
澳洲放羊大叔引爆AI编程革命,Claude Code急推goal模式,不干完不许停
【导读】澳洲牧羊大叔随手写的三行bash,11天内被OpenAI、Anthropic和Hermes集体收编了。
一觉醒来,Claude Code又更新了!
为了让Claude持续工作直到任务完成,Claude Code最近推出了一个新功能:/goal。
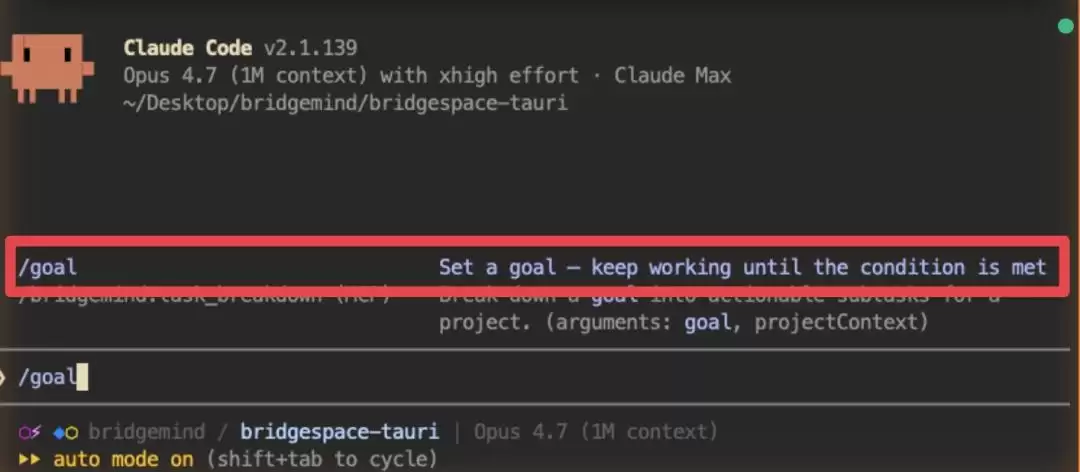
你只要设定好条件,Claude就会像上了发条一样,不完成任务绝不罢休。
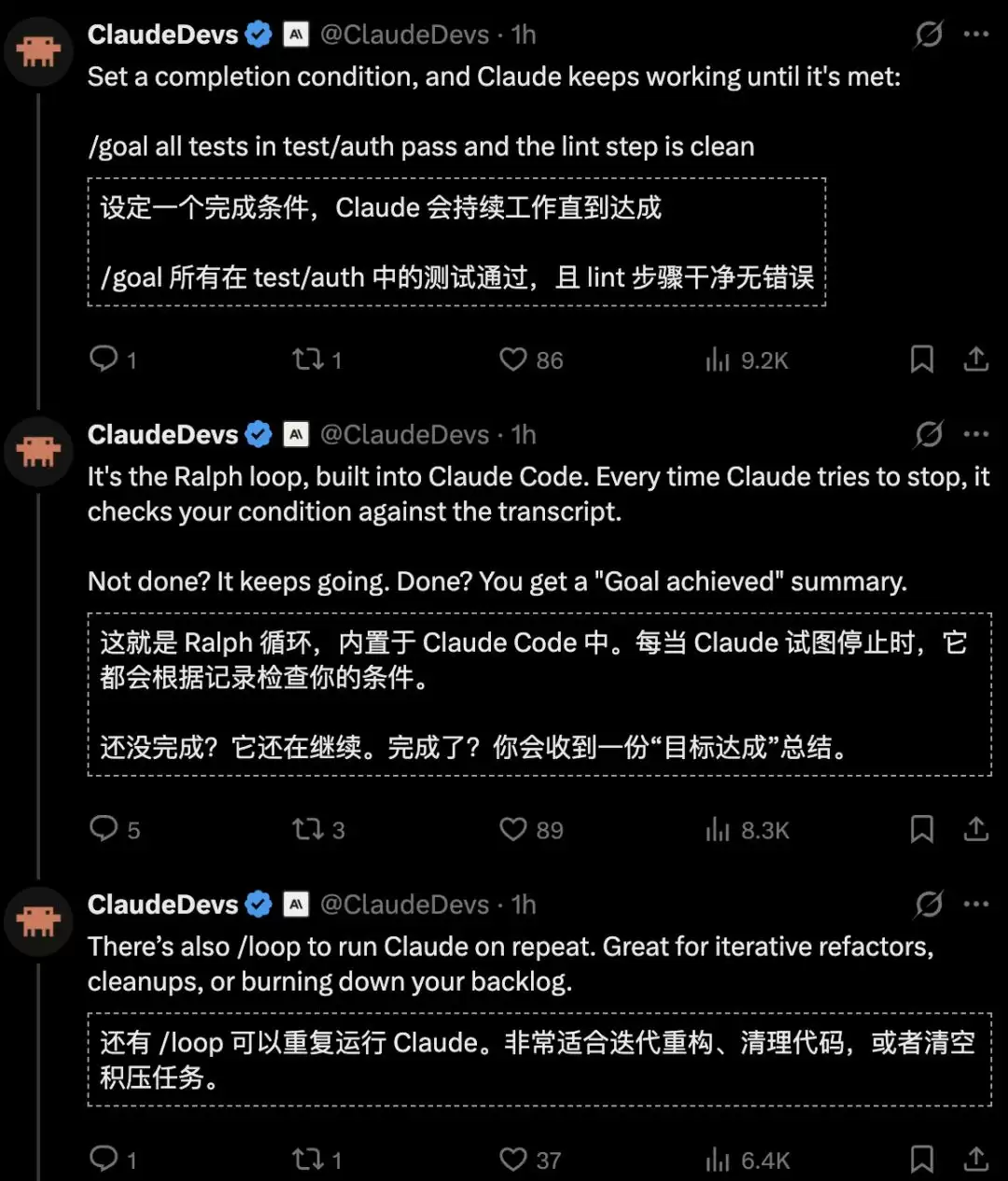
用过AI编程工具的人,瞬间就能明白这有多重要。
想想看,你给Agent下了一个任务,它跑了三个回合,改了俩文件,突然停下来问你:“接下来需要我做什么?”
等等,那个bug你还没修完呢!

Agent们越来越聪明,写代码越来越快,但“从头到尾把一件事干完”这个看似简单的要求,直到2026年初,都没有一家能真正搞定。
然后,
一位来自澳大利亚的牧羊大叔Geoffrey Huntley,用三行bash解决了。
- while:;do
- cat PROMPT.md | claude-code --continue
- done
他把它命名为
Ralph Loop
逻辑极其粗暴:无限循环,反复把同一个prompt喂给Agent。进度写在文件系统和Git历史里,上下文满了就开新实例,读文件接着干。
原始,不优雅,但十分有效。
有效到OpenAI看见了,Nous Research看见了,Anthropic也看见了。
短短11天,三家顶级AI实验室,不约而同地把这三行bash的精髓写进了官方产品。
这一刻,所有人都明白了一件事——
通用人工智能的临门一脚,可能不是更聪明的模型,而是“能把事做完”的模型。
换句话说,AI编程的核心战场正在从“生成代码”转向“闭环交付”。
11天,三条线,同一个终点
11天,三条线,同一个终点
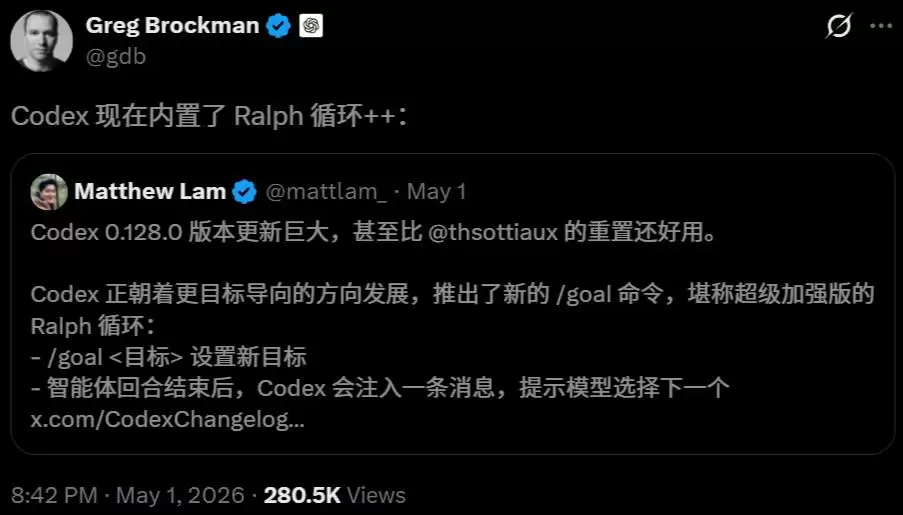
4月30日,OpenAI的Codex率先上线了/goal功能。
Greg Brockman在X上只轻描淡写地丢了一句:“Codex现已内置Ralph loop++”。
一周后,Hermes Agent跟上了。又过了4天,Claude Code也加入了战局。
11天,三家,同一个命令,同一个核心功能。
但三家的实现路径,却差了十万八千里。
简单概括就是:Codex“不忘事”,Hermes“不烂尾”,Claude Code“不自欺”。
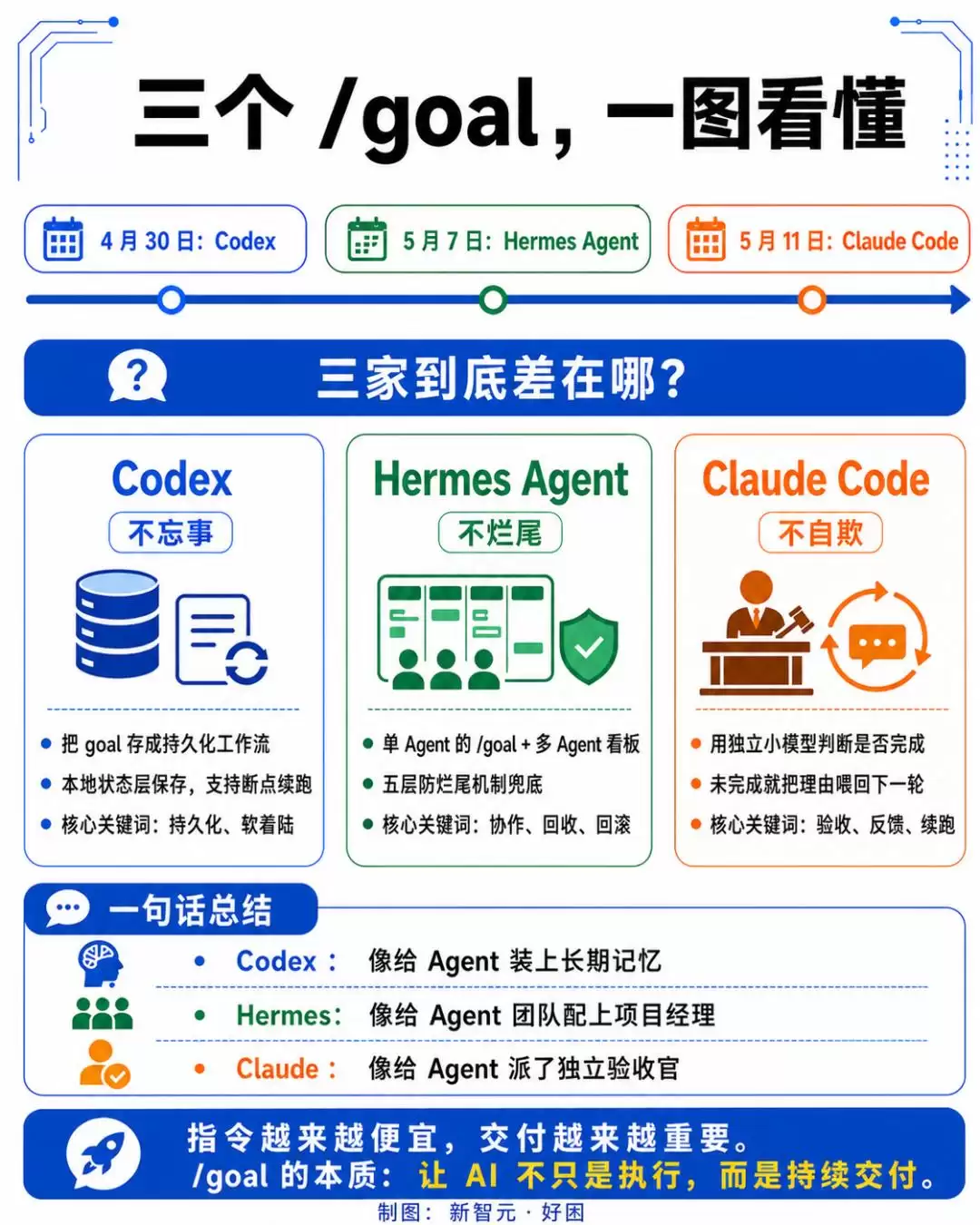
Codex:把目标存成一条数据库记录
Codex:把目标存成一条数据库记录
OpenAI是三家里最先出手的,方案也最简洁、最工程化。
在Codex里,/goal被实现为一个持久化的工作流对象,直接存储在本地app-server的状态层里。
这意味着,关掉终端、合上笔记本、甚至重启系统,你的目标都不会丢失。下次打开Codex,它会自动从上次中断的地方接上。

模型通过一个结构化的`update_goal`工具来汇报进度状态。当token预算耗尽时,系统触发的是“软着陆”而非硬性停止。
已经有用户用这个功能连续跑了14个小时,中间暂停5小时去睡觉,回来发现Codex能从断点处继续运行,最终把一个复杂的设备驱动项目给做完了。
整个方案透着一股工程师的克制与干净。

Hermes Agent:一个人干不完,那就上一个团队
Hermes Agent:一个人干不完,那就上一个团队
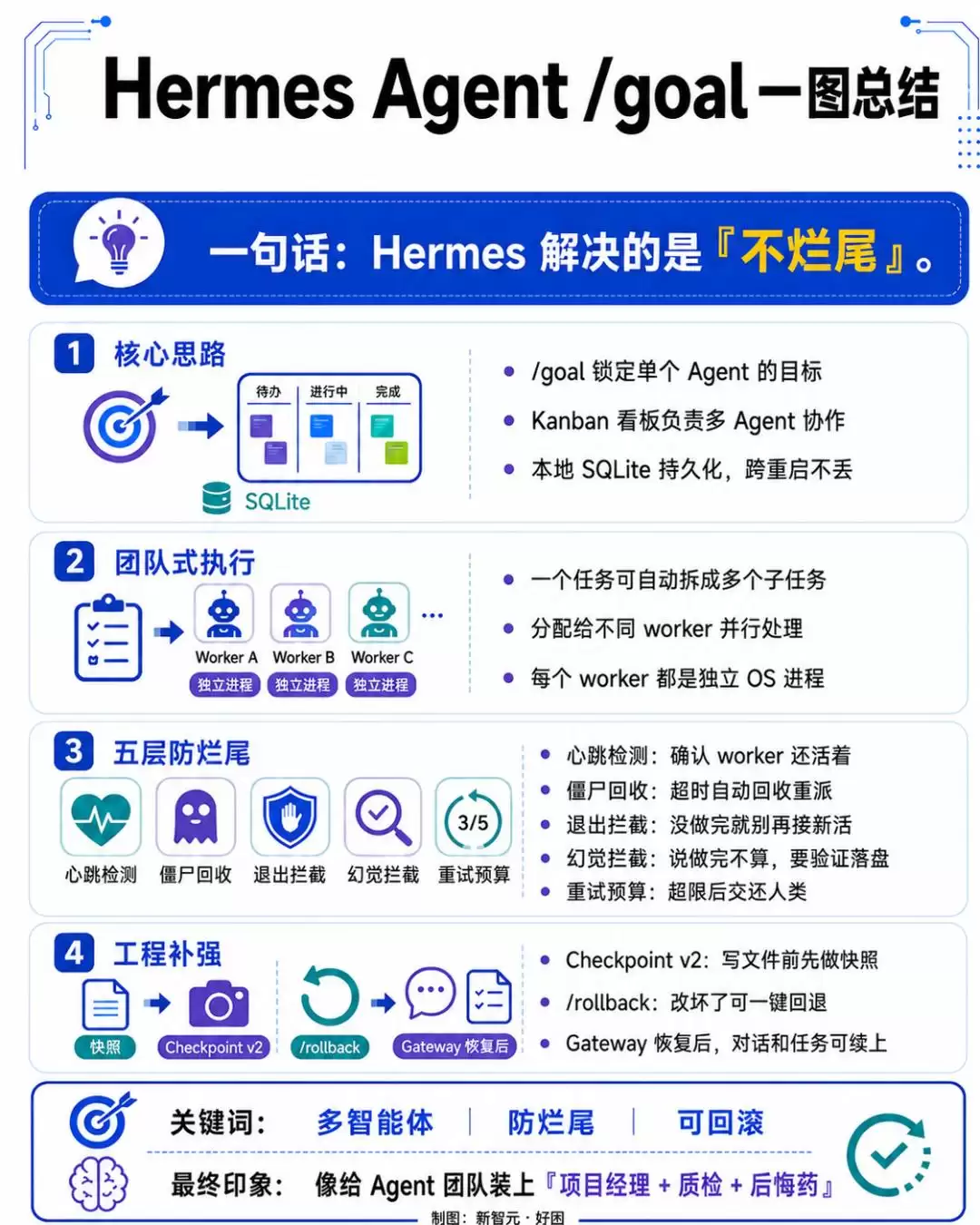
相比之下,Hermes Agent的野心要大得多。
在这里,/goal只是冰山一角。真正的重头戏是其多智能体看板系统。Hermes把“让AI把活干完”这个问题,从单Agent的耐力赛,升级成了多Agent的团队协作。

看板的底层是本地SQLite数据库,同样具备持久化存储能力,跨重启不丢数据。
你在看板上创建一个任务卡片,Hermes会直接把它拆解成多个子任务,分配给不同的Agent worker。每个worker都是一个独立的操作系统进程,拥有自己的身份、模型配置和工作目录。
看板和/goal是两套互补的系统。/goal管的是单个Agent的目标锁定(即Ralph loop的核心),而看板管的是多个Agent之间的任务调度与协作。一个纵向深入,一个横向铺开。
最值得称道的是其五层防烂尾机制,堪称Agent界的“安全生产规范”。
第一层,心跳检测。
第二层,僵尸回收。
第三层,退出拦截。
第四层,幻觉拦截。
第五层,重试预算。
Claude Code:做事的人和验收的人,不能是同一个
Claude Code:做事的人和验收的人,不能是同一个
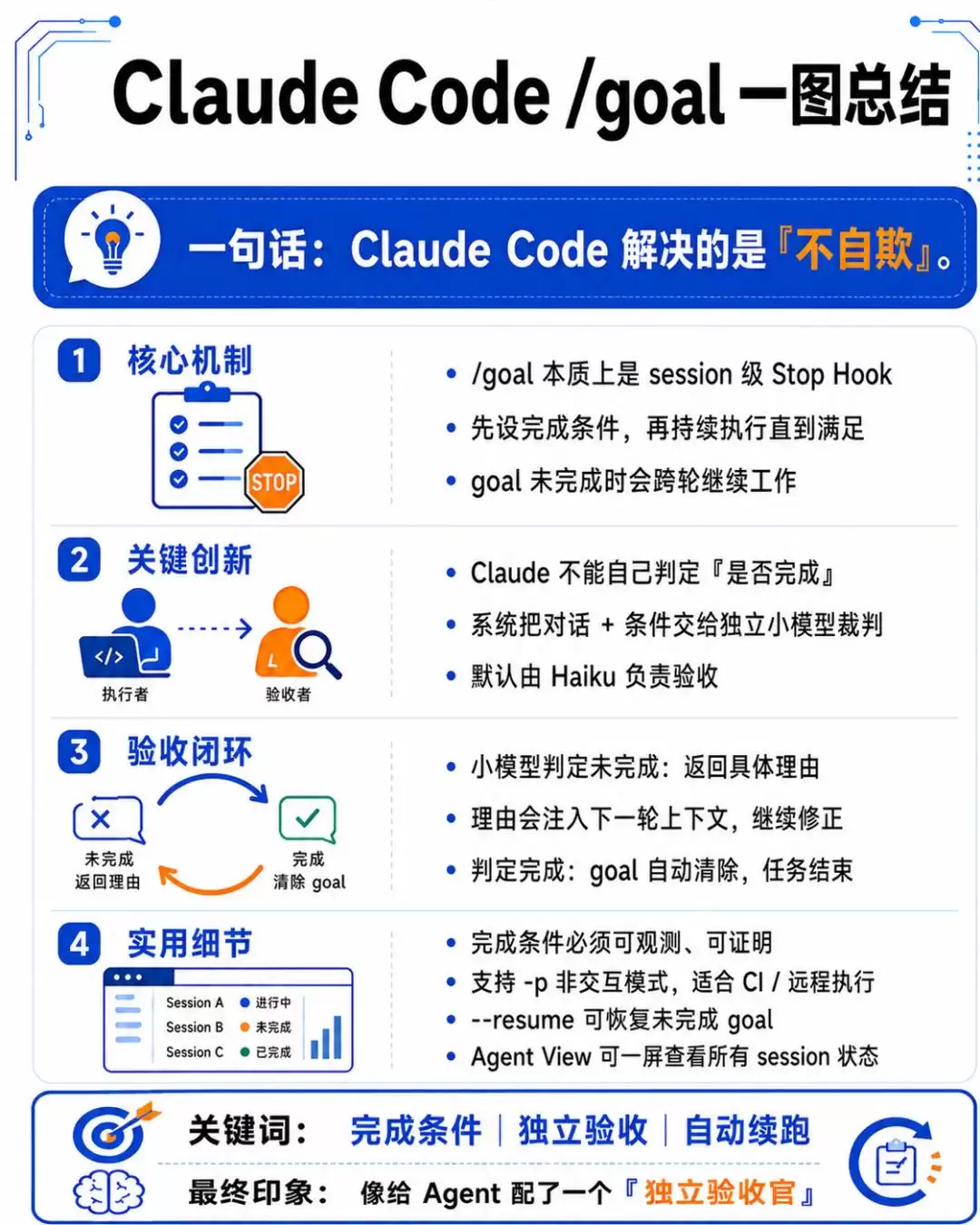
Anthropic是三家里最后出手的,但方案设计得最为巧妙,直指Agent工作的一个核心痛点:自我评估的偏差。
本质上,Claude Code的/goal是一个session级别的停止钩子(Stop Hook)。
你设定一个明确的完成条件(比如“test/auth目录下所有测试通过且lint无报错”),Claude就开始埋头干活。

关键设计在于验收环节。每干完一轮,系统
不让Claude自己判断“我做完了没有”
它会将完整的对话记录和你设定的完成条件,一起发送给一个独立的、更轻量的小模型(默认是Haiku),由这个小模型来充当“裁判”。
裁判模型如果觉得没完成,就必须返回一个具体的理由(比如“test_login.py里还有2个测试失败”)。这个理由会被精准注入Claude下一轮的上下文,指导它进行针对性修复。
如果裁判模型认为条件已满足,目标就会自动清除,任务优雅结束。
值得一提的是,这个裁判模型不调用任何工具,不读取文件系统,不执行命令。它只基于Claude在对话中产出的内容进行判断。
因此,你设定的完成条件,必须是Claude能在对话中证明的东西。条件最长支持4000字符,足够你写得非常细致。
你甚至可以在条件里附加约束,比如“不修改其他测试文件”、“20轮内完成否则停止”等等,实现更精细的控制。
决赛进行时:工作流入口
决赛进行时:工作流入口
把视角拉远一步看。
Claude Code背后站着Anthropic,Codex背后是OpenAI,而Hermes Agent同时接入了两家的模型,并且也是DeepSeek V4等模型的主力分发渠道。
这三条技术路径,恰好覆盖了当前ASI(人工通用智能)决赛圈的三个主要生态入口。
而他们争夺的,其实是同一样东西:
工作流
谁的Agent能率先让开发者养成“设完目标就走开,回来验收成果”的习惯,谁就锁死了下一代开发工作流的入口。
因为这种工作习惯一旦形成,迁移成本是指数级上升的。你不会轻易离开一个已经跑通了看板调度、断点续传、检查点回滚的成熟Agent基础设施。
一个看似微小的`/goal`命令,背后卡的,其实是整条Agent工作流生态的护城河。这场关于“完成度”的竞赛,才刚刚开始。




