
“Agent的最后一场考试”来了:最强模型得分率仅8.6%,Claude Code直接挂零
如今,AI 模型看上去越来越强了:棋类游戏能赢顶尖选手,在主流 benchmark 上不断刷新 SOTA。但为什么就是没法真正帮人类干活?
由加州大学伯克利分校牵头、联合 250 余位行业专家组成的研究团队,给出了这个问题的答案:“
问题不在 AI 本身,而在评估体系
针对这个问题,研究团队提出了新的基准
Agents’ Last Exam(ALE)
能力门槛
难度前沿

这场考试的结果也很直接:主流模型虽然能在传统 benchmark 上拿高分,在 ALE 最难层级中,
平均完整通过率则是 2.6%
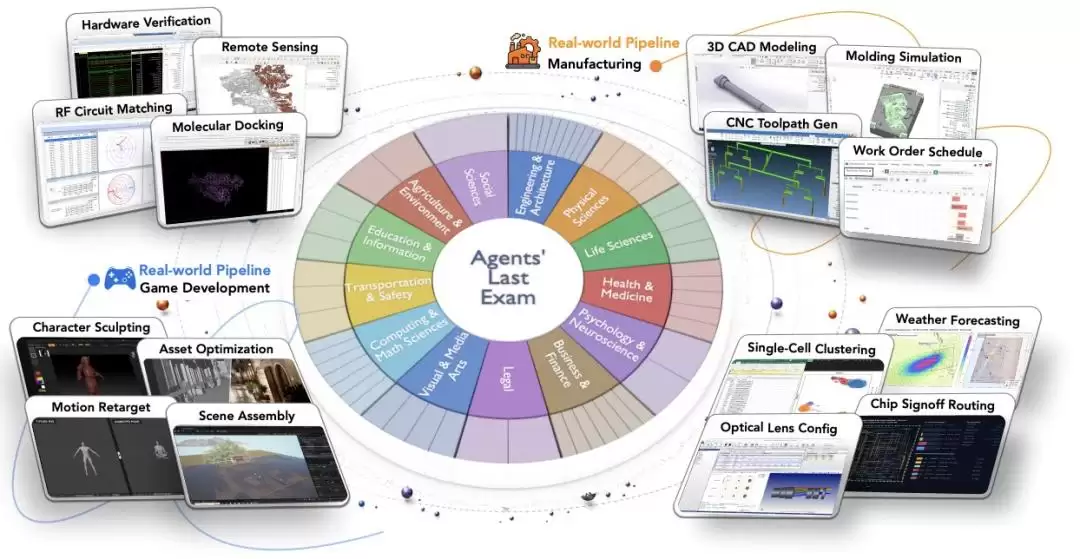
图|Agents’ Last Exam 涵盖了大量不同类型的专业任务和真实工作流程。
“最后一场考试”考什么?
“最后一场考试”考什么?
Agents' Last Exam(ALE)
长期、具有经济价值
为了测试 AI 能不能像人一样在电脑上完成真实工作,研究团队
收集了 1490 个任务
制造、法律、医疗、视觉媒体
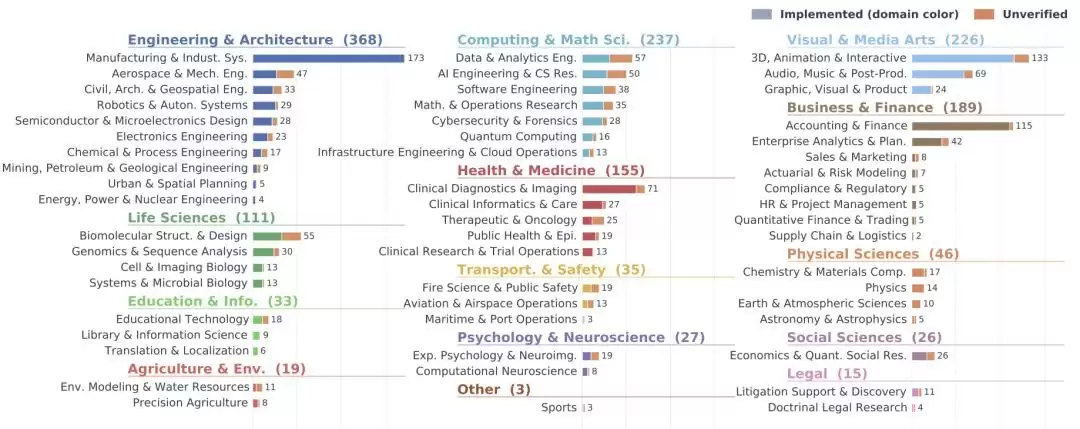
图|ALE 分类体系下 1490 个任务实例的分布情况
相比常见的问答或短流程基准,这类任务对 Agent 提出了更高的要求。研究团队把这类 Agent 称为
Generalist Computer-Use Agent(GCUA)
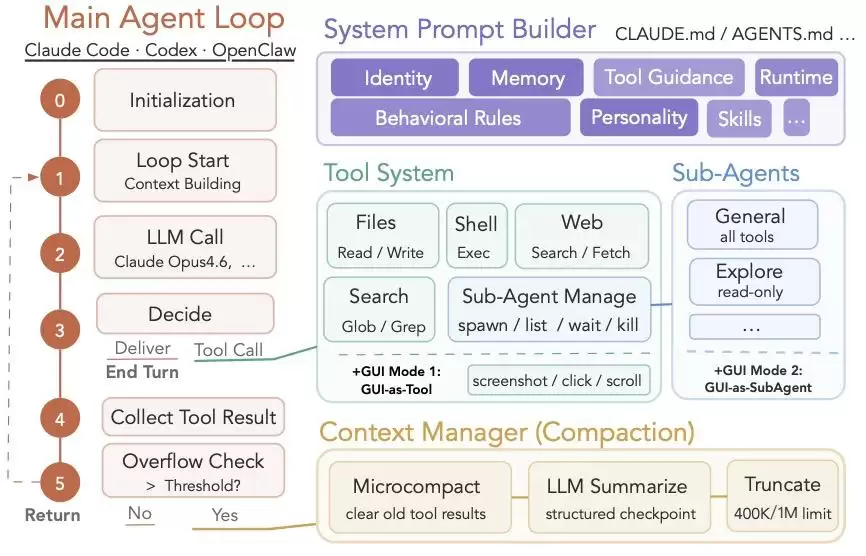
图|典型的 GCUA 框架结构。
为了测试这些对象的真实能力,ALE 提供了一整套可以执行和评分的任务环境。具体执行时,任务脚本会负责加载任务、准备环境和最后评分,Agent 则根据任务描述自己
观察环境
选择动作
持续执行
93.2% 的任务都能自动判分,无需人工打分

图|任务构建流程。
考试成绩怎么样?
考试成绩怎么样?
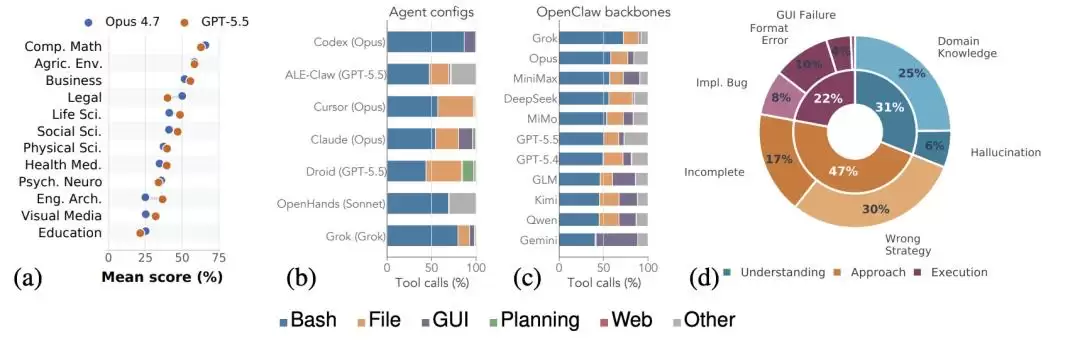
研究团队指出,如果只看最难一档的任务,当前表现最好的配置是 Codex + GPT-5.5,完整通过率也只有 8.6%;
研究团队给出的主流系统平均完整通过率则是 2.6%
研究团队列举了几个具体的失败案例。在音乐转谱任务中,需要提交总谱 PDF、MIDI 和界面截图,但 AI 只导出了 MIDI 文件,最终拿了 0 分。注塑仿真任务中,AI 在 Moldex3D 中完成了仿真并导出结果,但没能稳定提取关键数值,最终得分为
0.4762
0 分
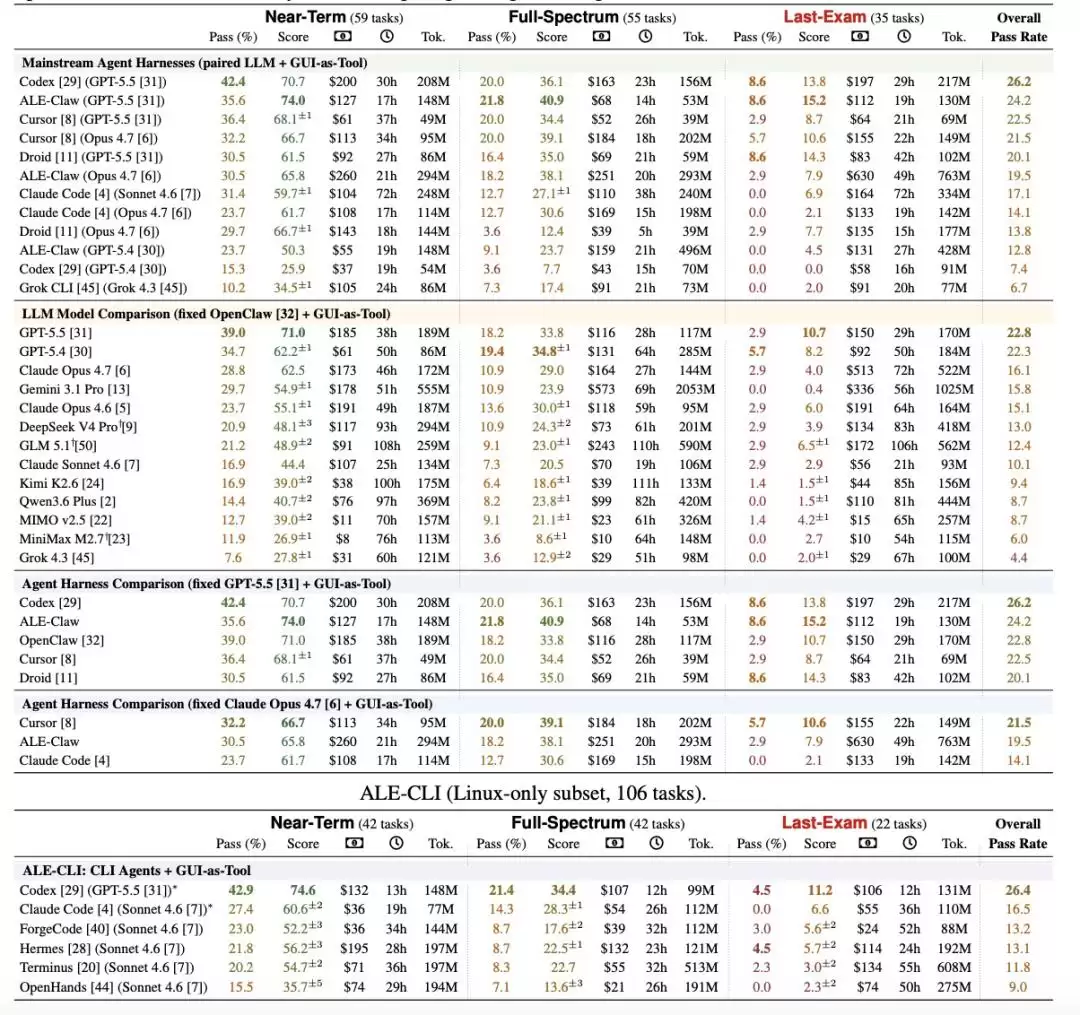
图|ALE 的主要结果。
图|实验分析概览。
研究团队随后对失败原因进行了分类。以
Claude Code + Opus 4.7
31%
47%
22%
领域知识
执行能力
研究团队还比较了模型和 agent 框架的影响。结果显示,
更换模型带来的结果差异,要明显大于更换 agent 框架。
18 个百分点
5 到 6 个百分点
不足和未来方向
不足和未来方向
研究团队也指出,ALE 以 SOC 2018 为职业分类骨架,覆盖的主要是软件型、数字化的专业工作。现阶段,任务也主要运行在 Linux 或 Windows 虚拟机中。
此外,ALE 在不同领域上的覆盖也并不均衡。有些方向任务覆盖较多,有些方向则很少。比如,能源与核工程只有
4 个
5 个
15 个。
不过,研究团队认为, ALE 是一个




