
都 2026 了,到底谁还信 AI 榜单?
先抛几个问题,不妨一起想想:
- AI 评测现在还能客观反映模型的真实能力吗?
- 测评结果,真的是决定 AI 能不能落地的关键吗?
- 像通用大模型这种东西,放到数据库行业里,到底行不行?
1. AI 落地的瓶颈:不可计算
最近圈子里都在讨论
“AI 评测坐标系坍塌”
AI 这东西,目前落地的真正瓶颈,压根不是什么
“智力不够”
“不可计算”
“未知”
“不能”
1.1 “未知” 比 “不能” 更可怕
“不能”,指的是技术的上限。
“未知”

插一句,这就好比你是技术负责人,知道某个 AI 生成的逻辑有
1%
1%
一个百分百的风险冲击波
正是这种由于缺乏“边界感”而产生的决策瘫痪,逼着我们赶紧去建一套新的坐标系。
1.2 为什么 AI 选型陷入“决策黑盒”?

传统的 AI 选型,为什么越来越像走进一个“决策黑盒”?说到底,无非是三大困境:
- :到底该测哪些方面,心里没谱。
不知道怎么测
- :想模拟一个工业级的测试场景,成本太高了——程序开发成本高,数据准备成本更高。
没成本测
- :茫茫多的模型,哪个才跟自己的场景最匹配?两眼一抹黑。
信息差
那么,怎么才能击穿这个黑盒?
2. 从 Aha Moments 到“到底能不能用”

2.1 我们经历过的 AI 惊艳时刻
- ✅ 能思考
- ✅ 会写诗
- ✅ 能生图
- ✅ 能生视频
这些年,大家经历过的“Aha Moments”可真不少。看到模型会写诗、能思考、能生成图片和视频,确实让人惊艳和欢呼。但欢呼过后,真正的生产环节关心的其实很简单:
它到底能不能帮我干活?
2.2 AI 评测标准的价值
当 AI 进入生产环节的深水区,市场急需一个标准来判定“好坏”。回顾一下历史,
ImageNet

再看最近爆火的 LMArena,估值飙到了 17 亿美金。本质上,就是因为它在大模型最混乱的那段时期,直接告诉用户:谁更好用。

当然,评测榜单需要参考,但更关键的是,我们得判断 AI 能不能从“做对题”进化到“干成事”。
2.3 考试泄题与“红皇后效应”
经济学里有个古德哈特定律,说得很明白:“
当一个指标成为目标时,它就不再是一个好的指标。
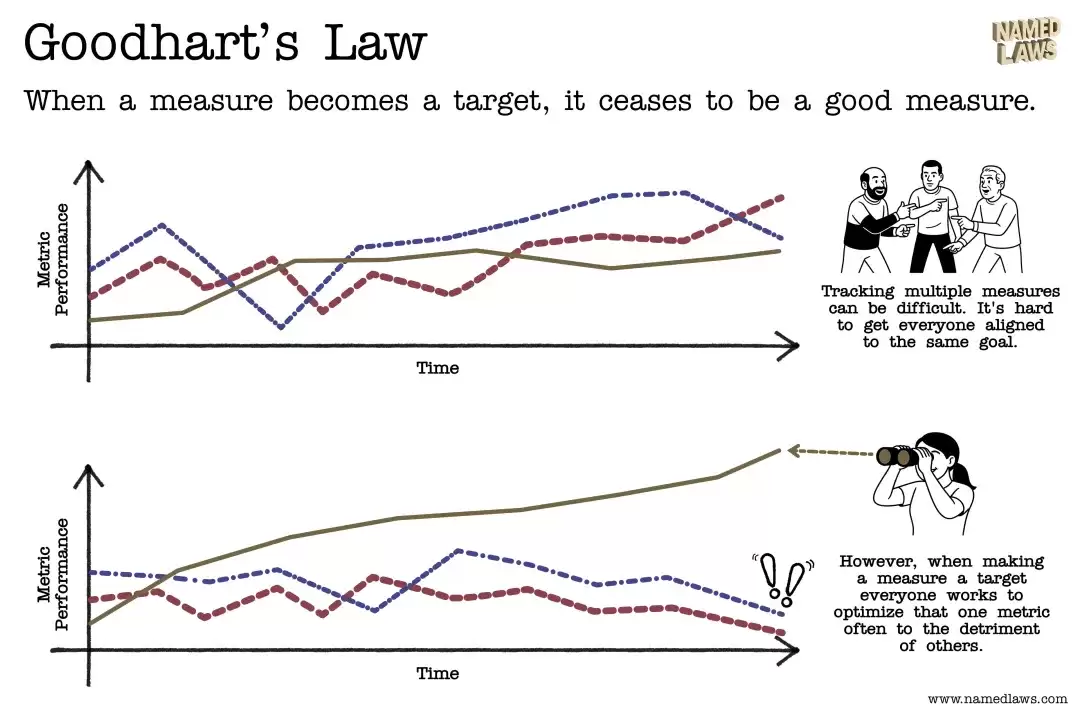
现在市面上之所以需要这么多五花八门的榜单,就是因为通用榜单已经遭遇了严重的“数据污染”。
落到数据库行业来说
所以,真正有效的测评榜单应该是那种能持续更新“题库”的。关键看模型是真的“算出了”答案,还是单纯“记住了”答案。
3. 照妖镜:SCALE
SCALE 就是这样一个持续更新、专门用来测评大模型 SQL 能力的榜单。
2025 年 12 月,SCALE 更新了生产级数据集 2.0。这可不是一次简单的题库扩容,而是一次“照妖镜”级别的压力测试。
| 模型 | SCALE 1.0 | SCALE 2.0 | 跌幅 |
|---|---|---|---|
| DeepSeek | 71.6 | 51.5 | -20.1 |
| Gemini 3 Pro | 72.0 | 64.0 | -8.0 |
结果呢?很多所谓的“优等生”直接露了马脚:
- :在旧坐标系里拿到 71.6 的高分,面对 2.0 数据集,直接暴跌到 51.5,跌幅近 30%。
DeepSeek
- :从原本亮眼的 72 分回落到 64 分。
Gemini 3 Pro
3.1 消失的分数 = AI 的“滤镜”
那些消失的分数,其实就是 AI 的“滤镜”。只有把这层滤镜挤干净,你才知道谁才是真正的“实战专家”——能帮你解决问题,而不是只会应付见过的考题。
为什么 SCALE 能有这种照妖效果?
因为 SCALE 的“题库”是基于 ActionTech 客户现场的几千条“烂数据”和真实事故构建的。这不是一次普通的考试,而是对模型的一次压力演习。
3.2 别当"冤大头",专业化 > 大而全
实测结果很有意思:在 SQL 这个垂直领域,GPT-4 Mini 的很多指标竟然优于它庞大的全量版 GPT-5 Chat!
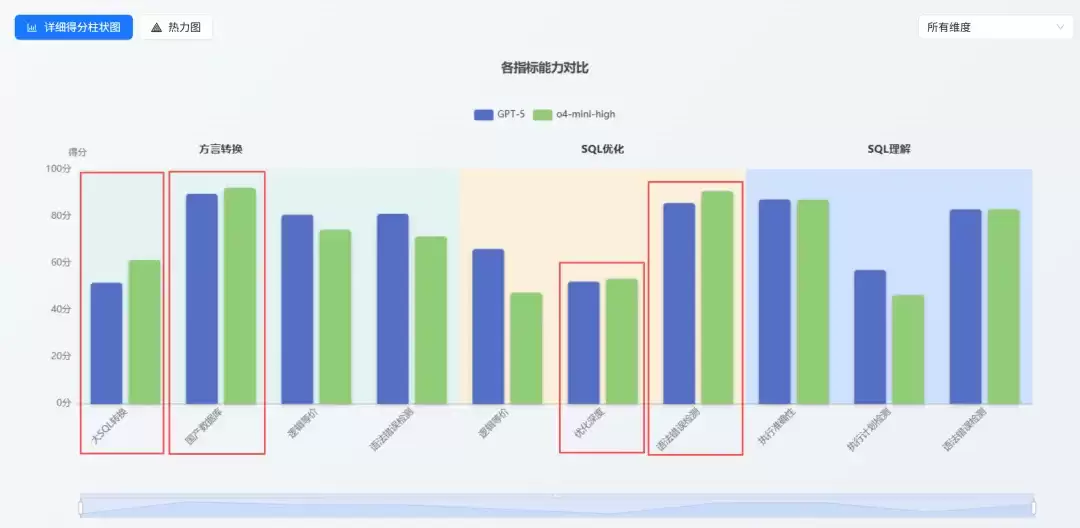
Big is not always better. Specialized is enough.
企业选型常见误区:
- ❌ 只看通用榜单 → 选最贵的模型
- ❌ 浪费大量算力成本
- ❌ 引入更多推理不确定性
对一家企业来说,如果只盯着通用榜单选了最贵的模型,那你浪费的不仅仅是算力成本,更可能是在给自己引入更多不可预测的推理风险。
3.3 从 ICU 病房到压力演习
SCALE 的数据来源
- ❌ 不是教科书例题
- ✅ 近十年真实事故代码
- ✅ 金融、电信、电力、零售等行业的真实“翻车”案例
近十年,在金融、电信、电力等核心行业,由于 SQL 缺陷引发的生产事故数不胜数——从毫秒级延迟到核心系统宕机,每一个高危场景都像是一次被按下暂停键的「高危手术」。
在这些真实故障面前,通用大模型在学术榜单上磨炼出来的“套路”通通失效。SCALE 存在的目的,不是证明模型不行,而是倒逼模型学会识别物理执行计划,学会在国产化迁移等真实场景中,精准地调整方言和决策。
3.4 三位一体的混合评估机制
评估不只看 SQL 能不能跑通,而是拆成三个维度:
- :检查语法正确性。
客观评估
- :检查逻辑等价性和方言转换能力——由多个高能力模型交叉打分。
主观评估
- (核心):针对 SQL 优化能力的综合考核。
混合评估
3.5 优化规则如何炼成?
很多人好奇,那些决定模型胜负的“优化规则”到底是怎么产生的?是专家拍脑门拍出来的吗?
绝对不是。
首先,对数据进行深度挖掘。比如,一本书里如果能挖出 10 多条优化方向。人读一本书是以天、周为单位,AI 读一本书是以分钟为单位。为此,我们构建了一套极其复杂的
“高保真生产模拟器”
高保真生产模拟器工作流程
1. AI + 资源库挖掘优化方向
↓
2. 投入模拟器压测
↓
3. 专家团队逻辑审计
↓
4. 收录进 SCALE先用 AI 挖掘潜在的优化方向,然后将这些规则投入到模拟器里做海量的自动压测。只有在那套复杂的模拟引擎中被验证为实战有效,并最终通过专家团队的严苛逻辑审计,才能被收录进 SCALE 的
“真理库”
双保险机制
- ⚙️ 模拟器:异构生产场景自动化验证




