
具身机器人研究全都错了?最新论文:不能只靠VLA和世界模型
更多的机器人示范数据、更大的视觉-语言-动作(VLA)模型,再配上更懂“物理定律”的世界模型,就能实现“通才机器人智能”吗?
这听起来像是通往通用机器人的一条“明路”,也是当前具身智能领域的主流研究范式。不过,最近一篇刚挂上 arXiv 的立场论文,直接点出一个“打脸”的结论:这条路大概率走不通。
这篇论文来自具身智能数据公司 Motoniq 的团队及其合作者。他们不仅指出了现有 VLA 和世界模型研究范式的局限性,还一针见血地揭示了实现真正物理智能所缺失的“四个组件”,并为未来研究指明了方向。

论文链接:https://arxiv.org/abs/2606.06556
简单来说,通用机器人真正缺的,远不止一个更大的策略模型。关键在于,我们需要一套能够将非结构化的物理行为,转化为结构化监督信号的完整机制。只有补齐了数据接口、具身接口、世界模型接口和奖励接口这四个关键组件,机器人才有可能不再单纯依赖预先准备好的示范数据,而是在更广阔、更真实的物理世界中自主学习。
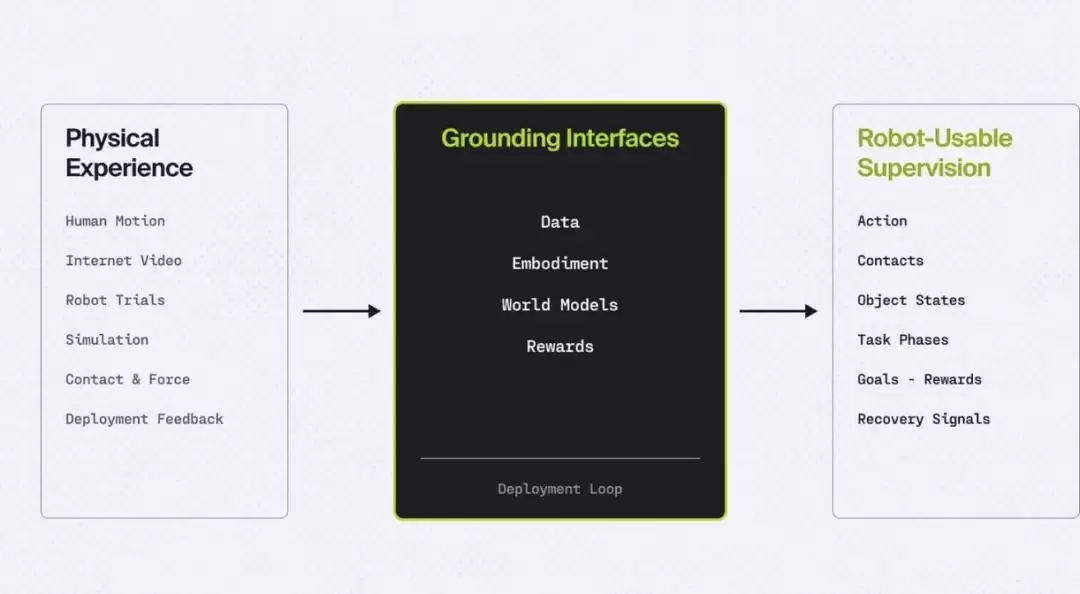
图|从物理经验到机器人可用的监督。
当然,这篇立场论文并非在否定 VLA 模型和世界模型的价值。相反,它们更像是整套物理智能系统中的一个核心“大脑层”,只是这个大脑的强大,离不开底层数据、本体硬件、物理动力学、奖励信号和部署反馈的全方位支撑。
为什么说现有范式不完整?
研究团队梳理了当前具身智能研究的三大主要范式:机器人原生监督、视频弱监督以及仿真与基于世界模型的数据生成。每个范式都有进展,但短板也同样明显。
机器人原生监督:进展与瓶颈
目前主流的机器人学习,依然依赖于机器人能直接理解的数据形式,比如“观测-动作”轨迹、任务标签、语言指令和成功信号。像 BridgeData V2、DROID、Open X-Embodiment 这些数据集的出现,极大地扩充了这类数据的规模,也为 OpenVLA、GR00T N1、Gemini Robotics 等系统提供了训练基础。但问题在于,最有效的监督信号,至今仍然来自那些已经经过“接地”处理的机器人轨迹。动作标签、任务描述、成功/失败信号,要么在数据采集时直接记录,要么在后期费力补齐。VLA 的能力扩展,本质上还是建立在这些预先整理好的“高级食粮”之上。
弱监督视频:信息丰富,却难以直接用
互联网上浩瀚的人类操作视频,蕴含着行动的过程、物体的运动和接触的时间点。但它们无法直接转化为机器人可执行的动作。现有工作更多是把这类视频当作“间接监督”:R3M 用它来预训练视觉表示,VIP 用来刻画任务进度,LAPA 和 UniVLA 则尝试从中学习潜在的动作编码,再映射到机器人控制。但视频中的“信息”和机器人学习所需的“监督”之间,存在着一条鸿沟。潜在动作并非控制指令,进度信号也未必能直接用作奖励,更何况,人类的操作策略,对于特定机器人硬件来说,往往是不适用的。
生成物理经验:仿真与世界模型的局限
受限于真实机器人数据采集的高昂成本,研究团队开始借助仿真环境和世界模型来生成训练数据。从 MimicGen、RoboCasa365、RoboGen 等数据生成方法,到 DreamerV3、V-JEPA 2 等控制与交互仿真探索,再到 ParticleFormer、ContactGaussian-WM 等面向点云和接触操作的建模工作,进展不可谓不快。但现有的世界模型有明显局限。关键在于,除了生成逼真的未来画面,更核心的是能否保留那些决定控制成败的物理变量:几何形状、物体状态、接触点、力、稳定性、材料响应。如果模型忽略接触、质量和摩擦这些底层物理量,那么它预测出的结果,即便视觉上再完美,也无法作为可靠的机器人监督信号。
物理智能缺失的四个组件
在深入回顾现有研究后,研究团队一针见血地指出,下一步研究的突破口,或许并不在于把模型做得更大,而在于补齐以下四个缺失的组件:
1. 物理数据引擎与具身自动标注
要让机器人利用更广泛的物理经验,首先得有一个“物理数据引擎”。当前的机器人学习大多依赖精心整理好的训练样本,而人类视频、可穿戴传感器数据、工厂运作流程、甚至失败的轨迹,虽然蕴含着丰富的物理交互信息,却因为格式不统一而难以直接利用。为此,团队提出了“具身自动标注”(Embodied Autolabelling)的概念。核心思路是指从原始数据中自动识别任务的起止点、操作对象、接触事件、状态变化和结果,并完成时间对齐、事件分割和状态估计。这样一来,人类视频和可穿戴数据不仅能用来学习任务目标,还能帮助机器理解人的动作意图和交互方式。
2. 跨具身的任务保留重定向
不同机器人硬件在运动学、动力学、传感器和接触面上差异显著。如何将一个潜在物理动作或人类演示,有效迁移到另一台机器人上,同时保留其“对世界产生的预期效果”?这就是跨具身任务保留重定向的核心挑战。它关注的不再是复制动作本身,而是保留任务相关的关键物理变化,比如物体的位移、姿态变化、接触状态、插入时的对齐关系等。
3. 物理扎根的世界模型
未来的世界模型,不需要能画出多么漂亮的画面,但必须能精确预测动作带来的物理后果:这个物体会不会滑落?那个接触点会不会丢失?抽屉会不会卡住?这需要模型能正确预测与任务相关的几何形状、接触点、作用力、约束条件、材料属性以及任务进度。研究团队强调,这类模型还必须具备可靠的不确定性估计能力,知道自己什么时候“猜不准”。
4. 自我改进的部署循环
机器人执行动作后,如何知道结果是否有效?这需要一种“任务条件化的奖励扎根”机制。当部署轨迹能被自动评估为成功、失败、部分进展或恢复之后,它们就不再仅仅是记录,而是转化为了宝贵的监督信号。系统可以基于这些信号进行闭环迭代,精准定位失败的根源,并以此来更新前端的决策模型,而不是笼统地进行一次全量重训练。
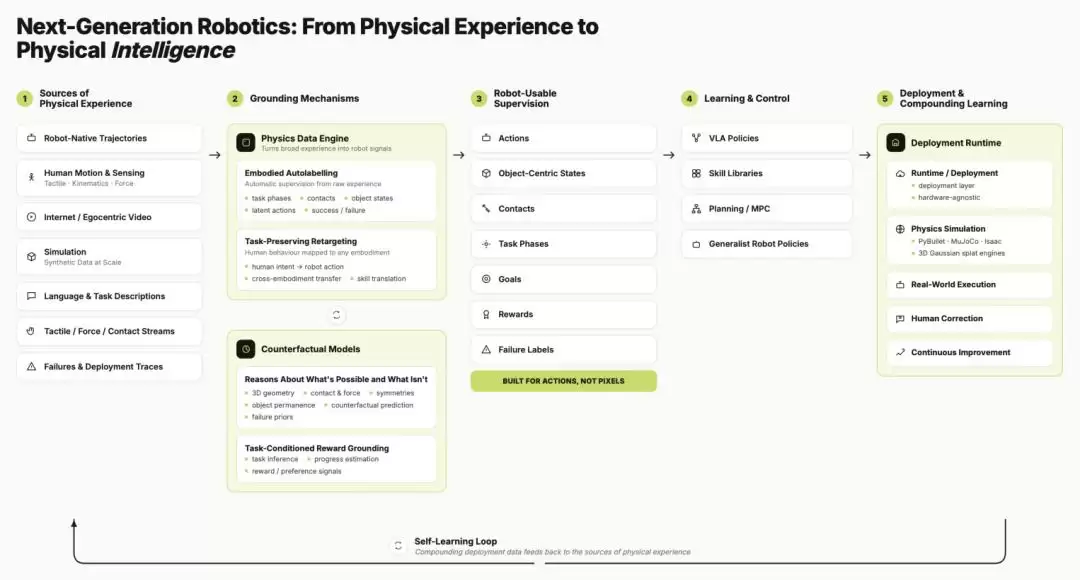
图|下一代机器人:从物理经验到物理智能
未来方向
从目前来看,各类物理经验都只提供了不完整的监督:机器人数据缺标签,视频数据缺动作,可穿戴数据不绑定具体机器人,仿真则受限于物理保真度。未来的关键,是构建一个统一的“物理数据引擎”,将这些异构来源的数据视为同一底层物理结构的不同视图,并最终转化为结构化的、可用于训练的标签。
同时,世界模型在表示选择上尚未形成统一方案。无论是像素表示、物体中心表示,还是点云、网格、神经场、Gaussian Splatting 等三维表示,都有各自的局限性,尤其在对接触、受力和材料响应的建模上还远远不够。未来的方向是发展物理扎根的世界模型,并显著提升其不确定性量化能力。
跨具身重定向方面,目前清晰的可实现路径和验证方法依然缺失。未来的研究重点,需要从姿态保留转向任务效果保留——不再执着于复制动作的形式,而是保留动作对世界产生的实际效果。
最后,部署失败带来的反馈,往往难以沉淀为有针对性的改进信号。未来需要建立一种任务条件化的闭环机制,使系统能够精确区分进度、失败、恢复和成功等不同状态,并据此更新相应组件,而不是笼统地责备整个系统。




