
俩小时就烧掉400块Token后,我终于看懂Claude Fable 5有多猛
Claude Fable 5 在 6 月 10 日发布之后,知危在推特上围观了大量展示案例。印象最深的,倒不是那些 UI 设计、物理模拟,或者一天之内迁移五千万行代码的代码库——毕竟超出个人认知范围的事,说了也白说。反而是被一个看起来特别简单的例子给吸引了。

来源:https://x.com/ProperPrompter/status/2064405487492452856
提示词:
使用 SVG 模拟像素艺术,创建一个精美且细节丰富的可爱动物场景。每个“像素”的大小应该相同。
用 SVG 让大模型画图,先前也不是没人试过。但这次是知危第一次感觉,AI 作画的画面是那么自然协调:不管动物的形态、环境的氛围,还是颜色的组合,都让人觉得 Claude Fable 5 像是“用眼睛看着”在画。
而在看到下面这个案例之后,加上它火速通关《宝可梦:火红》的战绩,这不由得让人产生一个强烈的联想:Claude Fable 5 或许真的拥有某种 3D 视觉思维,或者说,某种“空间智能”。
于是,在这期测评里,知危打算重点考验一下 Claude Fable 5 用代码构建视觉概念的能力。(全程使用 Claude Code 测试)
网友似乎更热衷于让 Claude Fable 5 直接搭一个《我的世界》。但问题是,里面绝大部分是平凡的地形元素。要验证模型是否真有“视觉思维”,还是应该让它去实现一些非平凡的概念和性质:比如带有 IP 属性的形象、二次组合创新、对原创设计的即时理解等。
不过,正式开始之前,还是先用一个比较复杂的案例,看看 Claude Fable 5 的基础编程能力。
在一个曾经用来挑战过 Gemini 3 Pro 等模型的 3D 引擎案例上,Claude Fable 5 交出了目前为止最好的答卷。需求全部实现、没有 bug 之外,它是所有参与测试的 AI 中唯一一个没有漏掉左侧模板库的。
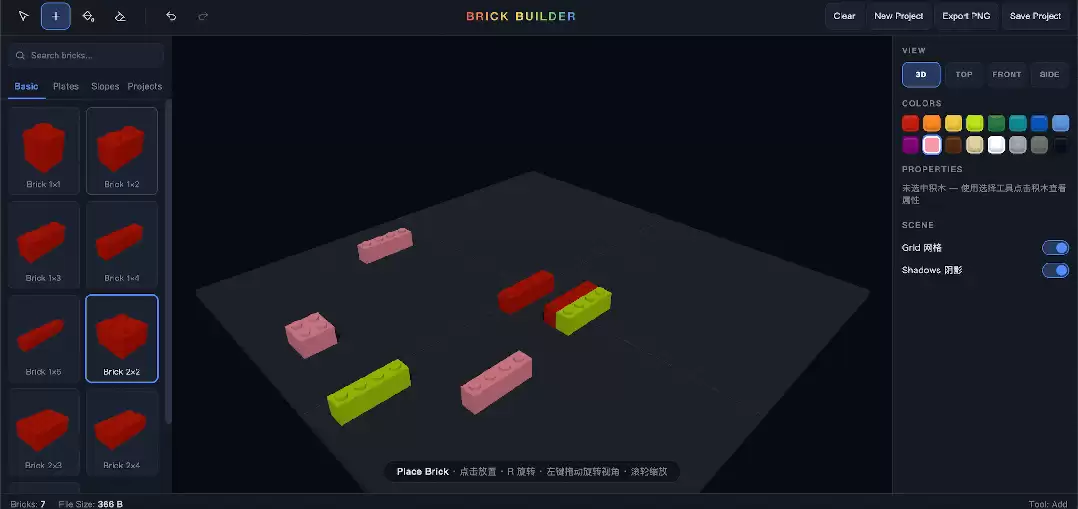
当然,这只是前菜。毕竟网页版的 Claude Sonnet 4.6(low effort)在这个案例上也基本能搞定。
接下来,才是真正考验视觉理解和构建能力的时候。
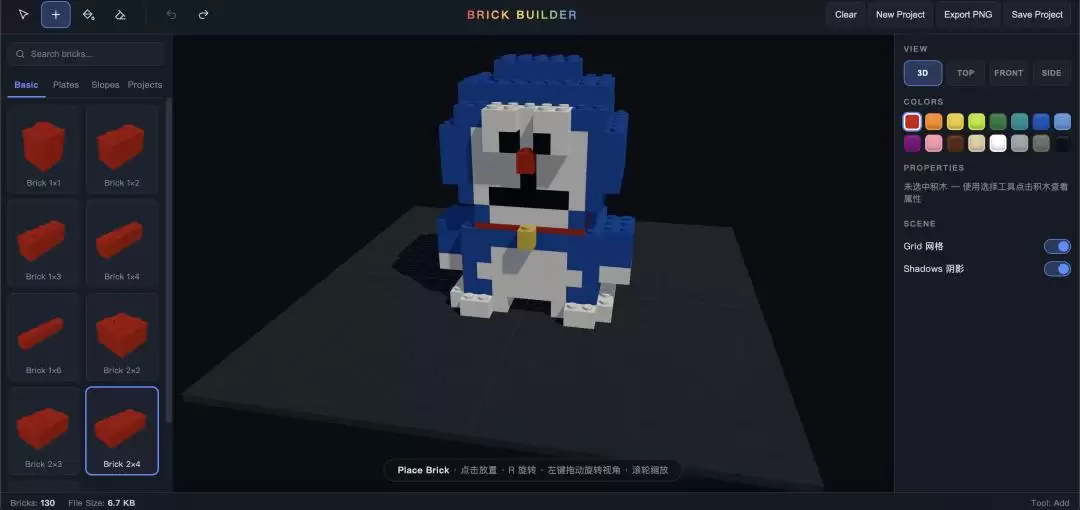
第一步,直接让 Claude Fable 5 用刚才写好的 3D 引擎,搭出一个哆啦 A 梦的 3D 模型。结果堪称完美。
再来一个乔巴,惊喜远多于槽点。
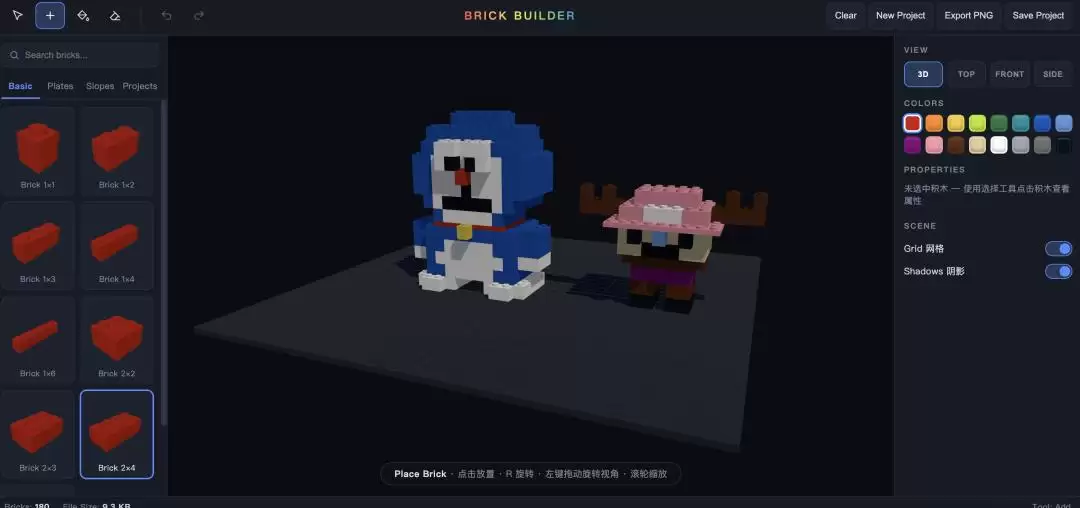
继续,加一个路飞放在他们身后,并且特意强调了是“3 档形态”。Claude Fable 5 很好地理解了在这种形态下,路飞那巨大的手臂。
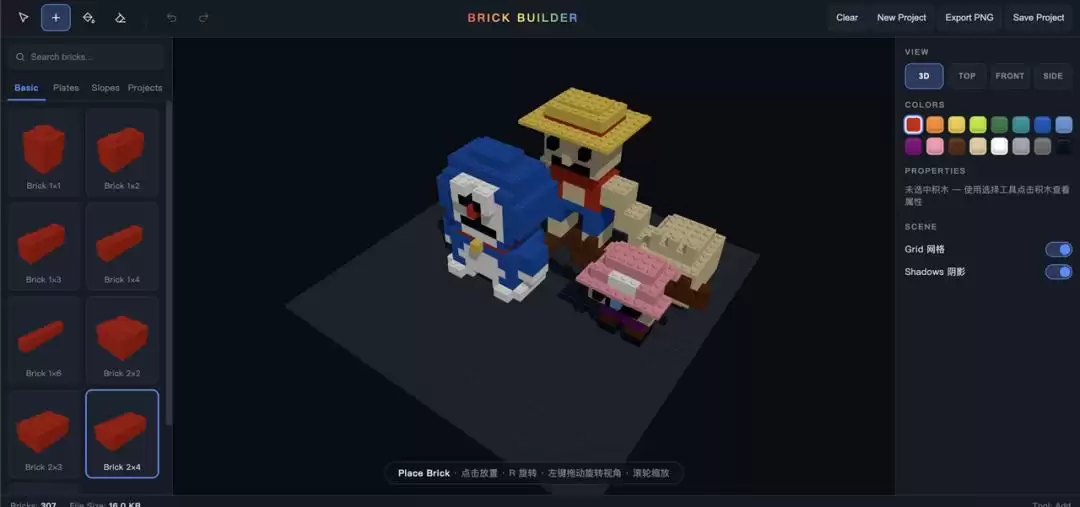
最后,想让场景更丰富一些,就要求它画出路飞的海贼船——“黄金梅利号”,并让他们三个站在甲板上。
结果不太理想。那么大一艘海贼船,被 Claude Fable 5 画成了只能在景区湖里用的小船。不过,模型有刻意去还原船头的羊头标志和海贼旗,也算是很细节了。
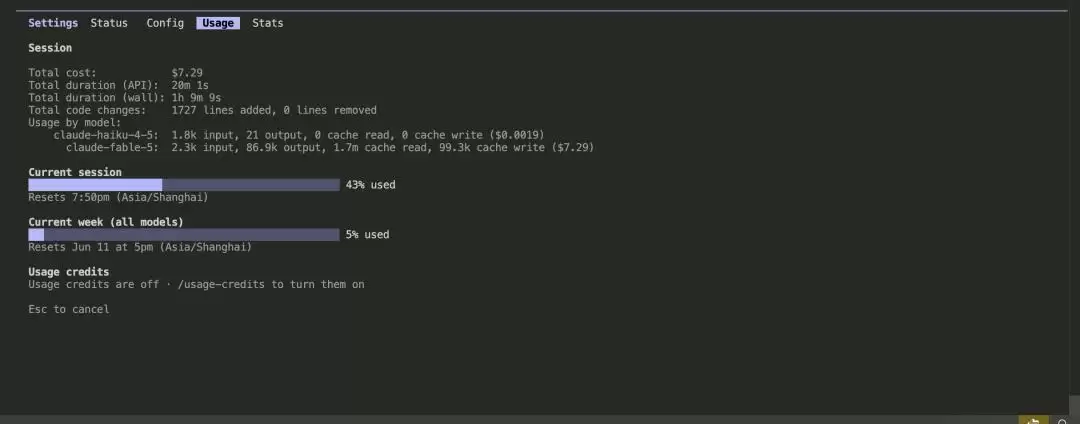
做完上述测试,Claude Code 消耗了 43% 的 5 小时额度,以及价值 7.29 美元的 Token。价格确实不菲,想玩得尽兴,Pro 级订阅可能不太够用。
“黄金梅利号”的“崩塌”,可能是工作空间太小,导致 Claude Fable 5 难以发挥。
接下来,打破引擎框架的限制,开始构建更复杂的对象。让 Claude Fable 5 直接用 Three.js 来构建《我的世界》风格的艾尔迪亚王国——也就是《进击的巨人》中,由三堵圆形城墙为框架建立的城堡。
提示词:
你将使用 Three.js 构建一个第一人称体素(Minecraft-like)沙盒原型,自由组织项目,可以引入依赖和后处理。
目标:实现一个以《进击的巨人》“艾尔迪亚王国三层城堡”为核心的可交互体素世界。
核心场景:艾尔迪亚三层城堡。世界核心是一个巨大的“帕拉迪岛风格王都城堡”,采用三层城墙结构:玛丽亚,罗塞,希娜。
核心体验:玩家出生在最外层的城墙(玛丽亚)上方,可沿城墙环绕行走,可从城墙落到地面,可从地面爬上城墙。世界是程序生成的体素地形,要有村庄、城堡、河流、草原和树林。
玩法基本保留 Minecraft 经典手感:第三人称,WASD+鼠标,左键破坏,右键放置,带物品栏。其余细节由你发挥,打开第一眼就要被城墙和夕阳震住。
如果实现成功,应满足:
玩家进入世界后看到三层城墙明显分层结构;
能在不同层之间移动(楼梯/绳索/地面);
第一层复杂、第二层规整、第三层宏伟;
可以自由破坏/放置方块;
城堡结构在视觉上“可读”(一眼看出三层权力结构)。
提示词没太多讲究,关键在于多强调目标、验收标准,而不是过程。
执行过程中,Claude Fable 5 会持续多次调用 Chrome CLI headless 截图,查看并测试当前实现效果。看起来,确实很像是在“边画边看边测试边思考”。
不过,使用 Chrome CLI headless 截图可能会触发 Mac 权限限制等问题,导致进度一直停滞。参考了 ChatGPT 的建议,把原方案改为 Playwright 方案(Playwright 是一个开源的浏览器测试和网页抓取自动化库),这才顺利完成了项目。
来看看效果如何:
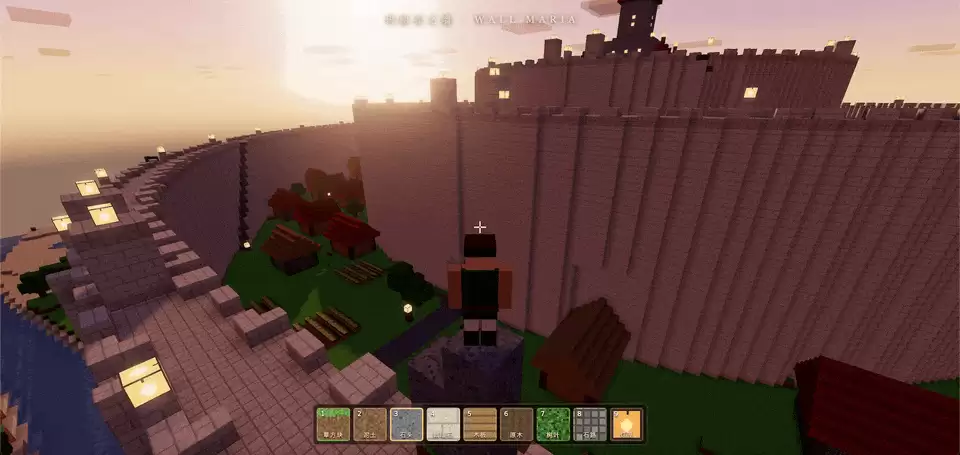
一眼看过去还是非常惊艳的。一个镜头就能直接把夕阳下三堵巨大城墙的视觉效果呈现给你。城墙上的竖条纹非常符合原作的特点。你甚至还能发现,作为主角的士兵可以确定是调查兵团的,因为披着绿色的披风。
当然,这个结果的复杂度,肯定还远比不上人类的 Minecraft 作品。比如下面,由 DSOGaming 的创始人兼主编 John Papadopoulos 创作的作品。

要知道,Claude Fable 5 只是完成了艾尔迪亚王国的宏观框架。平原上的村庄、森林过于凌乱而随意,最核心的居民区——也就是瓮城——连个影子都没有,城墙之间间距过窄,谈不上任何“史诗级”的氛围。
反过来看,Claude Fable 5 搭建出来的成品,至少没有和我搜索到的任何相关作品雷同。所以目前来看,这是它基于自己的理解、而非套训练数据做出来的概率,相对更高一些。
接下来,就要加难度了,主要是把上述槽点都修一修。
调整宏观尺寸。
提示词:
请调整尺寸,人身高:城墙高度=1:50,城墙高度:相邻城墙距离=1:20。在每个城门的部分,还有再略为向外突出的半圆形城墙的瓮城。
Claude Fable 5 分析了需求,认为间距过大会让三堵墙无法在视觉上一镜同屏,且需要重写为流式生成——后面会解释,这是基于视觉渲染效率的考虑。它竟然提供了三个完全不同的选项:要么保持当前间距,要么去实现极端大间距,要么做一个折中。
按原来提示的极端大间距下,同屏是不可能的,很影响视觉氛围,而且从一堵墙到另一堵墙的徒步时间过长。最后选择了折中方案。

折中方案也不错,三堵墙一眼尽收眼底。
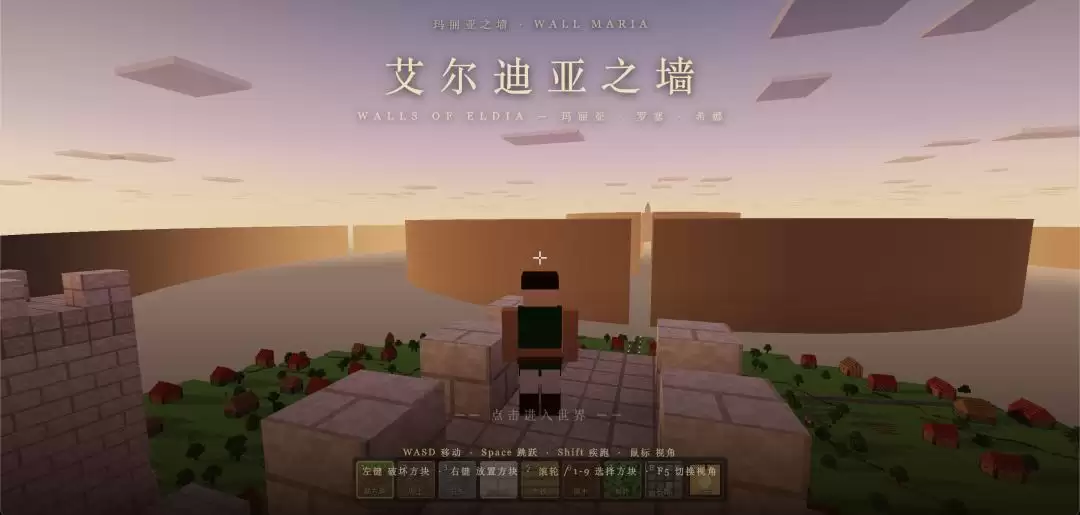
乍一看,会觉得 Claude Fable 5 用平滑的、无结构的墙面来偷懒,城墙上还有莫名其妙的缺口。但走近了之后,才理解它的苦心。

随着离城墙越来越近,墙面的真实结构也逐渐显露出来,原来的缺口也被填补了。
追问了一句:“为什么将城墙半径扩大需要很大量的工程?具体有哪些工作内容和挑战?”
Claude Fable 5 解释道:
生成不贵,“让你看见”才贵。
这应该是指,如果要把场景内的所有细节一次呈现给你,内存占用过高,会无法流畅运行。所以一般是近景才做细节渲染,远景只做粗糙些的渲染——也就是所谓的流式生成或流式渲染。这其实是很多游戏、特别是开放世界游戏的常用优化手段。

重点是,它就连优化和折中的重点,也放在了视觉层面。
但瓮城里是真的什么都没有,连门都给封住了。
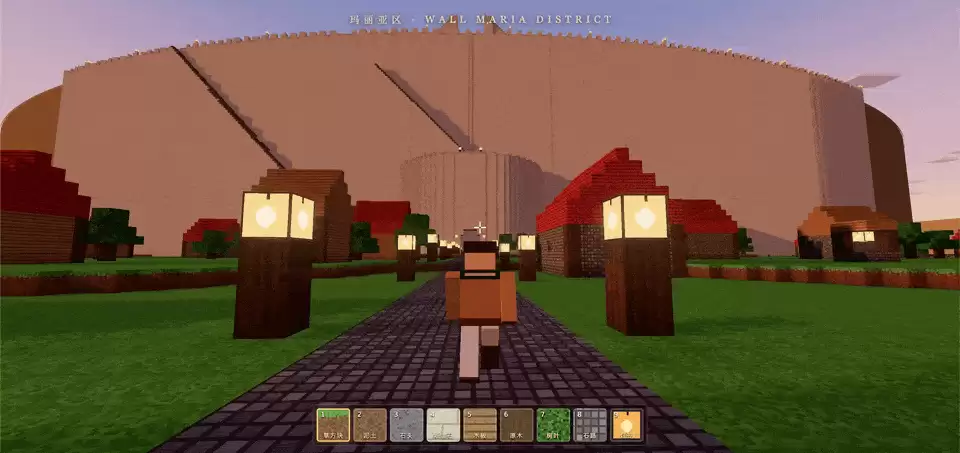
还好,Claude Fable 5 按要求提供了爬上城墙的楼梯——这可是原作里不存在的东西。
接下来,要完善一些细节,并且分三步,给它一个终极大考。
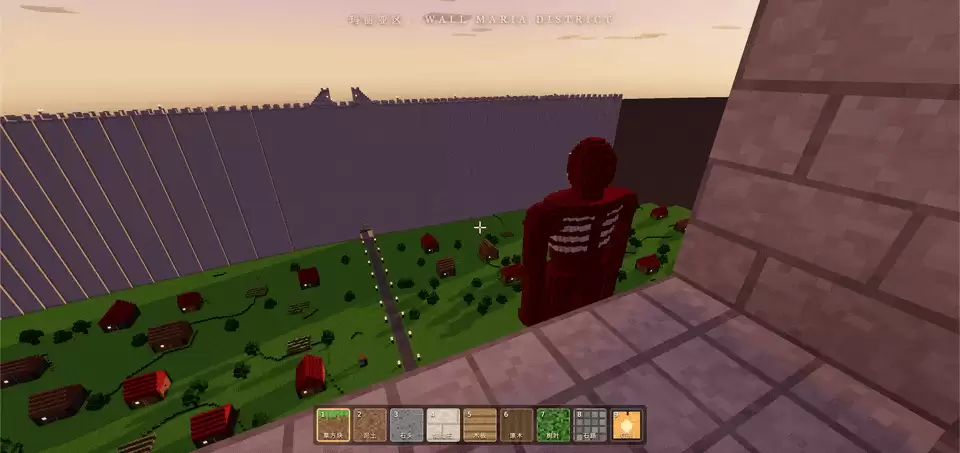
第一考:在玛丽亚之墙和罗塞之墙之间的平原上,构建一个超大型巨人,身高和城墙相当。
结果如下:
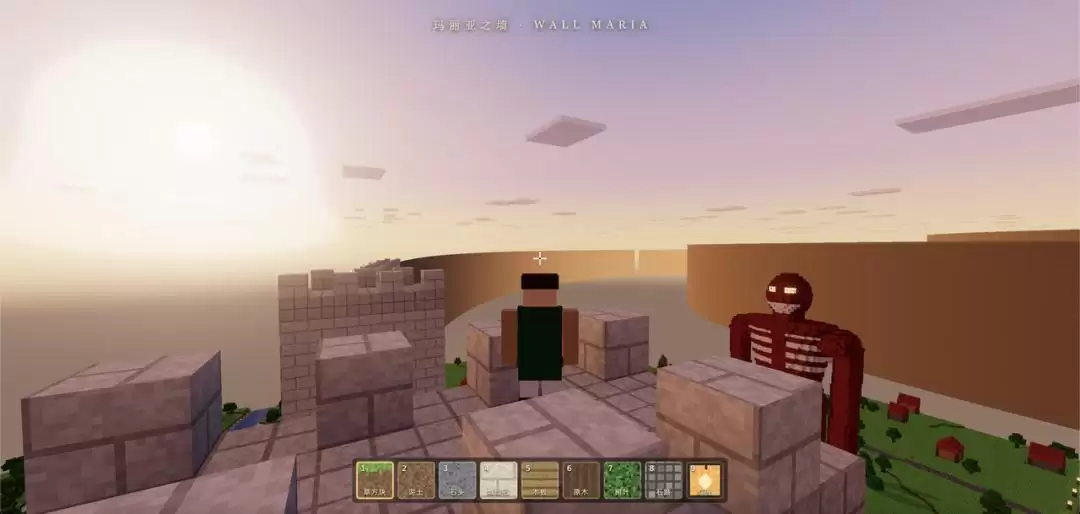
这个巨人虽然有点像闪电侠,但按完成度来看没有什么大毛病。当然,这也只是个前菜,提供一些氛围感。
第二考:到目前为止,主要感受了 Claude Fable 5 还原 IP 特征的能力、从游戏玩家视角思考构图的能力(比如流式渲染)、在细节上组合创新的能力(比如在城墙上嵌入楼梯)。那么还差最后一点:基于原创设计的即时理解能力。
给 Claude Fable 5 提供了一张来自艺术家 Jarlan Perez 的机器人概念设计作品,让它在罗塞之墙和希娜之墙之间的平原上,把机器人复刻出来,身高也和城墙相当,并把玩家的出生点从玛丽亚之墙转移到罗塞之墙,便于验收和观察。
参考图:

结果如下:
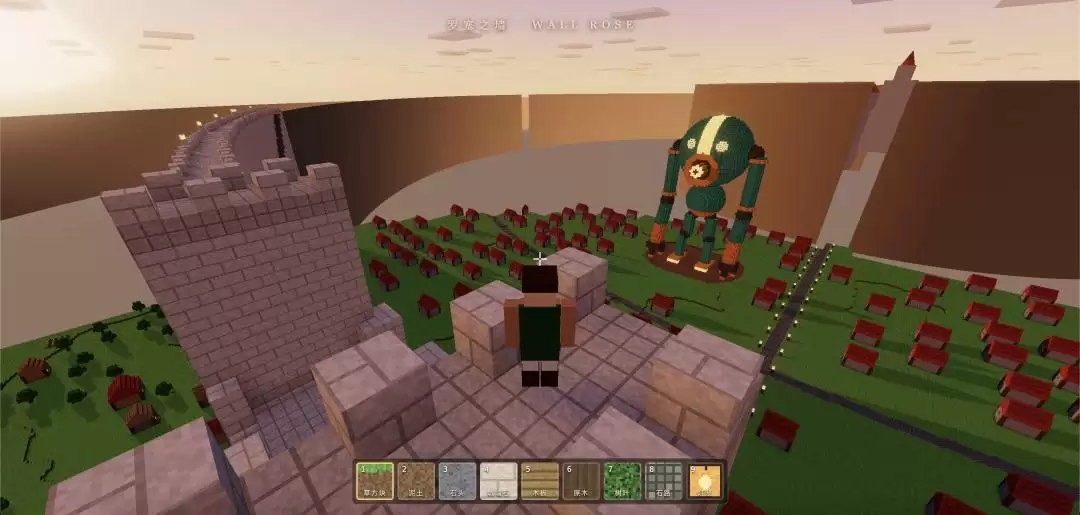
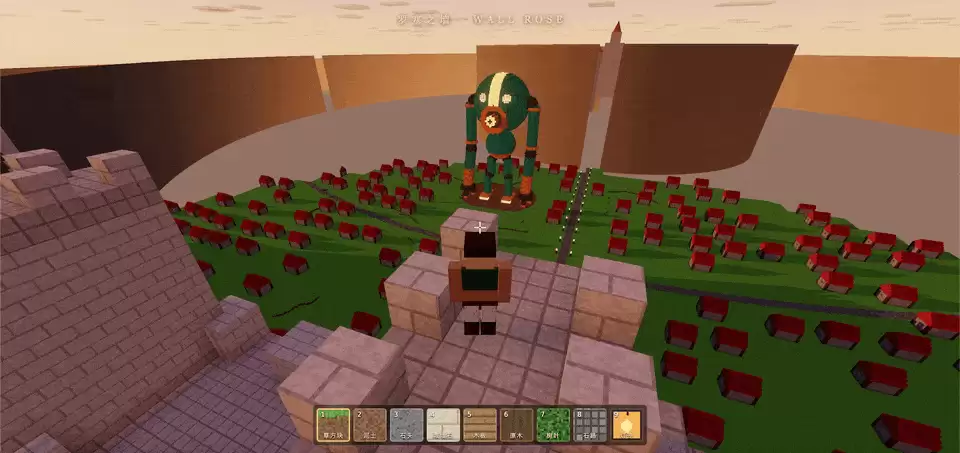
这个结果,可以说比超大型巨人好多了。除了眼睛做得不像,其他部分的还原度都很高。
另外也能看出,Claude Fable 5 有刻意将玛丽亚之墙和罗塞之墙之间的城市做得更加规整一些——虽然希娜之墙内部还是很敷衍。
最后一考不看局部细节,而是让 Claude Fable 5 直接挑战人类。
也就是看它能不能构建一个达到人类高级玩家水平的瓮城。不只是给语言提示,还要用参考图的细节程度暗示模型不能偷懒。参考图选用了动画原作的托洛斯特区鸟瞰图,它刚好位于现在罗塞之墙出生点的南边。
参考图:

来看看最终结果如何:
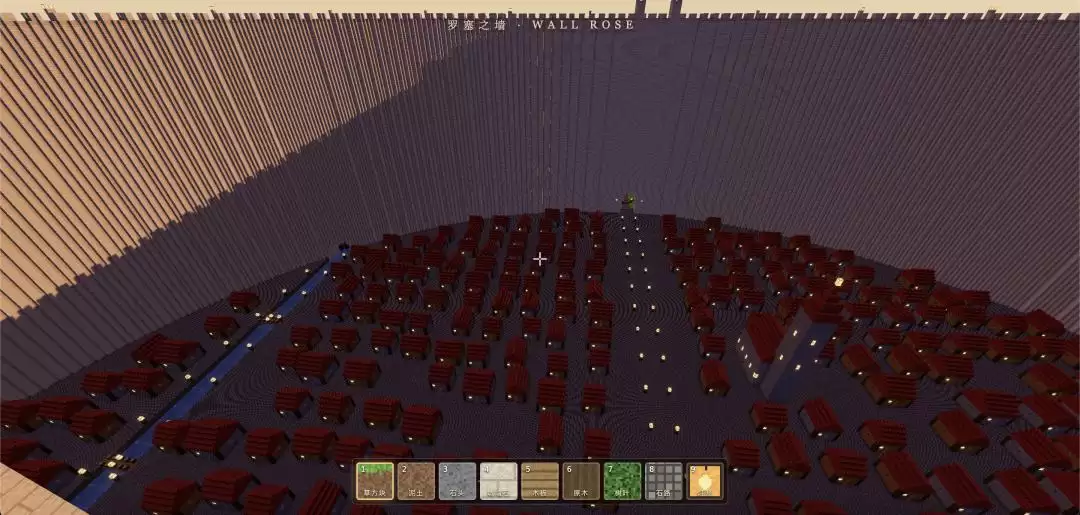
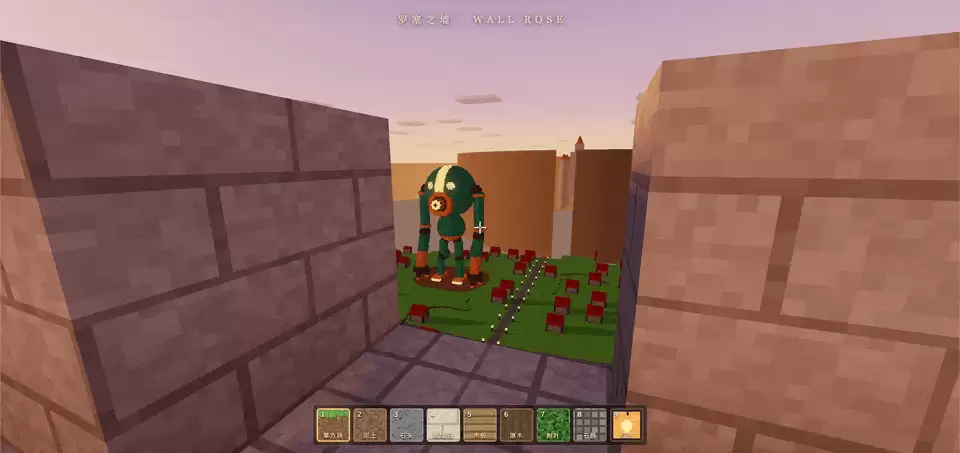
如果走到对面的瓮城城墙上,也能看到城墙外的超大巨人的背部——是合理的。
如果要跟 John Papadopoulos 的作品相比较,很明显,人类还是胜出。但就完成度而言,包括尺寸、河流、居民区、中心处高塔,都成功地呈现了,也算是交出了一份及格卷。

这三大考直接耗尽了 5 小时额度。可见要真做出 100% 还原的艾尔迪亚王国,有多烧 Token。
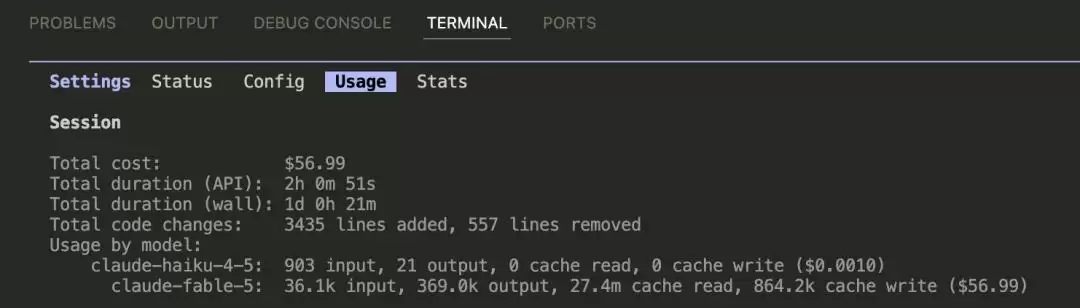
到此,加上之前用来构建 3D 引擎、动漫形象,总共用了 2 小时 API 时间,成本达到了价值 56.99 美元的 Token 消耗(订阅制+Fable 是真香,可惜快没得用了)。而我的艾尔迪亚王国,如果要做到在静态视觉上基本还原的程度,目前的完成度估计还不到十分之一。
测评结束。
回到文章开头的问题:Claude Fable 5 究竟有没有“视觉思维”或一定程度上的“空间智能”?
经过这轮测试,依然无法给出一个确定答案。但至少在这次体验里,Claude Fable 5 展现出的能力,已经超出了传统意义上“根据提示生成代码”的范畴。
它会一边写代码一边观察,会主动考虑构图,会权衡视觉呈现与性能消耗,会为了远景观感调整世界尺度,会对原创参考图做出极致的视觉还原。
从哆啦 A 梦、乔巴、路飞、“黄金梅利号”,到艾尔迪亚王国、原创机器人概念设计,再到最终的托洛斯特区——它表现出的并不是简单的复读与拼接,而更像是在不断建立、修正和验证自己对目标的视觉理解。
当然,它距离真正的人类创作者还有很长距离。它的细节塑造能力依然有限,审美稳定性也谈不上完美,而高昂的 Token 成本更决定了这种创作方式暂时难以普及。
但不可否认的是,当一个大模型开始能够一边编程、一边观察、一边迭代自己的视觉成果时,它已经站在了一个新的起点上。




