
MiniGPT-v2多模态
随着GPT-4V这类多模态模型的发布,一个趋势已经相当明朗:具备强大图像识别能力的大语言模型,正在成为下一代AI发展的核心方向。这不,最近来自KAUST和Meta的研究团队,就给他们的明星项目来了次重磅升级——MiniGPT-4正式进化到了MiniGPT-v2版本。
论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
代码:https://github.com/Vision-CAIR/MiniGPT-4
这次升级的核心目标很明确:打造一个更强大的统一接口,来流畅处理各种视觉-语言任务。研究团队提出了一项关键创新:在训练模型时,为不同的任务引入独特的“识别符号”。这就像给每个任务发了一张专属身份证,模型能轻松区分指令意图,从而显著提升针对每个任务的学习效率和最终表现。
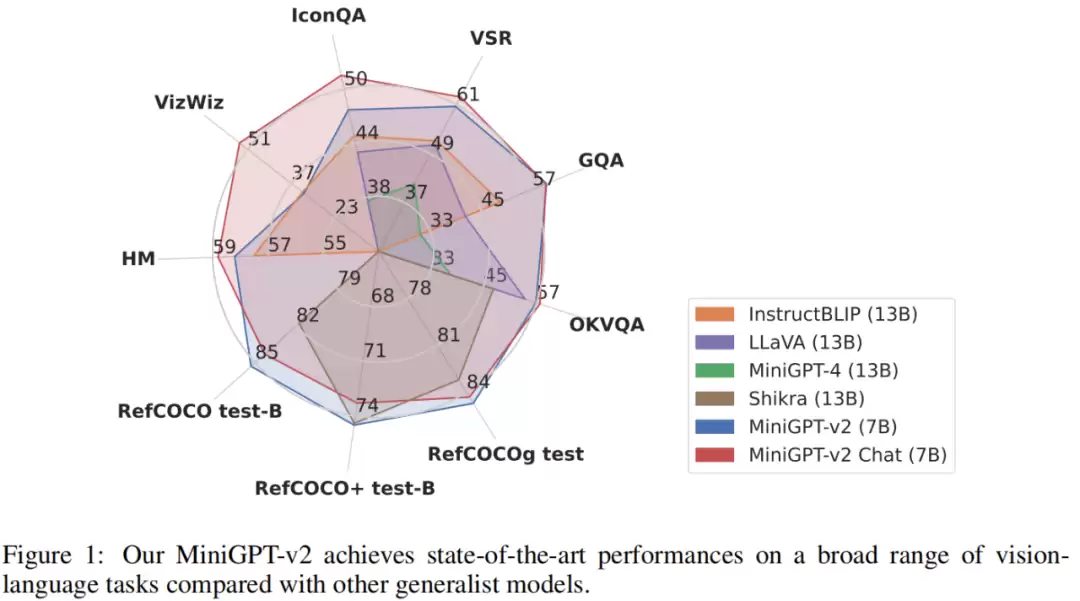
效果如何呢?为了全面评估MiniGPT-v2,研究团队在多种视觉-语言基准上进行了广泛测试。结果相当亮眼:与之前的通用模型,如MiniGPT-4、InstructBLIP、LLaVA和Shikra等同台竞技时,MiniGPT-v2在多项指标上达到了领先或相当的水平。举个例子,在VSR基准测试中,MiniGPT-v2的成绩比MiniGPT-4高出21.3%,比InstructBLIP高出11.3%,比LLaVA也高出11.7%。这个提升幅度,足以说明其架构创新的有效性。
架构解析:三部分如何协同工作
MiniGPT-v2的模型架构清晰明了,主要由三个核心部分组成:视觉主干网络、线性投影层以及大型语言模型。
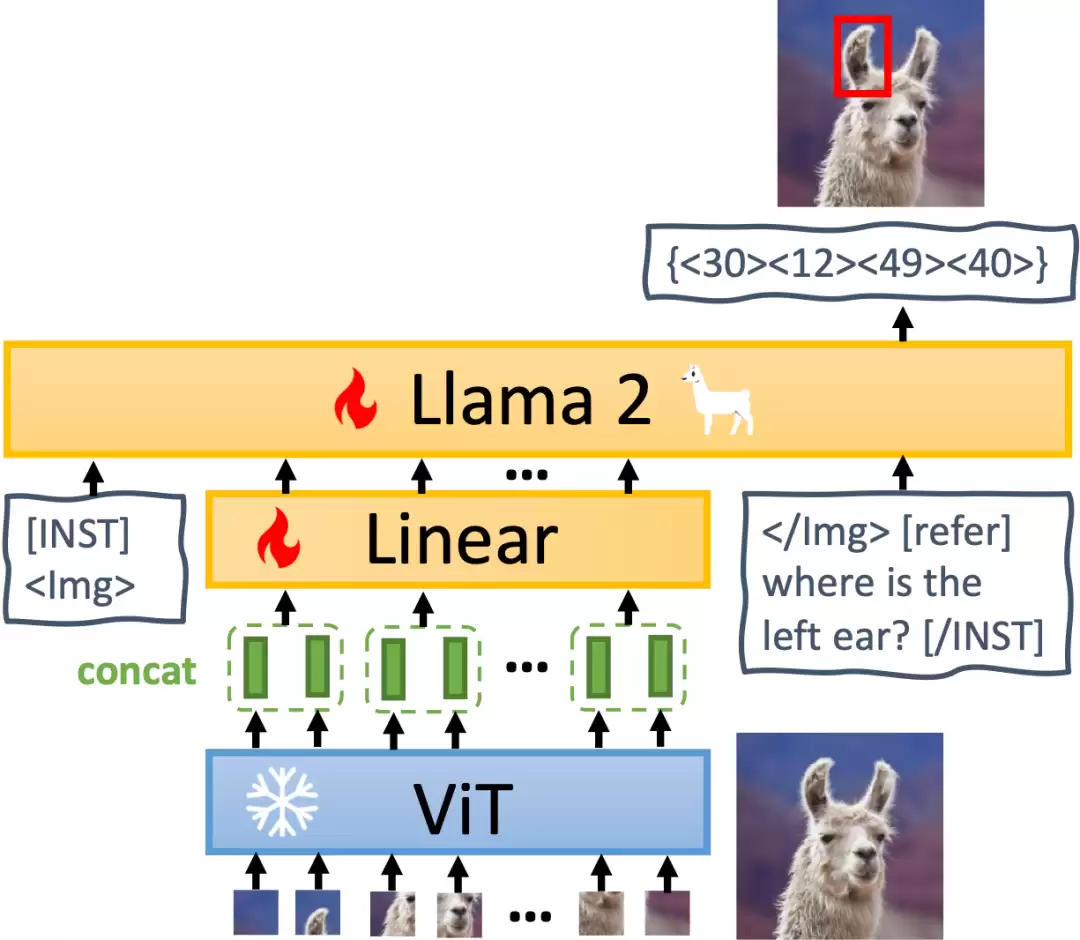
视觉主干:冻结的EVA模型
模型采用了EVA作为视觉主干。在训练过程中,这部分参数是冻结的,即保持不动,这能有效提升训练稳定性并节省计算资源。输入图像的分辨率被统一为448×448,并且通过插入位置编码,模型具备了处理更高分辨率图像的潜力。
线性投影层:效率提升的关键
这一层的任务,是将视觉主干提取的所有特征“令牌”,映射到语言模型的空间中。但这里有个实际问题:对于高分辨率图像(比如448×448),直接投影所有视觉令牌会产生极长的序列(例如1024个令牌),这会严重拖累训练和推理的效率。
团队的解决方案很巧妙:他们简单地将嵌入空间中相邻的4个视觉令牌拼接起来,然后将其共同投影到语言模型特征空间中的单个嵌入里。这一招,直接将视觉输入令牌的数量减少了四倍,效率提升立竿见影。
大型语言模型:统一的任务接口
MiniGPT-v2选择了开源的LLaMA2-chat(7B版本)作为语言模型主干。在这里,语言模型被定位为处理各种视觉-语言输入的统一接口。研究直接利用LLaMA-2的语言令牌来执行各类任务。对于那些需要输出空间位置的视觉基础任务(比如物体定位),模型被直接要求生成边界框的文本坐标来表示位置,实现方式非常直观。
得益于这种设计,MiniGPT-v2不仅能识别图片中的物体,还能精准地标注出不同物体所在的区域,实现了视觉与语言的细粒度对齐。
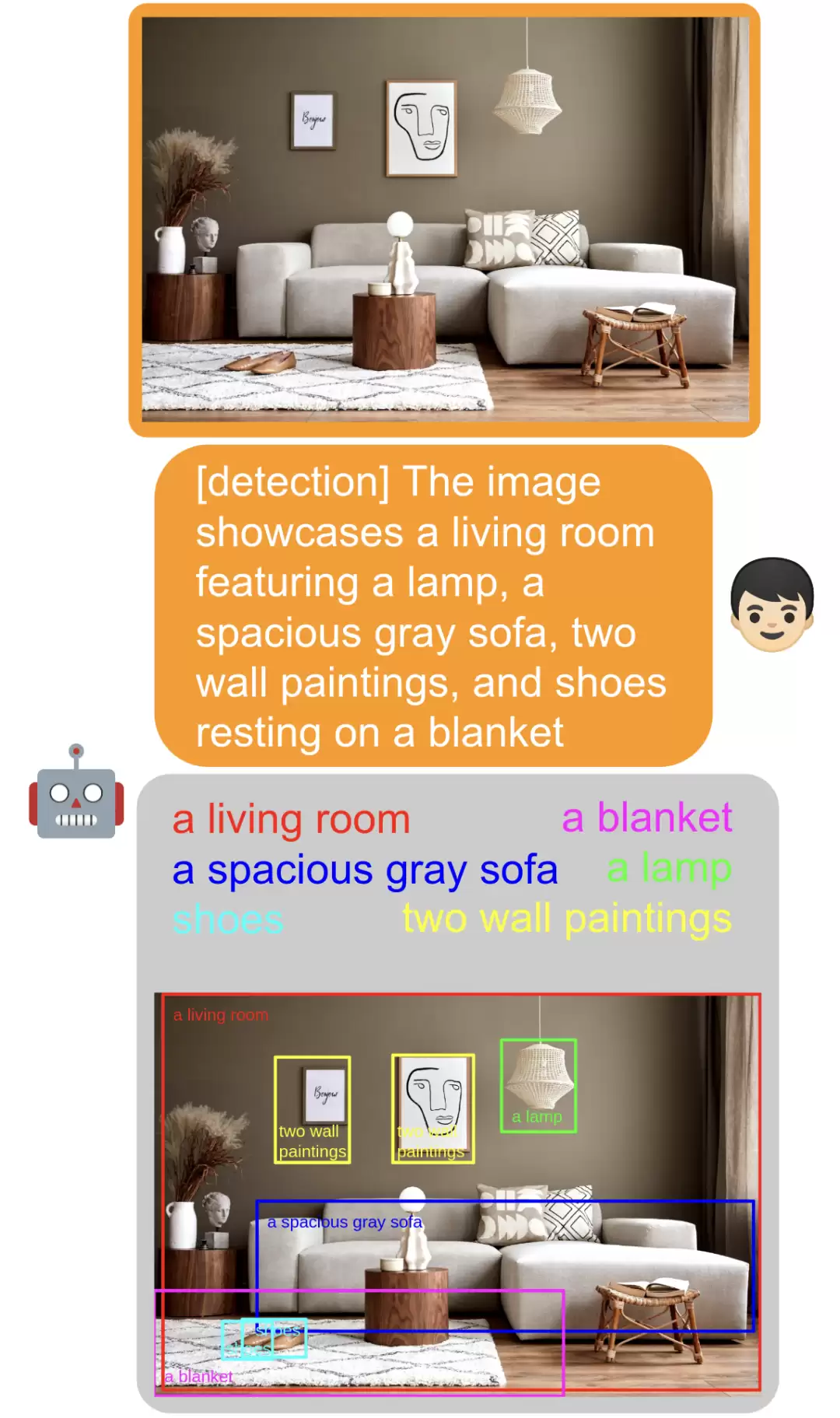
更有趣的是,你甚至可以不加任何任务识别符号,直接像聊天一样和图片进行对话,模型同样能理解并给出合理的回应,这体现了其强大的泛化理解能力。

目前,MiniGPT-v2已经提供了免费的在线Demo供用户体验和测试。对于开发者和研究者而言,这无疑是一个深入了解多模态模型前沿进展的绝佳窗口。




