
斯坦福评测第一!北大 EvoPhys-World世界模型在摩尔线程GPU完成原生训练
北京大学EvoPhys团队近日放出了一颗重磅冲击波——他们推出的5D世界模型EvoPhys-World,真正把“人”放在了C位,目标直指“场景级万物可控”。在斯坦福大学WorldScore公开评测榜单上,截至发稿时,EvoPhys-World已经在世界生成(World Generation)评测中位列第一,这可是国际公认的硬指标。更值得关注的是,这项国际前沿成果
全程在摩尔线程MTT S5000全功能GPU上完成原生训练,并由MUSA软件栈提供全栈支撑
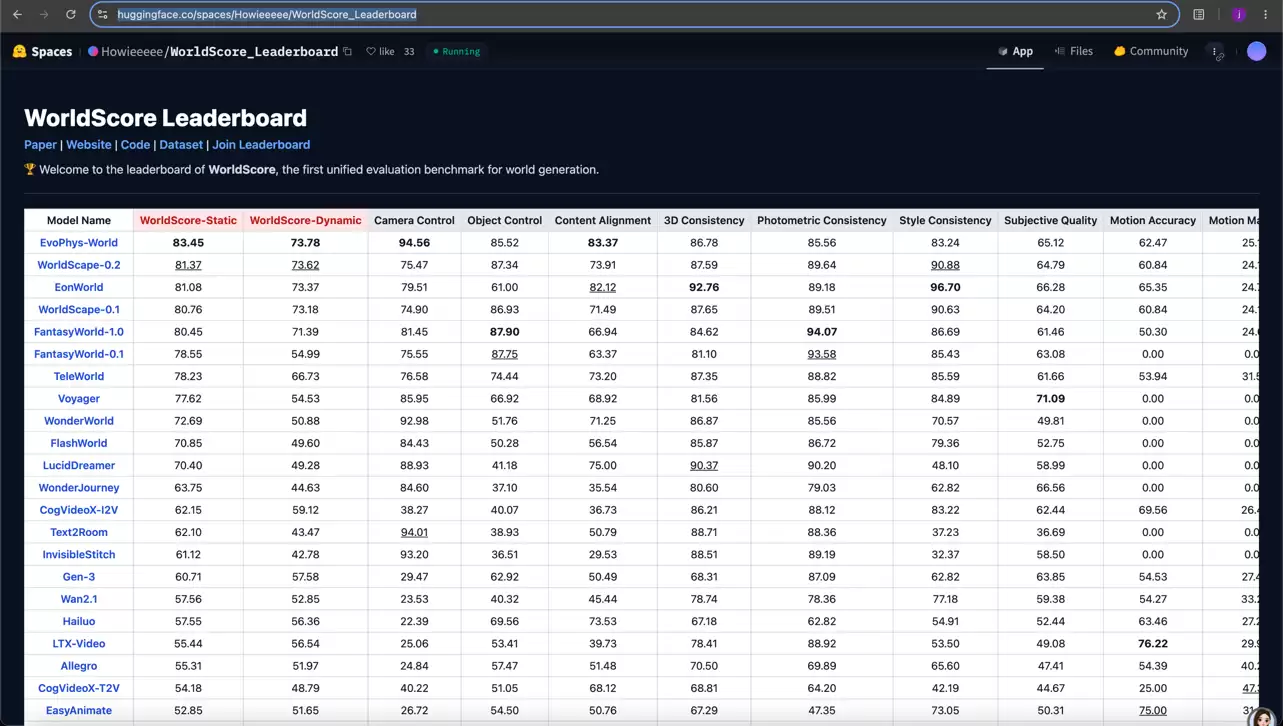 WorldScore 实时榜单:EvoPhys-World 位列第一
WorldScore 实时榜单:EvoPhys-World 位列第一
排名公示链接:https://huggingface.co/spaces/Howieeeee/WorldScore_Leaderboard
从像素到物理,从“看见世界”到“撬动世界”,世界模型正在重塑AI理解物理世界、迈向具身智能的根本范式;在通用人工智能的版图中,它已成为检验算法创新与算力能力的试金石。EvoPhys团队的此次突破,正是中国科研力量在这一前沿方向上的有力探索。
模型能力与技术细节详见项目主页:https://evophys.com
世界模型:AI 走进物理世界的试金石
世界模型:AI 走进物理世界的试金石
过去一年,AI正从数字世界加速走进物理世界,而能否真正“理解并撬动世界”,是这一进程绕不开的命题。一系列公开工作已经能够构建连续、逼真的虚拟世界,但“可操控、可交互”仍是行业的开放课题——生成的世界大多更擅长“看”,而较少能真正“动”。
EvoPhys-World的特殊之处,正在于把AI生成的世界从“可观看、可漫游、浅交互”,推进到“可操控、深交互、自进化”:它以“人”为中心,将第一视角下的人类观察与手部交互作为通用动作表征,从大规模原始无标注人手EGO数据中学习;并以
World Engine(万物可孪生、物理可交互)
World Policy(世界可预演、万物可操控)
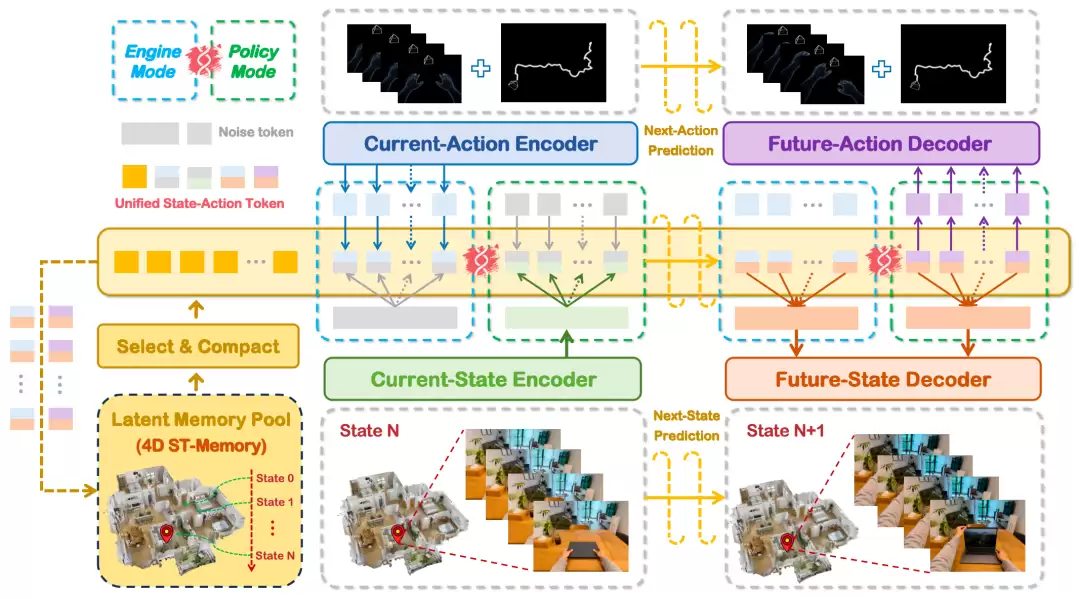 EvoPhys-World 模型架构图
EvoPhys-World 模型架构图
这一前沿探索的国际能见度,也得到了第三方公开评测的印证:在斯坦福大学提出、发表于ICCV 2025的世界生成统一评测基准WorldScore上,截至本文发布时,EvoPhys-World位列世界生成评测第一。
国产算力护航:MTT S5000 全功能 GPU 与 MUSA 软件栈全程支撑前沿世界模型训练
国产算力护航:MTT S5000 全功能 GPU 与 MUSA 软件栈全程支撑前沿世界模型训练
世界模型是对算力与软件栈的双重考验。面向约4万小时纯人手EGO数据,EvoPhys-World需要在长时序第一视角交互数据中,同时建模时空记忆、状态预测、动作预测、物理交互与策略演化,对训练稳定性、数据吞吐与软硬件协同效率提出了很高要求。
作为摩尔线程旗舰级AI训推一体全功能GPU智算卡,
MTT S5000
MUSA软件栈
- :MTT S5000面向大模型训练与推理负载,结合架构层面的计算单元协同与原生FP8等多精度训练能力,为前沿模型训练提供底座算力。
全功能GPU算力底座
- :从分布式训练框架、丰富的算子支持,到高效的卡间通信与软硬件协同优化,MUSA软件栈支撑了这一以扩散式生成为核心、融合多模态时空建模的新型世界模型,从适配到稳定训练的全链路落地。
MUSA软件栈全方位支持
- :依托高效的卡间通信与并行策略,MTT S5000集群在长时序、高负载的世界模型训练中保持稳定运行与大规模扩展能力。
大规模稳定扩展
这意味着,国产全功能GPU不仅能“跑得起来”前沿世界模型,更能在软硬件深度协同下,支撑其从研发探索走向规模化训练。
软硬协同的训练成绩单
软硬协同的训练成绩单
EvoPhys-World
全程在MTT S5000上原生训练
- :训练吞吐在从单机到20节点规模的扩展中保持近线性增长,多机区间弱扩展效率保持在约90%水平,验证了国产算力平台在大规模世界模型训练上的可扩展性。
大规模近线性扩展
- :在对齐验证条件下,MTT S5000与国际主流产品的训练吞吐基本持平、多机扩展效率曲线趋势接近。
与国际主流GPU性能接近
- :在相同初始帧、相同prompt的推理设置下,基于国产算力训练所得模型与基于国际主流产品训练所得模型,生成的第一视角人手操作视频在抓握姿态、书写笔迹、手—物接触与物理反馈上定性一致,无明显结构崩坏或时序断裂。
生成质量定性一致
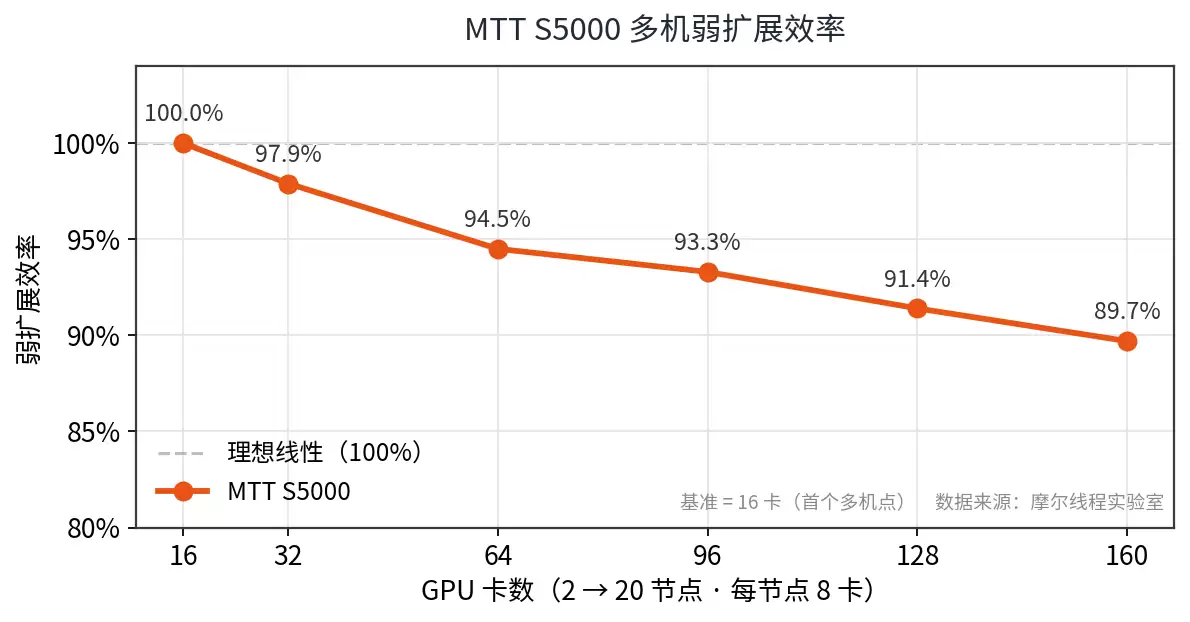 图1 · MTT S5000多机弱扩展效率(以16卡为基准):从单机到20节点(160卡),训练吞吐保持近线性扩展,弱扩展效率约90%。数据来自北京大学EvoPhys团队实测。
图1 · MTT S5000多机弱扩展效率(以16卡为基准):从单机到20节点(160卡),训练吞吐保持近线性扩展,弱扩展效率约90%。数据来自北京大学EvoPhys团队实测。
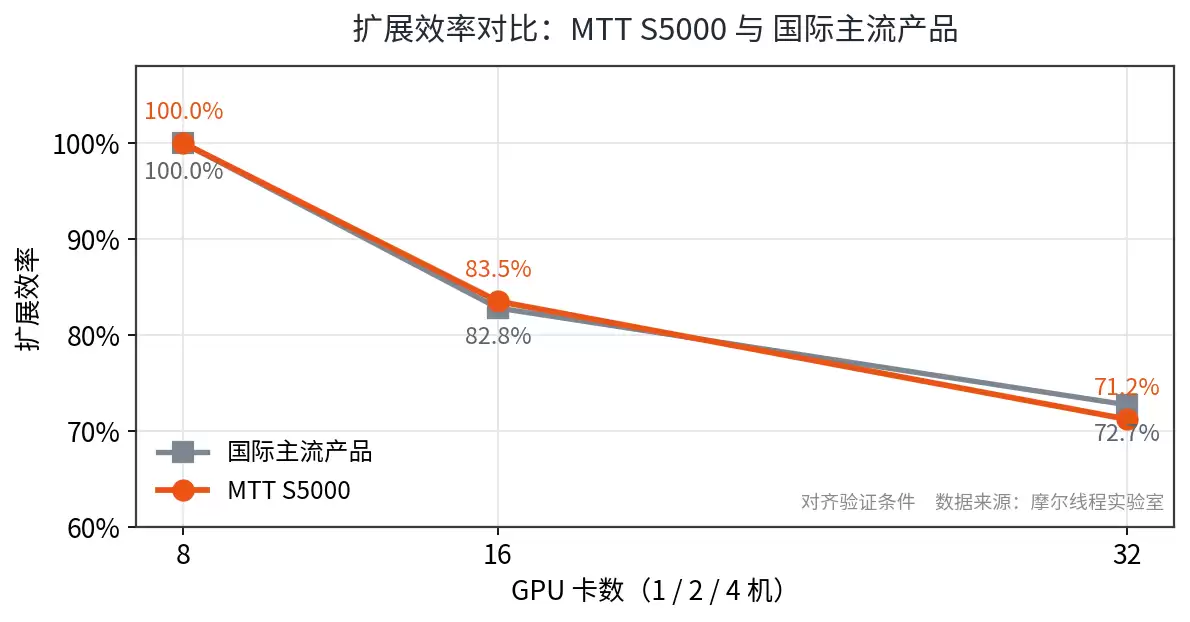 图2 · 对齐验证条件下,MTT S5000与国际主流产品的多机扩展效率曲线趋势接近。数据来自北京大学EvoPhys团队实测。
图2 · 对齐验证条件下,MTT S5000与国际主流产品的多机扩展效率曲线趋势接近。数据来自北京大学EvoPhys团队实测。
规模 |
MTT S5000 相对训练吞吐 |
| 1机/8卡 | 100% |
| 2机/16卡 | 101% |
| 4机/32卡 | 98% |
表1 · 对齐验证条件下相对训练吞吐(以国际主流产品为100%):MTT S5000与国际主流产品基本持平。数据来自北京大学EvoPhys团队实测。
 配图:同prompt推理生成对比——左为基于国产算力训练所得模型,右为基于国际主流产品训练所得模型。Demo来自北京大学EvoPhys团队实测。
配图:同prompt推理生成对比——左为基于国产算力训练所得模型,右为基于国际主流产品训练所得模型。Demo来自北京大学EvoPhys团队实测。
全链路闭环:让前沿世界模型在国产算力上自主生长
全链路闭环:让前沿世界模型在国产算力上自主生长
一次成功的前沿模型训练,背后是一条完整的自主链路。摩尔线程与北京大学的此次协同,推动了“
前沿模型 — 本土软件栈(MUSA)— 国产算力(MTT S5000)— 开发者与产业工作流
对国内高校、科研机构与具身智能团队而言,这条闭环意味着在算力可得性、软硬件自主性与长期迭代能力上拥有更高的自主权,从而加速从前沿探索到产业落地的全流程。国产算力的命题,正在从“能不能训练模型”,走向“能不能训出在国际前沿评测中位居前列的模型、并让这套能力自主、可控地持续生长”——这也是国产软硬件生态从“可用”迈向“好用”与“领先”的关键一跃。
摩尔线程“灯塔计划”全力支持中国科学家做出世界领先的原创成果
摩尔线程“灯塔计划”全力支持中国科学家做出世界领先的原创成果
EvoPhys-World的此次突破,也是摩尔线程“灯塔计划”支持下的一项标杆成果。“灯塔计划”是摩尔线程面向全球科研机构推出的算力支持与协作计划,为具有创新性、前沿性的科研项目提供优惠算力以及工程、生态资源,助力科学家突破资源瓶颈、聚焦核心问题、加速原创突破。摩尔线程希望以国产芯片与国产软件栈为底座,支持中国科学家做出世界领先的原创成果——本次与北京大学EvoPhys团队的协同,正是“灯塔计划”的一次生动实践。
结语:从“看见世界”到“改变世界”
结语:从“看见世界”到“改变世界”
物理世界的数字镜像,正在被逐层理解、逐步“撬动”。世界模型的竞争,正从“谁生成得更逼真”,走向“谁更懂物理、谁更会交互、谁能自我进化”;而支撑这场竞争的算力底座由谁来筑、能否自主可控,同样是一道必答题。
在AI走进物理世界的时代浪潮中,摩尔线程愿与高校、科研机构及广大开发者一道,以全功能GPU与MUSA软件栈为坚实底座,并通过“灯塔计划”持续为前沿科研提供算力与工程支持,在从“看见世界”到“改变世界”的未竟之路上,助力更多科学家突破核心技术、推动产业高质量发展。




