
PawBench:阿里通义开源的全链路AI智能体自动化评测基准
一、PawBench 是什么
PawBench
开源AI智能体系统评测基准
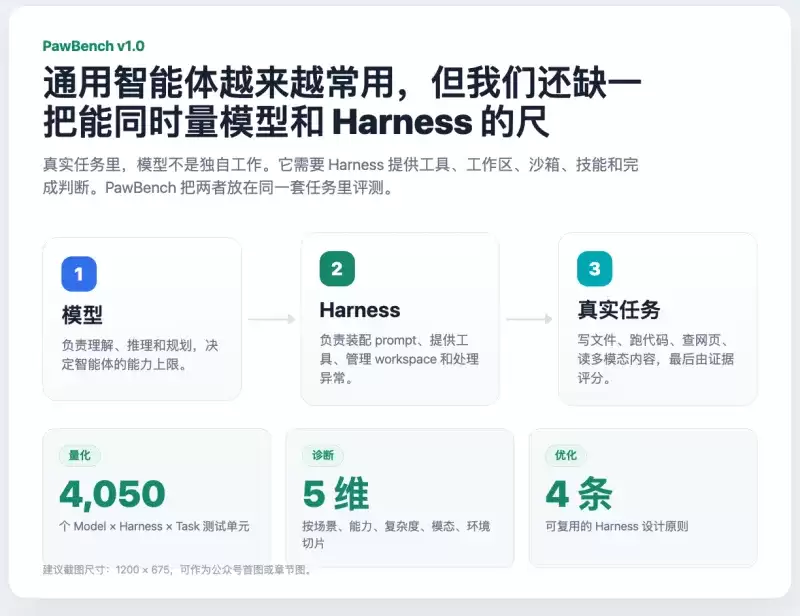
说人话就是:传统的大模型评测,大多是给模型单独做个阅读理解考试,看看它知识储备怎么样、推理能力行不行。但真正到实际落地的时候,模型、运行框架、实际业务任务这三个环节是绑在一起跑的,结果往往和单项测试完全不一样。PawBench 跳出了这个老套路,搞了一套
三维交叉评测
首发版本已经内置了大量真实场景的测试用例,覆盖个人助理、自动化办公、工具调用、复杂决策这些主流 Agent 场景。它不光能测底座大模型的能力天花板,还能检验智能体框架的工程稳定性、任务调度水平、多工具协同适配能力。可以说,这是目前业内
全链路AI智能体评测
四、应用场景
PawBench 定位很明确——就是给全链路 AI 智能体做评测。覆盖的场景也挺广,主要集中在
技术研发、产品选型、性能优化、学术研究
AI 智能体产品选型
企业或者个人开发者,在搭建自己的 AI Agent 系统时最头疼的就是选哪个大模型、配哪个框架。这时候拿 PawBench 批量测几组组合,看看各自在标准任务上的表现,数据说话,比拍脑袋靠谱得多。智能体版本迭代测试
研发团队在升级智能体框架、换底座大模型、或者改业务逻辑之后,用标准化的测试用例做一次回归测试,能快速确认新版本有没有出现能力回退或者兼容性问题。这是工程落地里最常用的场景之一。问题排查与性能调优
线上 AI 智能体有时候会莫名其妙地任务失败、响应异常、调用卡顿。通过 PawBench 复现故障场景,能帮你快速定位问题到底出在模型、框架还是业务逻辑层面,然后针对性做优化。行业评测与榜单制作
行业媒体或者技术社区,要想输出客观、可复现的 AI 智能体能力榜单,这个开源基准就是天然的评测工具包。跑出来的数据可比主观评测有说服力得多。教学与学术研究
高校和科研机构,拿它当实验工具来研究模型能力、做框架对比、验证新算法,都是很合适的场景。门槛低、用例标准、结果可复现。开源项目兼容性适配
各路开源 AI 框架和大模型的开发者,也可以借助 PawBench 验证自己的项目和主流生态的兼容性,看对接是否顺畅,有没有遗漏的适配点。
五、使用方法
接下来这部分是基于官方标准流程,把从部署、配置、运行到查看报告的完整步骤走一遍。操作不复杂,新手跟着来基本没问题。
5.1 环境准备
确保设备上已经有
环境,建议用虚拟环境隔离依赖——这算是个好习惯。Python 3.8+
# 创建并激活虚拟环境python -m venv pawbench-env# Windows激活pawbench-envScriptsactivate# Linux/Mac 激活source pawbench-env/bin/activate
安装项目依赖,进到项目根目录后跑:
pip install -r requirements.txt
5.2 源码拉取
通过 Git 把官方仓库的代码克隆下来就行:
git clone https://github.com/agentscope-ai/PawBench.gitcd PawBench
5.3 配置文件修改
进到 configs/ 目录,打开全局配置文件,主要做三件事:
填上你要测试的
;大模型接口地址、密钥、模型名称
选择要启用的
(Qwenpaw / Openclaw / Hermes),可以单选,也可以多选;智能体框架
根据需要设好测试并发数、任务超时时间、测试用例范围这些参数。
5.4 启动评测任务
所有配置就绪之后,回到项目根目录,直接执行启动命令跑全量测试:
python run.py
要是想只跑一部分任务,可以追加参数限定范围,比如:
python run.py --task partial
5.5 查看评测结果
任务跑的过程中,控制台会实时输出每个测试单元的运行状态和执行结果;
全部任务跑完之后,结构化的评测报告、日志文件、统计表格会自动生成到
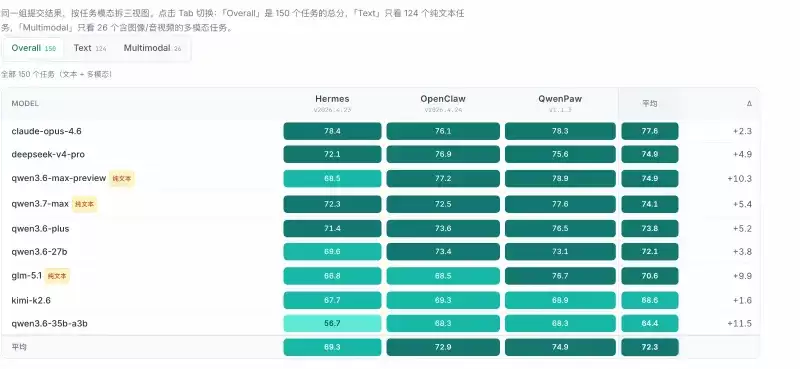
reports/目录里;打开目录里的 HTML 或 JSON 格式报告,综合得分、成功率、错误分类这些数据一目了然。
八、相关链接
GitHub仓库地址:https://github.com/agentscope-ai/PawBench
项目官网主页:https://agentscope-ai.github.io/PawBench/
九、总结
整体来看,PawBench 的出现,本质上是在做一件很多人想做但没做成的事——把 AI 智能体评测从“测模型”升级到“测系统”。它打破了传统评测只能看模型单体能力的局限,用模型、框架、真实任务三维结合的方式,给出了更贴近实际落地的评估结果。再加上标准化的海量测试用例、多生态的原生兼容、自动化的跑测和结果分析、以及低门槛的部署方式,让它成了 AI 智能体研发、选型和优化环节里一个真正实用的工具。不管是个人开发者、中小企业还是科研机构,都能从这套体系里拿到实在的反馈。确实,在面向落地场景的智能体评测领域,这算得上是目前开源社区里非常优质的一套解决方案。




