
2026,卖数据比卖机器人先赚钱
人形机器人能在春晚上跳舞,能跑马拉松,却拧不开一个陌生的瓶盖。这背后的症结,恰恰在于数据不够“见过世面”。
时间来到2026年,当资本狂潮席卷具身智能赛道,一个残酷的真相正在浮出水面:高质量具身数据,已经成为锁住整个行业进化的最大枷锁。面对
高达99%的数据缺口
数据规模化元年
所谓“元年”,并非意味着问题已经解决,而是标志着行业第一次从“做Demo”的阶段,正式迈入了“构建规模化数据系统”的新征程。有三件事正在同步发生:
百万小时级
核心预算
场景
历史经验表明,技术浪潮中,最先赚钱的往往是那些“卖铲子的人”。2026年,一场围绕具身智能的数据生意,正在悄然沸腾。
具身数据,需求爆发
具身数据,需求爆发
进入2026年,具身智能领域的数据需求正在快速升温,其热度远超去年。作为该领域的头部服务商,光轮智能2026年一季度的订单额已突破5.5亿元,超过了去年全年总额,刷新了行业纪录。目前,国际主要具身智能团队中,超过80%的仿真资产与合成数据都来自该公司。
这背后,是数据正被提升至前所未有的战略高度。行业已清晰认识到,决定模型能力上限和场景落地速度的,不只是算法和硬件本体,更在于有没有一套持续、可迭代、可评测的数据供给体系。数据业务,已成为客户预算中增长最快的板块之一。
智元机器人旗下觅蜂科技的负责人也感受到了这股热浪。需求方普遍处于一种“你有多少我就买多少,你什么时候有,我马上要”的急切状态。市场共识正在形成:数据将像算力一样,成为AI时代的基础生产要素,并且带有投资属性和回报周期。参考基础设施先行的逻辑,
数据投资的回报周期,很可能比本体机器人或面向具体行业的解决方案来得更快
这股需求爆发的背后,主要有三大驱动引擎:
第一,“大脑”进化倒逼数据“口粮”。制约机器人规模化落地的核心瓶颈,已逐渐从硬件和底层运控,转向了“大脑”——即具身智能模型本身的能力欠缺。随着具身视觉语言模型与世界模型快速突破,开始进入更复杂的任务空间,必须以海量数据持续喂养。
第二,产业落地加速,数据需求从实验室级别转向部署级别。当机器人开始走进工厂、物流、商业等真实场景,其对数据规模的要求呈指数级提升。完成一个单一任务可能需要千小时级的训练数据,复杂任务的需求量则更为庞大。
第三,非本体数据的价值被验证,采集效率实现跃升。过去,数据采集主要依靠实验室手动操作,效率低下;如今,VR遥操作、外骨骼、UMI、Ego-centric等技术逐渐成熟,数据采集正从小规模、低效率的“手工作坊”,走向规模化、高效率的工业化生产阶段。
然而,与爆发式需求形成鲜明对比的,是严重的“数据荒漠”。行业共识是,要训练出具备通用泛化能力的具身模型,至少需要千万小时级的数据支撑。但截至2026年初,全球高质量的真实物理交互数据总量仅约50万小时,不足大语言模型训练数据的两万分之一。综合来看,
具身智能需要数百PB级的物理交互数据,当前缺口超过99%
机遇与卡点并存之下,一场关于具身数据的争夺战,已经全面打响。
数据金字塔,玩家卡位
数据金字塔,玩家卡位
面对99%的庞大缺口,供给侧已告别零散试水,迅速掀起了数据基建的狂潮。“百万小时”成为了入局的标配门槛,多家企业宣布冲刺百万甚至千万小时级的数据产能。
行业大规模扩产的背后,是一套被普遍认可的“
数据金字塔
真机数据
仿真合成数据
无本体数据
供给侧的行动,最先落在了金字塔尖的真机数据上。其中,主流的遥操作数据被视为“黄金数据”。截至2026年4月初,全国规划或拟建成的具身智能数采中心、创新中心与训练场已达到64座,覆盖至少27个城市。
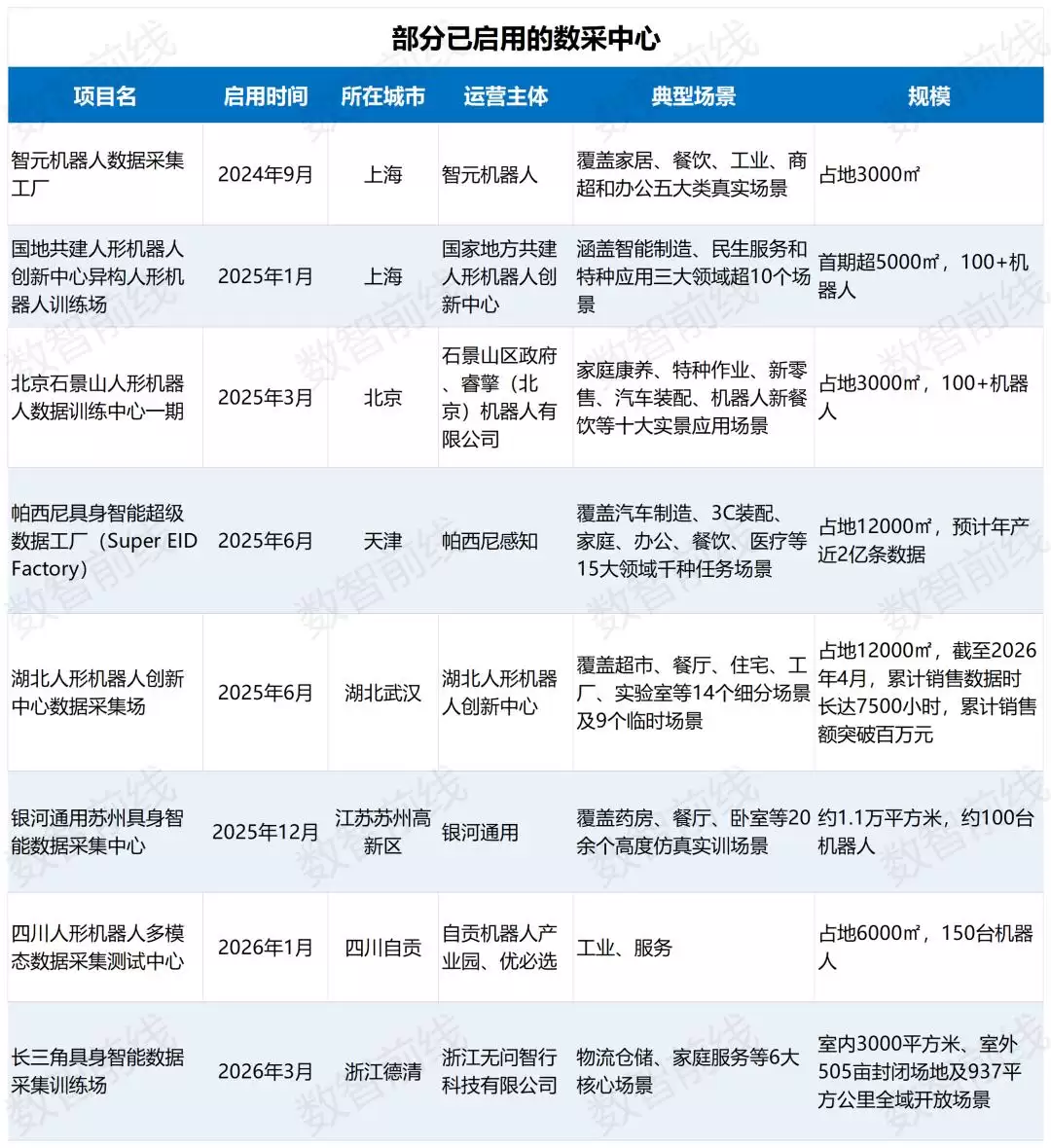
头部企业已成为建设主力军,在多地布局数采中心与工厂。地方政府也积极参与,例如上海张江建成了全国首个异构人形机器人训练场。不过,受限于高昂的采集成本与有限的效率,真机数据很难快速实现规模化。因此,行业加速转向“强化中层仿真数据+夯实底层人类数据”的混合策略,以降低对昂贵真机数据的绝对依赖。
目前,
仿真合成数据
与此同时,以UMI、Ego-centric数据为代表的无本体数据正在异军突起。这类数据仅需采集员佩戴可穿戴设备即可记录操作轨迹,兼具高效、低成本与强泛化性。市场数据显示,国内真机数据市场价格约为500-1000元/小时,而无本体数据的采集效率大概是真机的两三倍,虽然曾因规模化不足出现过报价更高的情况,但预计最终成本将收敛至真机数据的三分之一到二分之一。
具体而言,UMI方案通过人工手持标准化夹爪演示操作,并由摄像头记录,只要夹爪外观与摄像头参数一致,数据即可通用于不同机械臂。Ego-centric数据则通过头戴、腕戴设备采集第一人称视角与动作信息。这两种方案都更容易实现“众包采集”,从而快速扩大数据规模。
市场正在加速爆发,但百万小时远非终点。行业真正的瓶颈并非单一数据源,而是缺乏统一、可流通、可持续的数据基础设施。为此,多家企业推出了数据全链路基础设施、交易平台或一站式服务平台,旨在构建从数据生产到应用的价值闭环。
什么样的数据,能喂饱具身智能?
什么样的数据,能喂饱具身智能?
随着数据争夺战愈演愈烈,一个关键问题浮出水面:什么样的数据,才是当下行业最迫切需要的“好数据”?
今天,客户采购具身数据时,关注的焦点早已不是“量大不大”或“单价高不高”,而是这批数据能不能真正转化为模型能力的提升。
企业购买的不仅是“数据量”,更是“能否支撑训练、评测和部署闭环的系统性能力”
具体来看,客户首先会关注数据种类,其次是数据是否已经过处理并标注,标注了哪些维度、精度如何。这些细节都成为选择数据的重要参考。
业界观察发现,真正高质量的具身数据,通常需要同时满足四个条件:
第一,
物理真实
第二,
可规模化
第三,
多样性足够高
第四,
端到端可用
除了这四个维度,行业还提出了一个更深层的标准:
行为对齐
从需求结构看,目前最迫切的数据需求,主要集中在生产制造、仓储物流等场景,尤其是柔性装配、搬运,以及一些环境恶劣、重复单调的任务。这类场景一方面真实落地价值明确,客户付费意愿强;另一方面,对物理交互、稳定性和泛化能力要求极高,也正是当前高质量具身数据最稀缺的地方。
还有哪些卡点?
还有哪些卡点?
尽管热度持续攀升,但不可否认,当前具身数据的规模化进程仍面临诸多挑战。
首先,行业内存在大量“非共识”。对于实现通用人工智能究竟需要多少数据、哪些模态、如何评价数据质量等根本性问题,大家还没有想清楚。行业在数据科学层面仍有诸多问题尚未解答,远未到单纯通过数据工程进行规模扩张的阶段。
成本与效率
数据利用率低
认知与需求对齐难
最底层的痛点,在于
数据标准体系的缺失
目前,国内已加快标准建设步伐,从地方到部委相继出台相关标准文件。企业侧则通过构建“仿真生成、评测验证、真实对齐”的闭环能力,或推出覆盖“采、存、标、训、评、仿、测”全流程的数据基础设施,来提升数据复用效率,压缩开发周期。
可以确定的是,行业目前距离“数据充足”还很遥远。真正稀缺的不是数据的数量本身,而是高质量、可复用、可评测、能进入价值闭环的数据。谁能率先打通从数据采集到商业价值的完整闭环,谁就能在下一阶段的竞争中占得先机。
2026年,站在规模化的关键拐点上,具身智能数据的故事,其实才刚刚开始。




