
300美元跑通世界模型!比老黄便宜10倍
风筝和鸟,都能飞。但风筝的飞翔是借来的——风借线,线借手,手借远处的指令。鸟不一样,翅膀是自己的,俯冲、停栖、转向,全凭大脑一念之间。
过去的具身智能,更像那只风筝。云端给了它“大脑”,却也用延迟和带宽拴住了它。一个倾倒的杯子、一场骤雨,就足以让它崩乱。真实世界等不起信号往返云端的那个来回。
X-Era Lab(拓元智慧)和星宸科技最近做成的一件事,是把风筝变成了鸟。他们把自研的世界动作模型 VWA,装进了一颗指甲盖大小的端侧芯片,完成了“感知—预测—控制”的全链路闭环。这次,他们剪断了那根线。

X-Era Lab 与星宸科技联合推出的首款端侧世界模型解决方案
把「大脑」真正装回身体
一个产品最原始的出发点,决定了它后来所有的形状,也决定了它会在哪里走形。如果一件事同时背着“炫技”“拿融资”“赶风口”太多目的,就会从“为用户解决真问题”,悄悄变成“替团队完成一场表演”。动作开始替老板做、替发布会做,而不再替那只要去抓住倾倒杯子的手做。
X-Era Lab 把发心收敛到了一件事上:做全球第一个原生的世界动作模型。说穿了很朴素,如果不能稳稳托住现实生活里的一只杯子,再酷炫的 PPT 又有什么用。所以它从第一天就认定,推理这件事,必须发生在机器人本体上。
具身智能的上半场,比的是谁的模型更大。下半场要回答的,是另一个更朴素的问题:谁能把“大脑”真正装回身体,让它在真实世界里跑起来,并且足够便宜地跑起来。
世界模型必须走到端侧
把模型放云端、机器人传画面回来等指令,这套链路在大模型时代很顺手,可一进物理世界就处处碰壁。说到底,那根“线”还在。
这个道理几乎人人都懂:自动驾驶不能只靠云端决策。肉眼看见的绿灯,等画面传上云、决策再传回来,可能已经变成了红灯。云端能告诉你“世界长什么样”,却赶不上回答“此刻该怎么办”。
工业场景里,亚毫米级的精密放置,机械臂的容错只有零点几毫米,决策一滞后,物体就被推过了头。家庭场景同样如此,一个几十公斤的机器人,若对人的状态判断慢了半拍,一个抬手就可能伤到人。在物理世界里,迟到的正确,约等于错误。
带宽也是关键约束。大语言模型往云端传的是文本,带宽要求很低;可世界模型要“理解世界”,一旦是多传感器、多模态融合输入,上行带宽会急剧膨胀。在 X-Era Lab 研发总监蒲韬看来,这正决定了两类模型的命运:大语言模型可以留在云端,世界模型必然走向端侧。文字可以打包托运,而世界,太重了,传不动。

依托端侧芯片把世界模型从云端搬到智能体上
成本压力也在倒逼这个方向。现阶段云端方案大多以 Token 使用量作为收费标准,但理解物理空间所需要的 Token 用量远超大语言模型所需,这使得具身智能商业化迟迟无法落地。一台机器人卖二十万,不便宜,可一算账才发现,反而是其整个生命周期中需要消耗的 Token 更有可能是个天文数字。厂商看不到利润空间,客户估不准落地成本。一个算不清账的商业模型,没有人敢真的下场。
X-Era Lab 的 CTO 陈添水觉得,国内硬件几乎都是一次性买断,极少订阅制能成立,原因正在于此。把模型放到端侧,这笔账才变成确定的:芯片装上去,怎么用都是那个成本。
隐私问题也在把世界模型推向端侧。Token 承载的隐私信息相对有限,但“理解世界”要持续处理大量视觉与空间信息,家里长什么样、生产线在做什么,这些远比一段文本敏感。一旦这些数据必须上传云端才能用,许多场景从一开始就不会向你敞开。把世界搬到云上的那一刻,很多扇门就已经关上了。
延迟和带宽,逼着世界模型往端侧走;成本和隐私,决定它走到端侧之后生意能不能做。前者是物理约束,后者是商业约束。两股力气,把答案推向同一个方向。对世界模型来说,走向端侧不是一道选择题,而是一道必答题;而它们共同指向的那个词,是确定性。这正是 X-Era Lab 从第一天就选端侧的理由。
能塞进端侧的,是为端侧而生的模型
在市场上,相比友商 Thor-U 芯片动辄 3000 多美元的方案,他们想让世界模型跑在两三百美元的芯片上。但靠事后裁剪是塞不进去的,这个模型从娘胎里就为端侧而生。
要看清 VWA 的不同,得先看看别人怎么走。当下的“世界模型”,大多走两条路线。一条是 VLA,建立在多模态大模型之上,加一个“动作专家”做改造;一条是以视频生成模型做内核,用 2D 表征渲染出 3D 世界。
VLA 的表征停留在语言模态——你问它面前的水瓶离自己多远,它能答“大概三十厘米”,但实际可能是十厘米,这是无法容忍的误差。视频生成模型停在 2D 像素空间,对真实 3D 刻画不足,做动作前还要先生成视频,成本高,2D 到 3D 的误差层层累积。
一个把世界“说”出来,一个把世界“画”出来——可机器人要的,是把世界“算”出来。X-Era Lab 的世界动作模型(VWA),绕开了这两条路线面临的障碍。
据陈添水介绍,VWA 在底层架构上做了三件事:
- 把物理与动作向量放进同一个 Token 内联合建模,再加上时序维度,共同构成 4D 数据;
- 没有沿用现成的多模态大模型骨干,而是专门为几何与动作设计了预训练网络;
- 让预训练和后训练的目标保持统一。别人是在后训练阶段、针对特定场景“打补丁”,而 VWA 在预训练阶段就把对物理世界的理解灌进了模型。
把三条路线摆在一起,差异其实落在同一个问题上:模型对“世界”的理解,到底停在哪一层?VLA 停在语言层,所以它只能把物体的位置估个大概;视频生成式停在 2D 像素层,做动作前先得生成画面,3D 信息在这一步就漏掉了精度。
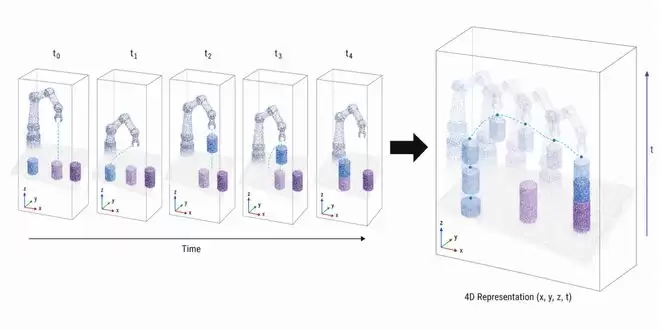
原生世界动作模型的 4D 表征
VWA 通过预测未来的 4D 世界来建模真实物理世界,也就是刻画 3D 空间随时间如何变化。在这样统一的时空表征中,场景的深度结构、机器人的动作轨迹,以及交互过程中蕴含的接触、碰撞、形变等物理规律,都可以被放在同一套模型里联合学习。
不同于许多基于视频生成的世界模型,VWA 不把主要算力消耗在纹理、光影、背景等与动作决策弱相关的视觉细节上,而是绕过这些表象,直接建模三维几何和时序运动。当模型学习点云如何位移、物体如何碰撞、形变如何发生时,它学到的不是“世界长什么样”,而是“世界会怎样变化”。
更关键的是,X-Era Lab 并不是把 4D 表征只当作后训练阶段的辅助工具,用来重建空间或合成数据;而是从预训练阶段就把 4D 作为统一底座,让物理理解、空间预测和动作生成落在同一套表征里联合学习。换句话说,别人是在用 4D 补数据,VWA 是从一开始就长在 4D 上。
因此,VWA 能以更小模型完成更复杂任务,并不是靠后期裁剪或蒸馏硬挤出来的,而是因为它从源头减少了无效负担。不需要背一个庞大的多模态大模型骨干,也不需要反复生成冗余视频画面。它把参数和算力集中用在与机器人行动最相关的空间、时间和物理规律上。这也是 VWA 同时具备端侧部署可行性和 Scaling Law 潜力的根本原因。
VWA 的每个物理 token 的预测都基于过往 N 个时刻所构成的 4D 表征
模型怎么“住”进芯片
模型再好,最终都要落到一颗具体的芯片上——能不能“住”得进去,才见真章。
这次的合作方是星宸科技,一家以图像信号处理、AI 处理器、音视频编解码为核心 IP 的上市公司,2025 年上半年机器人视觉 AI SoC 出货量已居全球第二。视觉与 ISP 本就是它的老本行,而这恰恰是“理解世界”最需要的那只眼睛。
X-Era Lab 与星宸的合作一拍即合。在具身领域,软硬协同不是加分项,而是必选项。而星宸恰好是那个愿意“协同”的芯片方。双方对“机器人的脑子要长在机器人身上”判断一致,星宸也在资本和内部资源上给予了支持。
更关键的是,这不是“模型做完了再找芯片”的接力,而是从模型训练的第一天,两边就坐在了一张桌子上。
世界模型表达的是连续的世界空间,与常见的离散压缩不同,普通离散量化会带来较大精度损失。世界模型需要刻画连续变化的物理规律,而将模型压缩至 4 位极端精度,意味着用最离散的表示去逼近最连续的世界,本身就是一项极具挑战的课题。为此团队与星宸科技展开深度合作,从底层工具链、算子实现到内存调度策略进行全栈联合优化,专门为 VWA 架构量身定制,让模型在端侧芯片上既能高效运行,又能精准还原物理世界的连续性与细节。
芯片侧也做了全面配合。星宸 IPU 算力覆盖 0.1 Tops 到上千 Tops 全档位,按算力区间布局而非“一颗万能芯片打天下”;自研 StarShuttle 推理框架已迭代四次,支持多模态算法与 AWQ/GPTQ 量化;面向具身智能提供的是分布式计算架构。它还针对 VWA 的独特算子做了芯片级优化,相比软件级,效率可提升上百乃至上千倍。正是这种咬合,才让一颗成本可控的芯片,跑得起一个完整版的世界模型。
而且,星宸正在布局双目 3D 成像与 Lidar SoC(SS901XX 系列,探测 0.5 至 500 米及以上、精度 ±0.03 米),做的正是 3D 感知。X-Era Lab 反复强调“理解 3D 物理世界”,芯片伙伴恰好在硬件层做 3D 感知。这场合作便不只是“芯片能跑模型”,而是感知与世界理解在物理层的咬合。一个把世界看清,一个把世界想透,远比单纯的算力适配走得更深。
X-Era Lab 表示,星宸是目前性能与成本的最优选。它还提供跨场景、跨芯片、可量产的统一软件底座,并以开放方式向行业释放能力,从 Comake 开发者社区、Comake Pi 开发板,到全栈 AI 工具链和开源模型库,构成“开发者赋能→产品化落地→生态规模放大”的正向飞轮。换句话说,端侧从来不是一次性的单点合作,而是一个能不断接入新伙伴的底座。
星宸描绘过一个“多形态共存的机器人世界”:扫地的、陪伴的、清理泳池的、修剪草坪的、端茶的……不管四足的、还是两脚的。它们形态各异,却被同一句话框定:场景驱动,任务清晰。

原生世界动作模型部署在端侧 AI 芯片的丰富应用场景
回归
伟大的远征,最终都不是为了离开,而是为了有能力,回到最初要去的地方。
机器人最初被改造,是为了变得更聪明,大模型的浪潮将它的“脑”托举上云。世界为它的聪明惊叹,几乎要忘了它原本是为了“做事”而生的。一个只会思考、不能伸手的智能,想得再远,够不到那只正在倾倒的玻璃杯,便什么也改变不了。
X-Era Lab 与星宸今天合力做的,正是这桩关于“回归”的事。他们要把那个一度被放逐到云端的智能,重新唤回到指甲盖大小的身体里,让它的眼、它的算、它的决断,重新长在一处。
人类无数次畅想未来惊天动地的样子。但技术真正成熟的标志,往往是相反的——是它不再被谈论。
扫地机器人不再沿记忆里的路线死转,看见地上一摊水会先绕开,而不是扎进去推得满屋狼藉。割草机器人开过被夜雨泡软的草地,知道这里会陷,便放慢绕行。服务机器人端着热水穿过大堂,预判到那个正低头看手机、即将拐进它路线的人,提前停下。它算的不再是“前方半米有障碍”,而是“那个人下一步会走到哪”。
此刻,在厨房流理台边,一只机械臂去够那只半透明的玻璃杯。而杯子已经在往下滑。它收力、调角、托住。没有惊险的特写,没有该响起的配乐,事情只是平平淡淡地过去了。
今天没有人会赞叹电灯会亮、风扇会转;有朝一日,也不会有人再赞叹一台机器人“居然能自己想”。它只是安静地待在客厅的某个角落,把一件件小事做完,像它本就该在那里。这是 X-Era Lab 和星宸想做的:一切的不可想象,终将化为寻常。




