
从 3D Gaussian Splatting 到具身智能:AI 正在学会“进入世界”
过去十年,AI已经学会了两件事:读和写。大模型能理解复杂语义,也能生成高质量内容,看起来确实“很聪明”。但要是把它扔进真实世界——比如让它拿个杯子、开扇门、或者在一个陌生环境里行动起来——问题立刻就暴露了:它既不懂空间,也不会行动。
这恰恰是当前AI的边界所在。语言智能解决的更多是“知道”,而现实世界真正需要的是“做到”。从这个角度看,AI的下一个阶段,其实不是更强的对话能力,而是具身智能(Embodied AI)。有意思的是,在这条路上,一个原本属于计算机图形学的技术——3D Gaussian Splatting(3DGS)——正成为关键的支点。
3DGS:不只是更快的NeRF
很多人第一次听到3DGS,往往会把它当作“NeRF的加速版”。这种理解不能说错,但确实远远不够。传统三维表示方法一直存在一个经典矛盾:Mesh或点云结构清晰,但表达能力有限;NeRF表达能力强,但推理速度极慢。3DGS的价值恰恰在于——它打破了这种二选一的困局。用一组带有空间分布的高斯来表示场景,系统既获得了显式结构,又保留了连续表达能力,还能实现实时渲染。
但更关键的是,它带来了一个全新的可能性。材料中也点到:3DGS正在从“单场景表示”走向“世界级系统”。这句话背后,是整个技术方向的转折点。
一个关键变化:从渲染工具到“空间系统”
过去的三维技术大多是离线的。你建模、渲染、输出结果——典型的“工具链”。但现在的系统开始发生变化,它们更像是“运行时系统”:场景可以按需加载(类似视频流),数据可以跨设备访问,渲染复杂度与场景规模也逐渐解耦。这意味着什么?简单说:一旦三维数据变成“在线系统”,它就不再只是用来看,而是可以参与计算、推理甚至决策。这一步,才是3DGS真正“出圈”的原因。
AI的三块拼图:认知、空间、行动
如果再把问题往上抽象,其实可以用一句话概括当前AI的核心方向——把“知道”转化成“做到”。这背后对应三种能力:
1. 认知(Cognition)
由多模态大模型(比如GPT-4V、LLaVA)承担。它负责理解用户说什么、任务是什么、目标是什么。但它的短板也很明显:
它不知道世界的真实结构
2. 空间(Spatial Representation)
这正是3DGS的位置。它提供的能力是:物体在哪里、长什么样、跟其他物体的关系如何。从本质上看,3DGS正在变成一种“可查询的三维数据库”——你可以查询、操作、甚至更新这个三维世界。
3. 行动(Action)
这层最容易被忽视,但也最关键。传统方法用控制算法或强化学习,而现在越来越多工作开始用生成模型(尤其是Flow/Diffusion)来生成动作轨迹。相比扩散模型,Flow Matching的优势在于推理更快、延迟更低,更适合实时控制。
一个完整闭环:AI如何真正“做事”
当这三块拼图拼在一起,就会形成一个非常清晰的结构:
用户指令 ↓
多模态 LLM(理解任务) ↓
3DGS(获取空间信息) ↓
Flow 模型(生成动作) ↓
执行 ↓
反馈 → 再次更新这个结构的关键,不是每一层有多强,而是:
它形成了一个闭环
为什么3DGS是关键,而不是可选项
你可以把整个系统想象成三层:LLM是大脑,Flow是肌肉,而3DGS是眼睛和空间记忆。没有LLM,系统没有目标;没有Flow,系统无法行动;但如果没有3DGS,系统根本不知道世界长什么样。这也是为什么很多“看起来很强”的AI在现实环境中表现很差——它们缺的就是空间层。而3DGS的意义在于:它正在成为AI与现实世界之间的接口。
工程现实:理想很美,落地很难
说到这里,很容易产生一种错觉:路线已经很清晰了,剩下就是工程实现。但现实恰恰相反。目前最大的问题有三个:
1. 技术门槛极高
涉及多视图几何、神经渲染、优化算法——不是简单调库就能解决的。
2. 工程链路很长
典型流程是:数据采集→SfM→MVS→NeRF→3DGS。每一步都有坑,而且很多是“隐性坑”。
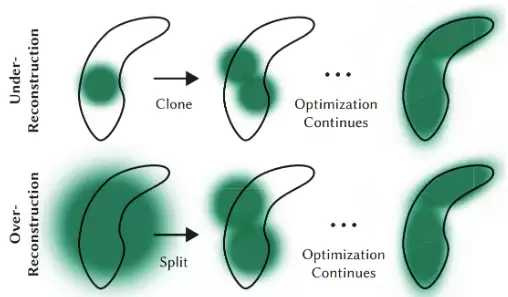
3. 性能优化困难
GPU显存限制、数据调度问题、实时性要求——很多项目跑是能跑,但不可用;可用,但不可扩展。
总结
如果用一句话总结这条技术路线:AI正在从“理解语言”走向“理解世界”。而这条路径的核心结构已经很清楚:大模型负责理解,3DGS负责建模世界,Flow模型负责行动。其中,3DGS是最容易被忽视的一环,但它很可能是一切的基础。如果你正在做三维重建、机器人、自动驾驶或者XR——这个方向基本可以确定,不是短期热点,而是长期基础设施。




