相关性与因果性:识别伪相关以提升模型在真实环境的可用性
来源:互联网
时间:2026-06-13 07:30:09
相关性不等于因果——这句话在数据圈里都快被说烂了。但坦白讲,真正能把这两者分清楚的人,并不多。
相关性,说白了就是两个指标之间有没有“同步变动”的默契。而因果性,则代表一件事直接促成了另一件事——是真正的“因为所以”。这两者之间,隔着一道需要用严谨论证去填补的鸿沟。测算相关性几乎没有门槛,但要证明因果关系,那真的是另一回事。
这篇文章会聊三个核心问题:为什么我们总是不自觉地忽视那道鸿沟?两个变量同步变动,背后到底藏着哪几种可能性?以及,这些误区在数据科学里是怎么反复出现的?读完你就能明白,下次看到一个“有规律”的数据模式时,该先问自己哪几个关键问题。
相关性到底是什么
从定义上讲,相关性就是一个数值指标,告诉你两件事同步变动的程度有多高。
一个经典例子:每年7月,冰淇淋销量和溺亡人数同时攀升。这两个指标之间存在正相关,趋势完全一致。
Tyler Vigen 在《伪相关》这本书里收集了几百个类似的荒诞案例。比如,密苏里州家具抛光工的数量,和 Google 上“巴洛克·奥巴马”的搜索频次,竟然高度重合——你不觉得这很荒唐吗?
从数学层面来看,皮尔逊 r 值把相关性量化成一个在 -1 到 1 之间的分数:
- **1** 代表完全正相关,一个指标上升,另一个绝对按同样比例增长。
- **-1** 代表完全负相关,两者走势始终相反。
- **0** 表示毫无关联。
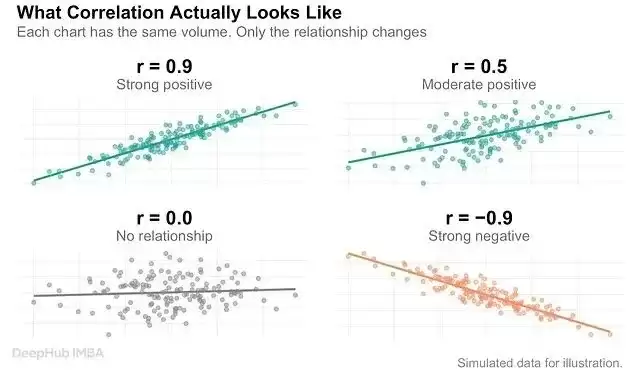
但数学只能告诉你“现象存在”,至于“为什么存在”——它一个字都不会说。
两件事能一起变动的三个原因
当我们观察到 A 和 B 总是同时发生时,其实只有三种可能的解释。
**第一种:A 导致 B。**
这是最直接、最朴素的因果关系。吸烟引发肺癌,运动拉低静息心率——这些结论背后是严谨的实验论证,作用方向明确,单向不可逆。
**第二种:B 导致 A。**
反向因果——这玩意儿迷惑性极强。你想想,医院里聚集的病患密度远超其他场所。那是不是说“医院让人致病”?当然不是。真正的原因是:生病的人才会去医院。相关系数没有骗人,但你解读的方向反了。
还有一个更隐蔽的例子。抑郁症患者群体的追踪数据表明,他们通常运动量很少。早些年有媒体据此得出结论:“锻炼能预防抑郁”。但后续的研究揭示了一个更复杂的机制——抑郁症发作本身就会拖垮患者的行动力,让他们被迫放弃运动。这两个变量互为因果,如果只凭观察到的数据就臆断一条单向作用链,那肯定会出错。
**第三种:第三个因素同时导致了 A 和 B。**
这才是现实世界中最常见的陷阱,学名叫“混杂变量”。A 和 B 之间根本不存在直接联系,它们都是某个“隐身”因素的产物。
回到冰淇淋销量和溺水人数的案例。
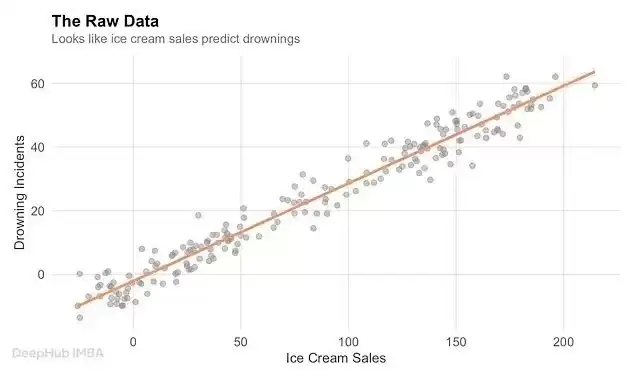
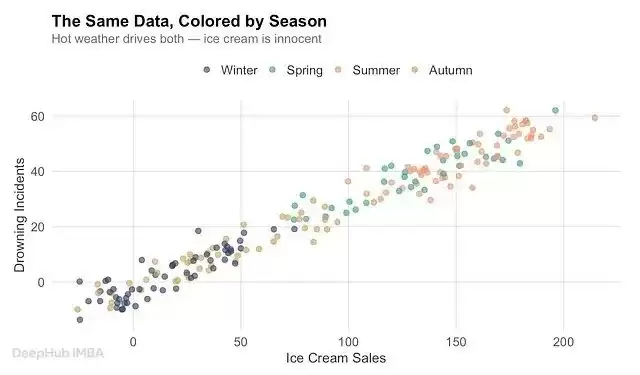
高温天气:既推动了大家去游泳的频次,也拉动了冰淇淋的消费。吃冰淇淋不会导致溺水,气温才是那个真正的幕后推手。
另一个例子:巧克力消费大国,往往也是诺贝尔奖得主大国。这两者高度相关,但巧克力不会产出诺贝尔奖得主。真正的原因是国家财富——富裕国家能支撑资金充足的高等教育系统,同时,国民也有钱消费高档巧克力。钱,同时催生了这两件事。
欧洲的鹳鸟数量和出生率也一样。鹳鸟更喜欢在农村地区筑巢,而农村地区的生育率本来就更高。所谓“鹳鸟送子”的童话,不过是数据巧合。
一旦建立起对混杂变量的敏感度,你会发现它们无处不在。数据科学实践中,经常遇到在训练数据上表现完美的模型,一放到线上环境就完全没有效果——根源往往就在这里。
第三事物测试
所以,当你看到一个可疑的相关性结论时,第一个要问的问题就是:有没有第三个因素,同时在拨动这两个指标?
举个例子:
- 每天吃早餐的学生,在校表现更好。背后的第三个因素可能是“家庭收入”——经济宽裕的家庭能保证规律饮食,也愿意投入更多教育资源。
- 随身带打火机的人,确诊肺癌的概率更高。第三个因素是“吸烟”——烟民有带打火机的习惯,但打火机本身不是致癌物。
- 现场停放的消防车越多,火灾造成的破坏往往越惨重。第三个因素是“火势”——大火必然要求增派车辆,并伴随严重破坏,消防员并没有烧毁建筑。
统计学中,这叫“控制变量”。如果能把样本锁定在同等收入的家庭、或同等规模的火情中去观察,最初的相关性是否还站得住脚,马上就能见分晓。它可能是实打实的因果,也可能只是共用了一个底层驱动力。
但这个方法有个硬伤:你只能控制那些你已经想到要去测量的变量。那些你完全没意识到的混杂因素,始终处于隐身状态。这正是为什么观察性研究永远挂着“免责声明”,而实验不需要。
为什么每次都会弄错
几千万年的进化,把人类大脑打磨成了一台因果推演机器。
设想一下我们的远古祖先:某天吃下一颗红浆果后,肠胃剧痛。大脑会立刻建立“红浆果等于毒药”的等式,绝不会等到同行评审结果出来再作决定。毕竟,漏判一个真实的因果信号可能直接丢命。这种压力逼得我们不得不在任何场景——哪怕是纯粹的巧合中——强行提取因果关联。
这种避险本能用来对付毒浆果绰绰有余,但面对现代数据仪表盘,就抓瞎了。看到图表上两条曲线亦步亦趋,大脑会不受控制地去拼凑解释。面对未知的“为什么”,大脑会本能地感到焦虑,于是随手抓一个看似合理的因果故事来填补空白。而最理智的回答,其实往往是“暂无定论”。纳西姆·尼古拉斯·塔勒布把这种现象总结为“叙述谬误”——人们总有强行把随机事件套入因果故事的冲动。
底层心理学成因叫“空想性错觉”:在散乱无序的数据中,强行看出意义。捕捉模式的直觉冲在前头,编故事的本能紧随其后。
民间偏方就是这种思维方式的典型产物。喝冰水碰巧嗓子疼,头发没吹干出门刚好感染风寒——因果联系压根不存在。等后人想起来要验证真伪时,荒诞的叙事已经流传了好几代。
而且,现在数据团队每天犯的错误,和这些偏方本质上是一模一样的。
在数据科学中,我们在哪里看到这种情况
业务场景中,类似的例子比比皆是。
比如,算法模型发现频繁联系客服的用户群体,流失风险最高。业务部门一看,直接切断了这部分用户的客服入口。结果呢?流失率反而加速飙升。原因很简单:对产品不满意,既引发了客诉,也导致了最终退订。电话求助是危机暴露的信号,不是源头。
再比如,产品团队发现使用深色模式(Dark Mode)的用户留存率偏高。于是果断上线“强插屏”,引导新注册用户开启该功能。结果大盘留存数据毫无起色。为什么?因为那批高留存用户本身就是重度活跃用户,他们才有动力去翻找并开启深色模式。强行推给所有人,只会增加用户的反感。
营销团队也犯过同样的错:对比数据后发现,收到高频推销邮件的客户,生命周期价值更高。于是拉高发信频率,结果退订量暴涨。真相是,那批高价值客户本身就对品牌有极强的粘性,粗暴增加邮件量只会触怒边缘群体。
三次决策失误,遵循的是同一套陷阱:观察到 A 与 B 相关,武断认定 A 是 B 的成因,然后盲目干预 A 试图扭转 B——最终没有任何改善。
如果客观条件不允许跑实验,可以借助工具变量、双重差分法或断点回归这类近似手段。它们的核心诉求是:在无法硬控变量的局限下,尽可能模拟真实实验的推演逻辑。
但绝大多数时候,不需要这么复杂的工具。问清楚几个问题就够了。
三个问题
当你盯着一组相关性数据,隐约觉得有规律可循时,先拿下面三个问题盘一盘。
**第一,方向能反过来吗?**
下结论“A 导致 B”之前,先问问自己:B 是不是 A 的原因?生病的人去医院,而不是医院让人致病。抑郁症患者往往会停止锻炼——是抑郁症驱使了行为改变,不能反推。高活跃度用户会点开收件箱里的每一封推送,是自身粘性造就了点击模式,而不是发信频率起了作用。
**第二,存在第三件事吗?**
排查一下,是否有某个尚未被测量的因素,在同时牵动 A 和 B?收入水平、季节更替、地域差异、历史行为数据——这些都是常见的“元凶”。混杂因素往往藏在早期没人想到去埋点收集的字段里。一旦揪出那个同时支配两端的第三个变量,你手里的结论就从“因果关联”退回到了“待验证的假设”。
**第三,这符合物理常理吗?**
抛开那些听起来顺耳的故事,认真想一想:A 诱发 B 的真实世界传导机制是什么?是否存在一条能步步追溯的事件链条?巧克力不会在大脑中激活诺贝尔奖的通路。尼古拉斯·凯奇的电影不会导致泳池溺水。如果一种解释需要靠“盲目信仰”才能被接受,那因果关系多半根本不存在。
围绕任何数据模式做决策前,这三个问题必须拿到明确答案。但凡有一丝站不住脚的地方,立刻打回去重做审查。
总结
混淆相关性与因果性,是数据科学、医疗诊断乃至日常推理中,最常见且代价高昂的认知偏差。
几个核心原则收尾:
- **相关性只负责标定指标间的同步变动紧密程度。** 它告诉你“某事正在发生”,但不告诉你“为什么发生”。
- **两件事挂钩的内部逻辑只有三条:** A 促成 B,B 促成 A,或是不可见的 C 操盘了这一切。
- **混杂因素驱动是野生数据中最泛滥、也最隐蔽的陷阱。** 遇到可疑的相关性,追问那三个问题。
- **你只能控制你已经想到去测量的变量。** 那些你错过的因素,永远处于隐身状态。
- **确立因果关系的唯一铁证是跑实验。** 随机化能抹平那些你甚至不知道该去寻找的干扰项。
找相关性毫无门槛。证明因果关系,需要下苦功夫。而看懂数据模式背后的真实逻辑,才是我们真正该花力气去做的事。





