
考场作弊检测数据集(适用YOLO系列/1000+标注)(已标注+划分/可直接训练)
考场作弊检测数据集(适用YOLO系列/1000+标注)(已标注+划分/可直接训练)
在考试监考场景中实现自动化监督与作弊行为识别,听起来很技术范儿对吧?其实这件事落地的关键,往往就卡在数据上。我们整理了一个轻量但非常实用的作弊行为检测数据集,它包含了真实考试场景中的视觉特征,可以直接用来训练YOLO、Faster R-CNN这类主流目标检测模型。上手门槛很低,拿来就能用。
先说说这个数据集的基本盘:一共1100张图片,覆盖了作弊场景下的核心视觉特征。存储路径是main/datasets,训练集和验证集已经按标准比例划分好,分别是./images/train和./images/val,不用自己再折腾数据集拆分。
标注方面,共设2个目标类别:
作弊行为
使用手机(严重作弊)
path: main/datasets
train: ./images/train
val: ./images/val
nc: 2
names: [‘作弊行为’, ‘使用手机(严重作弊)’]
背景
随着AI技术在教育管理领域渗透得越来越深,传统人工监考的短板也越来越明显:
- 监考压力大、精力有限,漏判和误判的风险一直很高。
- 大规模考试时,很难做到全覆盖和实时监控。
- 很多违规行为现在越来越隐蔽,肉眼根本捕捉不到。
作弊行为,特别是使用手机这类严重违规,对考试公平性的冲击是致命的。所以,基于视觉AI的作弊检测系统成了研究热点。而高质量、高覆盖度的标注数据,恰恰是这类模型性能提升的核心驱动力。
这个数据集正是冲着真实考试环境去的,通过图像级标注,确保了能覆盖主要的作弊动作特征,为落地部署提供了一套扎实的起点。
考试,作为社会评价体系中最经典的公平手段,它的严肃性直接关系到人才选拔和教育信任。但移动设备的普及和作弊手段的不断迭代,让传统监考模式面临前所未有的挑战:
作弊手法越来越隐蔽
监考压力持续攀升
监督成本高、效率低
说句实在话,构建智能监考系统已经不是可选项,而是教育行业发展的必然趋势。这几年,目标检测模型在安防和行为识别领域表现亮眼,给监考自动化带来了真正的突破口。
目标检测不仅能识别画面里的人,还能精准定位他们的关键行为区域,比如:
- 手部和试卷的交互动作
- 考生是否在注视屏幕之外的区域
- 是否持有电子设备
- 和邻座有没有异常互动
这些都让AI辅助监考从设想变成了现实。
但话说回来,智能监考系统的性能,很大程度上取决于训练数据的质量。目前公开的作弊场景数据并不多,特别是针对“使用手机”这类高危行为的独立标注更是少之又少。数据缺失,成了制约技术落地的一大瓶颈。
针对这个问题,这个数据集的目标非常明确:
- 提供可以直接用于目标检测训练的高质量图像数据。
- 强化对严重违规行为的精准识别能力。
- 为学术研究和工程部署提供一个统一、标准的数据基础。
- 推动教育行业的智能化转型。
借助它,研究人员和开发团队可以跳过数据准备的坑,快速搭建起作弊检测模型,大幅降低研发成本,同时提升系统的实时识别能力,为考试公平提供更坚实的技术保障。
数据集概述
| 项目 | 内容 |
|---|---|
| 数据规模 | 1100张作弊检测相关图像 |
| 任务类型 | 目标检测任务(Object Detection) |
| 标注格式 | YOLO标注格式 |
| 分类数量 | 2类 |
| 数据划分 | Train / Val 已按合理比例划分 |
数据集的路径结构很清晰:
path: main/datasets
train: ./images/train
val: ./images/val
nc: 2
names: [‘作弊行为’, ‘使用手机(严重作弊)’]两个分类标签聚焦于作弊检测的两大场景:
- :包括抄袭、传纸条、遮挡视线等多种形态,覆盖范围广。
作弊行为(cheating)
- :专门针对违规使用电子设备的场景进行强化标注。
使用手机(严重作弊)
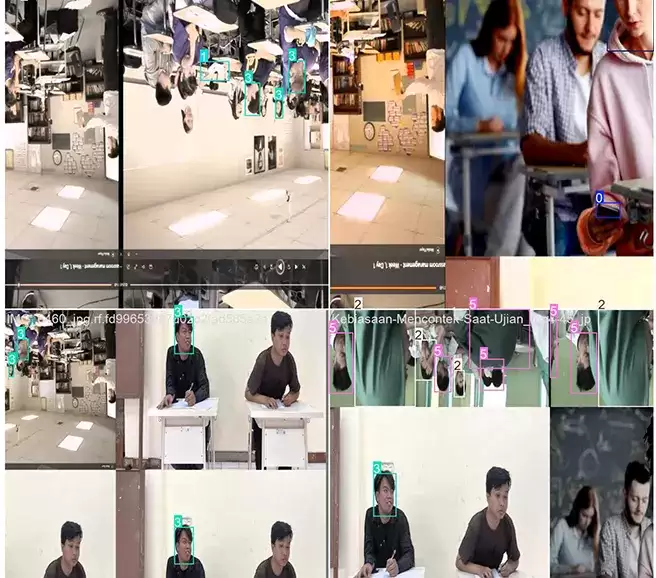
数据集详情
| 类别 | 含义说明 | 应用重点 |
|---|---|---|
| 作弊行为 | 轻中度违规行为,范围广、变化多 | 提升模型在广泛场景下的泛化能力 |
| 使用手机(严重作弊) | 严重危害公平性,高优先级检测目标 | 提高警报触发的精准度 |
图像覆盖了多样化的环境与角度:
- 教室考试、机考场景都有收录。
- 多摄像头视角:俯拍、侧拍、远距离监控一应俱全。
- 既包含多人场景,也有单人场景。
- 考虑了不同的光照条件和遮挡情况。
这些都是为了让模型在真实部署时,能稳定发挥,而不是换个环境就“水土不服”。
适用场景
这个数据集的应用方向很广,适合多种智能监考系统的研发:
- 线上/线下考试的实时作弊检测。
- 职业资格考试、高校考试的监考辅助系统。
- 行为风险识别与违规记录管理。
- 视频流监控分析,甚至能扩展到时序动作跟踪。
换句话说,它可以和现有的CCTV、校园摄像头等生产环境无缝结合,不需要太大改动。
目标检测
为了方便直接上手,数据集默认支持YOLO系列模型。你可以直接把数据加载进来训练,比如这样:
yolo train model=yolov8s.pt data=main/datasets/data.yaml epochs=100 imgsz=640当然,如果你熟悉其他模型,也没问题。它可以用于:
- Faster R-CNN / Mask R-CNN
- SSD、DETR等结构
- 结合时间序列的行为识别
- 轻量化部署(比如MobileNet + TFLite / Ascend)
模型训练完成后,就能实现
自动告警 + 框选违规区域
结语
作弊行为检测,是教育公平体系建设里绕不开的一环。这个数据集虽然体量不算特别大,但实用性和扩展能力都不错,可以作为AI监考系统研发的一个高效起点。
基于视觉AI的作弊检测技术正从简单的屏幕监控、人工复查,逐步走向自动化、实时化和精准识别。这个数据集的目标,就是为研究者和开发者提供一套轻量但高价值的训练材料,让智能监考系统能更好地识别作弊动作,尤其是使用手机这类严重违规行为。
展望未来,随着数据规模继续扩大、多模态信号融合(比如姿态识别、手部跟踪、声音探测)以及模型轻量化技术的演进,AI监考系统将更贴近真实场景:更强的场景泛化能力、更低的误报率和漏报率、更实用的实时告警反馈,以及对隐蔽作弊手段更强的识别能力。可以说,技术落地的路径已经越来越清晰了。


