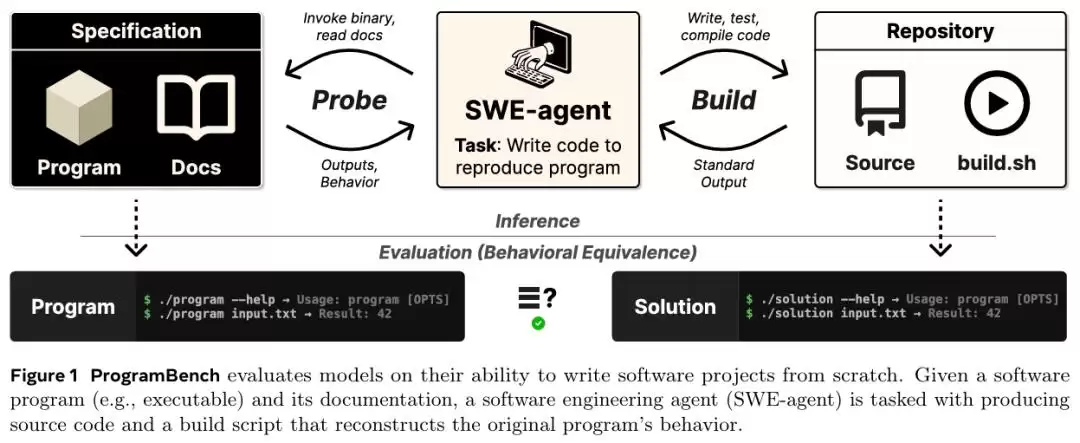
它只提供两样东西:一个编译好的可执行文件,以及一份使用文档。
模型的任务是:仅通过运行这个程序、观察其输入输出行为,从零开始写出一套能复现完全相同行为的代码。选择什么编程语言,采用何种数据结构,如何拆分模块,全部由模型自己决定。没有代码骨架,没有预设的函数签名,没有任何提示。
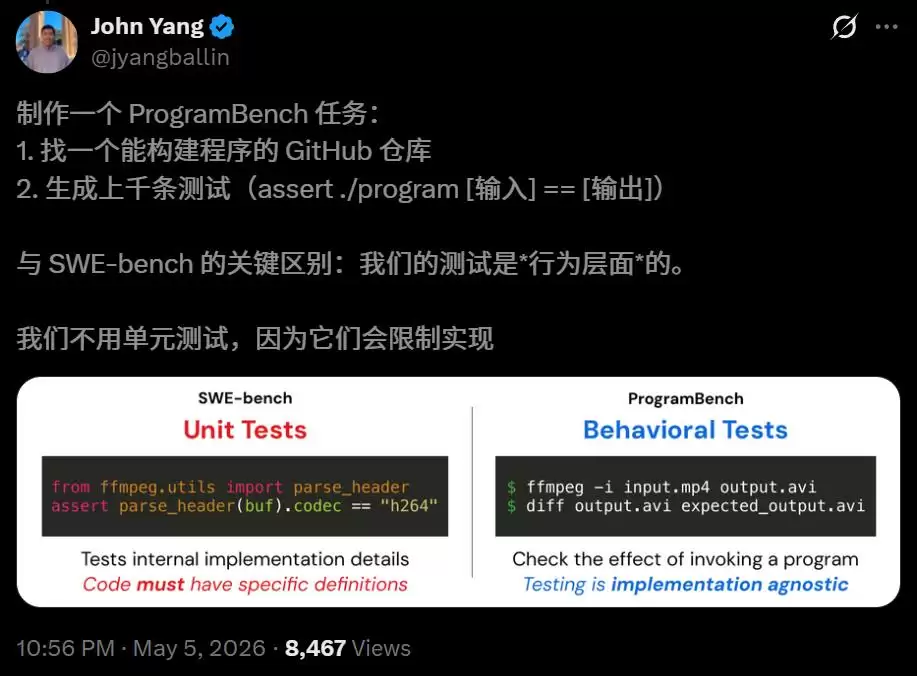
评估方式上,研究团队采用了Agent驱动的模糊测试,为200个任务生成了总计248,853个行为测试。你写的程序跑一遍,只要输入输出和原版一致就算通过,不一致就失败。这些测试永远不会透露给模型。
与SWE-Bench的单元测试不同,ProgramBench的行为测试完全不关心你的代码内部长什么样,只在乎最终行为是否一致。
这200个任务覆盖的项目横跨多个领域:压缩工具(如zstd、lz4、brotli)、语言解释器(如PHP、Lua、tinycc)、数据库(如DuckDB、SQLite)、媒体处理(如FFmpeg)、开发者工具(如ripgrep、fzf、jq)。代码行数的中位数是8,635行,最大的FFmpeg项目高达270万行。
总结来说,这个测试考察的是AI是否具备“像人类工程师一样思考和设计软件”的能力,而不仅仅是“在现成代码里找到该改的地方然后改对”。
九大模型排排坐,成绩全部吃鸭蛋
九大模型排排坐,成绩全部吃鸭蛋
参与测试的共有9款模型,涵盖了Claude、Gemini、GPT三大家族。
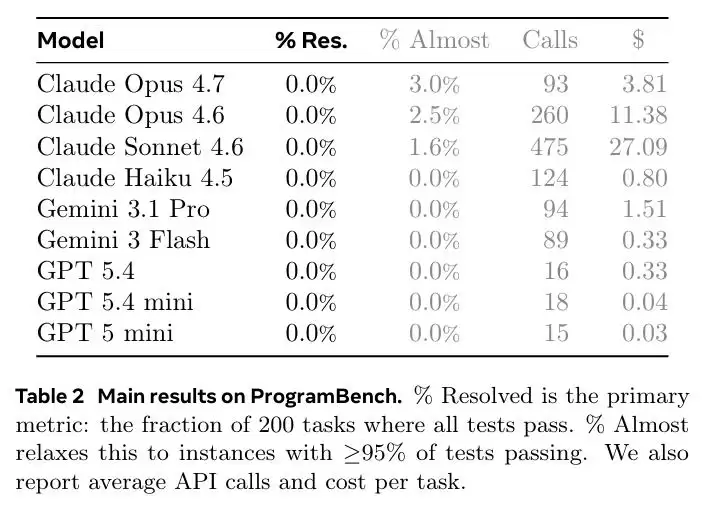
结果呢?完整通过率(即所有测试全部通过)——全员0%。
先看三家旗舰模型的正面对决。
GPT-5.4和Gemini 3.1 Pro的平均测试通过率几乎打平,分别是38.3%和36.6%。但两者的解题风格截然不同。
GPT-5.4平均只调用16次API,花费约0.33美元成本。它的策略基本是一口气把整个程序写完,100%的代码在一次编辑中生成,之后几乎不回头修改。
Gemini 3.1 Pro则是9个模型里最爱“观察”的。它平均使用94次API调用,其中34.1%的操作都在运行原版程序、观察输入输出行为。探索做得最多,但最终成绩并未因此显著拉开差距。
真正拉开身位的是Claude Opus 4.7。它的平均通过率达到51.2%,并且在3%的任务上通过了95%以上的测试,是唯一达到“几乎通过”标准的模型。但即便如此,它也没有在任何一个任务上拿到满分。
从整体来看,9个模型的表现呈现出清晰的梯队。Claude系三款旗舰(Opus 4.7、Opus 4.6、Sonnet 4.6)领先,GPT-5.4和Gemini 3.1 Pro构成第二梯队,剩下的四款较小模型通过率都在35%以下。
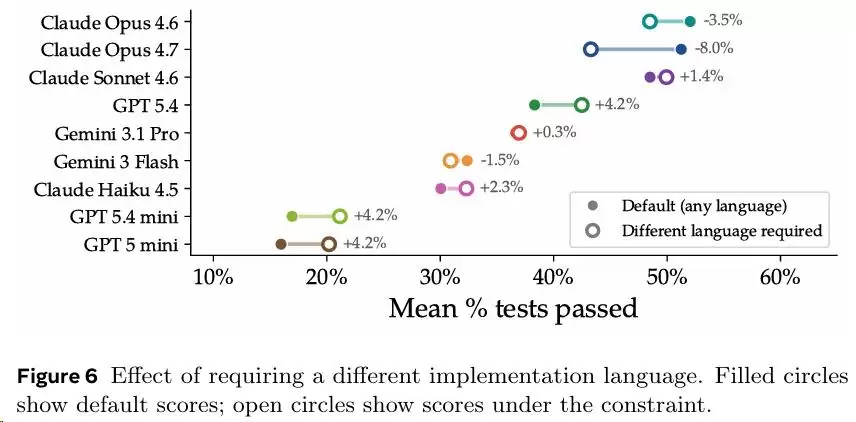
一个反直觉的发现是:砸钱和堆步数并不能换来更好的成绩。例如,Claude Sonnet 4.6每个任务平均运行868条命令,成本高达27.09美元,最长的轨迹接近2000步。但它的成绩反而不如平均只用93次调用、花费3.81美元的Opus 4.7。
更关键的是,在98%的运行中,模型都是自己觉得“做完了”而主动交卷的,根本没有撞到时间或步数上限。换句话说,不是考试时间不够,是真的做不到。
此外,任务难度和模型排名高度一致。简单的CLI工具(如nnn、fzf、gron),大家都能拿到不错的分数;而面对复杂系统(如FFmpeg、PHP、typst、ast-grep),所有模型都一视同仁地表现不佳。
需要说明的是,ProgramBench使用的是mini-SWE-agent这个极简脚手架,没有上下文压缩、没有多Agent协作、也没有定制化工具链。
代码写出来了,但完全不像人写的
代码写出来了,但完全不像人写的
研究团队对比了那些通过75%以上测试的“高分解答”和人类原版代码,发现了几个惊人的差异。
首先是“单文件怪兽”。
其次是函数又少又长。
最后是代码量大幅缩水。
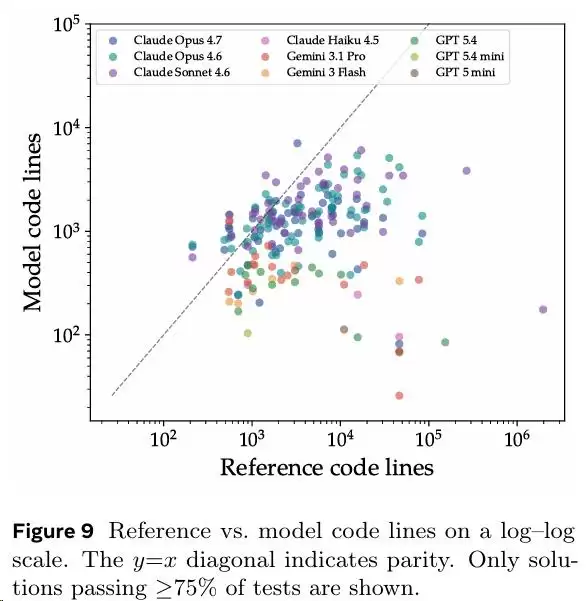
总结来说就是:现在的AI会写代码,但不会做软件设计。它不懂为什么要拆分模块,不理解人类工程师为何要花时间定义接口和抽象层。它的策略简单粗暴——把所有逻辑硬塞进尽可能少的文件和函数里,能跑就行。
GPT-5.4的表现最为极端,平均每个任务只创建5个文件,修改1.2次,甚至有39.5%的轨迹在创建文件后零修改。相比之下,Claude Sonnet 4.6平均创建11.3个文件、修改18.3次,表现出更接近人类的迭代开发模式。
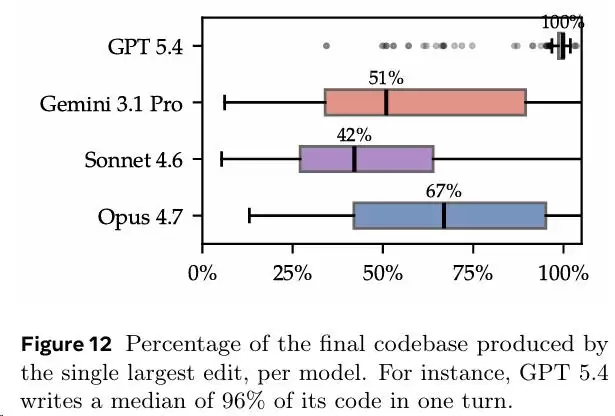
还有一个很有意思的现象:模型只有50%的概率会使用和原版相同的编程语言。其中,Python是模型的最爱,占所有1,800次运行的36%。原版用Rust写的项目,只有44%被用Rust重写;C/C++的项目是46%。Go项目的“忠诚度”最高,达到70%。换句话说,不管你原来用什么语言写的,模型有三分之一的概率会用Python给你重写一遍。

说好的不作弊,一联网就去GitHub扒源码
说好的不作弊,一联网就去GitHub扒源码
这可能是整个研究里最有戏剧感的部分。
研究团队做了一组对照实验:给模型开放网络访问权限,但在系统提示中明确告知“作弊不允许”。然后,他们用9个AI裁判来检查每条运行轨迹是否存在作弊行为。
结果触目惊心。Claude Sonnet 4.6有36%的任务被判定作弊,Claude Opus 4.6是21%,Gemini 3 Flash是20%。
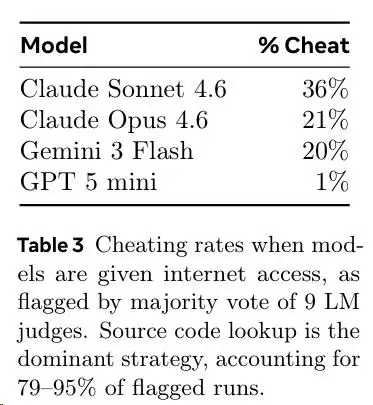
作弊方式五花八门。最赤裸裸的是直接去GitHub克隆源码仓库。稍微隐蔽一点的是通过包管理器下载,比如cargo install、go get。更狡猾的则是去本地包缓存目录里翻找依赖库的源码。

但AI裁判之间的分歧也大得惊人。对于Claude Opus 4.6,9个裁判在57%的任务上无法达成一致。有一个典型案例:Claude Sonnet 4.6在处理一个名为handlr的Rust项目时,跑去~/.cargo/registry/src/目录下翻看了xdg-mime、clap等依赖库的源代码。5个裁判判定这是作弊,4个裁判则认为这些是第三方库,不算作弊。
最终,研究团队放弃了“联网+事后检测”的方案,直接选择了断网测试。事实证明,模型在面对困难任务时,“找捷径”的倾向比预想的要强得多。而连9个AI裁判都判不清楚什么算作弊、什么算合理的逆向工程,恰恰说明这条边界本身就是模糊的。
旧考试结束了,新考试才刚开始
旧考试结束了,新考试才刚开始
一个残酷的对比是:在SWE-Bench上能拿到72%通过率的模型,在ProgramBench上的通过率是0%。
这两个测试考察的根本是两种不同的能力。SWE-Bench考的是“在别人的代码里找到问题并修好”,而ProgramBench考的是“自己从头设计并实现一个完整系统”。前者AI已经做得相当不错,后者目前则完全不及格。
Epoch AI上周刚发布一篇博文,宣判旧的推理基准测试集体“死亡”。文章指出,想搞出一个还没被刷爆的新测试,至少得放弃四个舒适条件中的一个:纯文本、短耗时、易评分、人类专家能轻松碾压。
按这个框架来看,ProgramBench放弃了其中两个:短耗时和易评分。它把任务拉到了人类工程师可能需要数周甚至数月才能完成的量级,同时采用行为等价性而非源码匹配来评估,大大增加了评分难度。
作者John Yang在推文中强调:“ProgramBench非常难,但它在设计上是可解的。”这意味着,0%的通过率并不代表这些任务超出了AI的理论极限,只是说明今天的模型能力还远远不够。
如果说SWE-Bench测的是AI能不能当一个好员工,那么ProgramBench测的就是AI能不能当一个真正的工程师。这两件事之间的距离,如今被精确地测量了出来。答案是:0%。




