
HPC-Ops – 腾讯混元开源的工业级高性能大模型推理算子库
HPC-Ops是什么
今天来聊一个挺有意思的开源项目——HPC-Ops。这是腾讯混元AI Infra团队开源的一套工业级高性能大模型推理算子库,覆盖面相当全:Attention、MoE、GEMM、采样以及通信融合这些核心模块,它都原生支持,而且直接兼容BF16、FP8以及混合精度。它不是那种实验室产品,而是已经支撑了腾讯混元大规模生产级推理服务的实战级工具。
最亮眼的地方在于,它专门针对NVIDIA H20这类GPU做了深度优化。通过动态调度和算子融合,端到端的QPM能提升30%以上,多项性能指标显著超越vLLM、FlashInfer、SGLang这些主流基线——不是一点点,而是有点“降维打击”的味道。
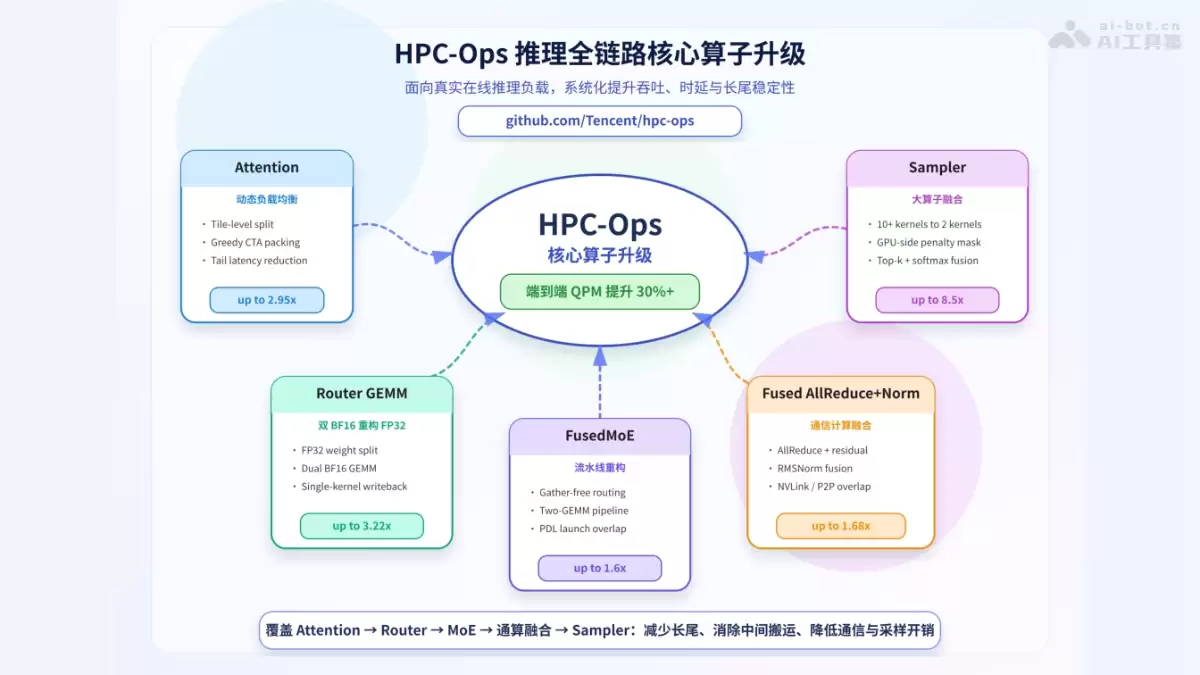
HPC-Ops的主要功能
来看看它到底做了哪些事:
- :针对线上推理中长短请求混排的典型场景,它在运行时采用Tile级的动态任务调度,实现CTA级的负载均衡。长文本场景下,加速比最高能达到2.95倍。
动态 Attention 调度
- :这是个巧妙的设计——用两个BF16 GEMM组合来模拟FP32精度的计算。离线拆分权重,推理阶段融合成单个Kernel,既满足了数值敏感场景对高精度的需求,又用上了Tensor Core的高吞吐,两边都没耽误。
Router GEMM
- :把路由索引、Gate-Up GEMM、激活量化、Down GEMM、Top-K加权聚合这五个阶段,重构为一条无气泡的流水线。说白了,就是把显存搬运和内核启动的开销几乎完全消除。
FusedMoE
- :把跨GPU通信、残差相加和RMSNorm归一化深度融合到一起。基于NVLink多播和P2P技术,实现了通信计算一体化——这在张量并行场景下是真正的瓶颈突破。
Fused AllReduce+Norm
- :把重复惩罚、温度缩放、Top-K、Top-P、Softmax、随机采样等10多个Kernel,直接融合成2个CUDA Kernel。补齐了推理末端后处理这个经常被忽略的短板。
Sampler 大算子融合
- :支持专家并行和分组专家矩阵乘,原生支持per-tensor和block-wise的FP8量化,专门为MoE模型的高效推理而设计。
GroupGEMM FP8
HPC-Ops的技术原理
如果只看功能列表,可能会觉得“不就是融合嘛”。但深入技术实现的细节,会发现背后有不少值得细品的巧思。
Attention 动态调度:打破静态束缚
传统的静态 split-kv 在处理长短请求混排时,效率很不理想——长请求的CTA负载特别重,其他CTA只能干等。HPC-Ops的做法是:把所有请求按统一的Tile粒度拆分,然后用全局的Tile总量来均衡分配各CTA的任务规模,再通过贪心装桶算法实现极致均分。
具体来说,它设计了一个“Task Assign”模块,在每次推理前生成专属的任务映射表。每一层的Attention Kernel按照这个表精准领取任务,最后用Combine Kernel合并结果。从请求到CTA、再到最终合并,全程实现了真正的负载均衡。
Router GEMM 双 BF16 模拟 FP32:精度与速度的平衡术
MoE路由这类场景对精度极其敏感,直接用BF16可能不够,但FP32又慢。HPC-Ops的解法是:离线把FP32权重拆分成高位BF16和低位残差BF16(缩放因子设为1/256)。推理时执行两次BF16 Tensor Core GEMM并做线性组合,激活值全程保持BF16。
更厉害的是,双路计算被融合到单一Kernel中——输入只搬一次,中间结果存在双寄存器累加器里,Epilogue阶段用一次FMA修正后就写出。全程没有HBM往返开销。误差仅为TF32的1/36,性能是cuBLAS FP32的3.22倍。
FusedMoE 流水线重构:消除一切气泡
传统MoE的执行流程有5个阶段,每个阶段之间都有显存搬运和Kernel启动的开销,就像流水线上有空档。HPC-Ops的做法是:路由阶段用共享内存分块统计,为每个专家预留连续显存输出区间;Gate-Up GEMM直接通过路由索引读取原始输入,省掉了独立的Gather搬运。
它的设计思路是把Warp Specialization取消掉,由同一个Warp Group完成数据搬运和计算。这样一来,访存延迟被掩盖的逻辑就不再是CTA内的软件流水线,而是升级为跨CTA的硬件调度。配合PDL技术,整个链路被串联为无气泡执行。
Fused AllReduce+Norm 通信计算融合:打通瓶颈
在张量并行分布式推理中,通信往往是最大的瓶颈。HPC-Ops基于CUDA multimem和P2P技术,封装了一个NVLink原生的、一体化的操作:RMSNorm(AllReduce(x) + residual, weight)。
针对不同场景有两个版本:高吞吐版本依托NVSwitch多播机制,适合Prefill场景;低延迟版本基于Lamport P2P机制,通过PDL实现双Kernel重叠执行,适合Decode场景。相对FlashInfer,最高提速1.68到1.76倍。
如何使用HPC-Ops
如果你手头正好有一台配备NVIDIA SM90架构GPU的服务器(比如H20),上手HPC-Ops其实很直接:
- :确保系统安装了Python 3.8+、CUDA 12.8+和C++17编译器。
硬件环境
- :从GitHub把HPC-Ops的源代码仓库拉到本地。
克隆仓库
- :进入项目目录,执行编译打包命令,生成wheel安装文件。
编译打包
- :用pip命令安装生成的wheel文件。
安装部署
- :在Python脚本中导入hpc模块。
导入模块
- :根据目标算子类型,准备好符合精度要求的输入张量和配置参数。
准备数据
- :调用对应算子的Python API(如Attention、FusedMoE、Sampler等)执行推理。
调用算子
- :参考tests目录下的测试脚本,验证算子的正确性和用法。
测试验证
- :通过提供的Python API,可以无缝嵌入vLLM、SGLang等主流推理框架。
框架集成
- :用benchmark目录下的脚本,在目标硬件上跑性能复现和对比测试。
性能基准
HPC-Ops的核心优势
前面说了很多技术细节,现在来总结一下它真正的价值在哪:
- :它不是只优化某一个算子,而是覆盖了Attention → Router → MoE → 通信融合 → Sampler的整条推理链路。端到端的QPM提升了30%以上,而不是那种“单个算子好看、整体没变化”的伪优化。
端到端全链路优化
- :在长短请求混排的真实业务负载下,运行时Tile级动态调度加上贪心装桶算法,让长文本加速最高达到2.95倍,端到端QPM提升了17%。长尾延迟问题被有效控制。
动态负载均衡根治长尾
- :用双BF16组合模拟FP32精度,误差仅为TF32的1/36,性能是cuBLAS FP32的3.22倍。数值敏感和算力释放两者兼得。
高精度 Router GEMM
- :FusedMoE把5个阶段重构为单一执行链路,消除了一切不必要的开销。相对vLLM和SGLang,提升了1.2到1.6倍。
MoE 无气泡流水线
- :Fused AllReduce+Norm作为NVLink原生的一体化操作,真正打通了张量并行的性能瓶颈。
通信计算深度融合
HPC-Ops的项目地址
- :https://github.com/Tencent/hpc-ops
GitHub仓库
HPC-Ops的同类竞品对比
说到这里,可能有人会问:那和FlashInfer比,到底差在哪?来看一份比较直观的对比:
| 维度 | HPC-Ops | FlashInfer |
|---|---|---|
项目性质 |
腾讯混元开源并长期维护的工业级算子库,经大规模生产验证 | 社区驱动的开源高性能算子库,被vLLM、SGLang等广泛集成 |
Attention 动态调度 |
运行时Tile级动态任务分配+贪心装桶,长文本最高加速2.95x,混合batch加速1.59x~1.76x | 主要静态split-k调度,均匀长度负载稳定,长短混排时存在CTA级长尾延迟 |
Attention 标准性能 |
BF16 Prefill最高1.33x、Decode 2.22x;FP8 Decode 2.0x(相对FlashInfer) | 作为社区主流基线表现优异,但动态负载和稀疏场景下有优化空间 |
Sparse Attention |
FP8块稀疏Prefill,预计算块掩码跳过无关KV Tile,最高3.16x | 支持块稀疏,但HPC-Ops在FP8精度下的稀疏调度与Tile量化更精细 |
MoE 融合 |
FusedMoE将5阶段重构为无气泡流水线,领先1.2x~1.6x | 基础MoE支持,无全模块流水线融合,存在多阶段搬移开销 |
Router GEMM |
独创双BF16模拟FP32,误差仅为TF32的1/36,性能3.22x | 无专用优化,需依赖cuBLAS FP32或接受精度折损 |
通信计算融合 |
Fused AllReduce+Residual+RMSNorm封装为NVLink原生一体化操作,最高1.68x~1.76x | 基础通信算子,无原生融合实现 |
HPC-Ops的应用场景
最后,什么样的人应该关注这个项目?
- :如果你的业务是长短请求混排的,动态Attention调度和Sampler融合能显著降低长尾延迟,效果立竿见影。
高吞吐在线推理服务
- :FusedMoE对DeepSeek-V3、Qwen3-235B这类MoE模型做了深度优化,在TP/EP并行场景下能明显提升推理效率。
MoE 大模型推理
- :Fused AllReduce+Norm打通了多卡通信瓶颈,特别适合单节点多GPU的大模型部署。
张量并行分布式推理
- :Router GEMM用BF16的算力实现了FP32的精度,对MoE路由、稀疏Attention这类数值敏感的模块来说,是真正的实用工具。
精度敏感推理




