
摩尔线程 × 中科院计算所丨DeferredGS全栈国产化适配落地
先说一个核心判断:摩尔线程与中科院计算技术研究所这次联手,在国产GPU软硬件生态协同上,实打实地迈出了一大步。双方基于摩尔线程旗舰级AI训推一体智算卡MTT S5000的算力,完成了高斯泼溅解耦表示与重光照方法DeferredGS的全栈国产化适配。这不仅是算力兼容性的验证,更意味着国产三维重建与渲染技术从底层到应用有了真正自主可控的路径。
过去几年,高斯泼溅作为可微三维表示方法,因兼顾高质量实时渲染和高于传统神经辐射场的训练效率,迅速在三维重建、数字人、虚拟现实和数字孪生等领域找到用武之地。中科院计算所团队提出的DeferredGS方法,巧妙引入了延迟渲染管线,把场景的几何属性与材质解耦——这样一来,就能实现高斯泼溅场景的实时重光照,而且避免了几何属性对输入光照的过拟合,效果自然更真实。
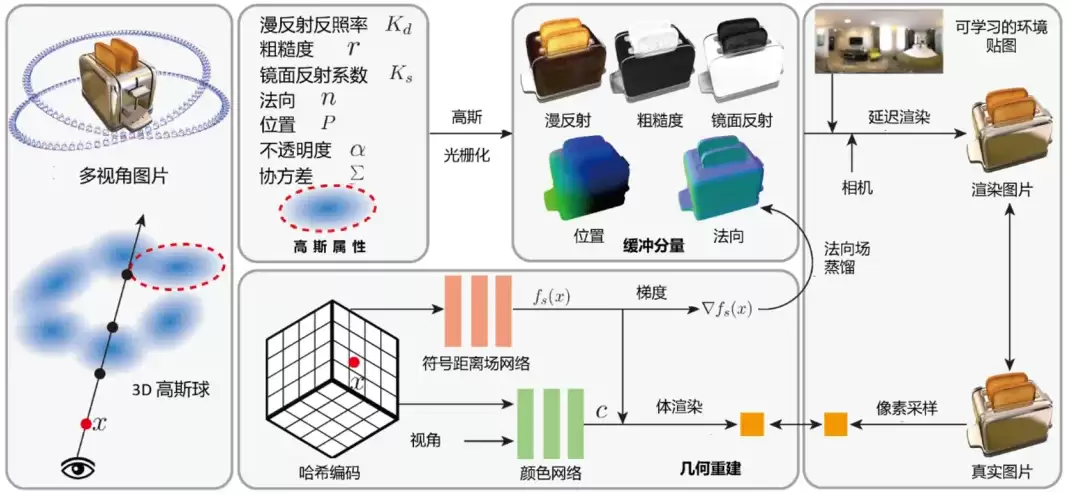 图1:高斯泼溅解耦表示与重光照方法DeferredGS示意图
图1:高斯泼溅解耦表示与重光照方法DeferredGS示意图
DeferredGS能落地,离不开国产深度学习框架的支撑。清华计算机系研发的计图框架(Jittor),凭借元算子和统一计算图的创新架构,在算子优化效率和异构硬件适配上有独特优势。中科院计算所基于计图推出了计图高斯库,把高斯泼溅技术扩展到几何变形、渲染优化、属性解耦与重光照、风格化等多种任务,同时提供统一算法接口和高效训练框架——这大幅降低了复用门槛。而DeferredGS正是这个库中的核心技术,代表了高斯泼溅在材质解耦与重光照方向的前沿水平。
以往,这类涉及高斯泼溅光栅化和延迟渲染的复杂方法,训练和推理都高度依赖海外GPU生态。为了打破这一壁垒,双方团队扎扎实实地做了底层适配:利用摩尔线程的MUSA软件栈,完成了计图框架、高斯泼溅光栅化及延迟渲染管线GPU算子的MUSA迁移。最终在MTT S5000上完整复现了DeferredGS的训练与推理(如图2所示)。这一成果显著提升了高斯泼溅这一前沿三维技术在国内GPU上的可用性和可复现性,降低了对海外GPU生态的依赖。
 图2:DeferredGS 在摩尔线程全功能GPU上的渲染结果(右)
图2:DeferredGS 在摩尔线程全功能GPU上的渲染结果(右)
从底层算力到深度学习框架,从三维重建算法到渲染管线——这套完全自主的全国产方案,是国产GPU生态在复杂科研与产业应用方向的一次扎实探索。随着更多开发者加入国产技术栈,一个自主、开放、繁荣的软硬件协同生态正在加速成形。基于摩尔线程MUSA的计图框架代码已在Github开源,开发者通过pip安装后即可直接使用,无需额外环境配置;基于计图的深度学习算法开发教程可参考计图官方教程。值得关注的是,这套生态的成熟将为中国在下一代图形学与人工智能领域的竞争赢得更多主动权。




