
Hermes团队改写预训练:算力成本降六成,DeepSeek之后提效新路径
模型能力必须持续提升,但训练成本却不能再无限制地堆砌了——这几乎是当前AI行业最强烈的共识。
无论是开发者还是模型公司,关注的焦点已经不只是“谁家的模型更强”,而是一个更务实的问题:“在同样的GPU数量和训练时长下,能不能跑出更多有效实验,消化更多高质量数据,最终拿到更低的损失值和更好的下游任务指标?”
凭借Hermes Agent(在GitHub上已收获超过14万颗星)迅速出圈的Nous Research团队,最近提出了一种名为“Token Superposition Training”(TST,词元叠加训练)的新方法。这种方法的目标很明确:有望将大模型的预训练成本降低一个数量级。

相关论文《Efficient Pre-Training with Token Superposition》已在arXiv发布,其中一组百亿参数MoE模型的实验结果尤为引人注目。
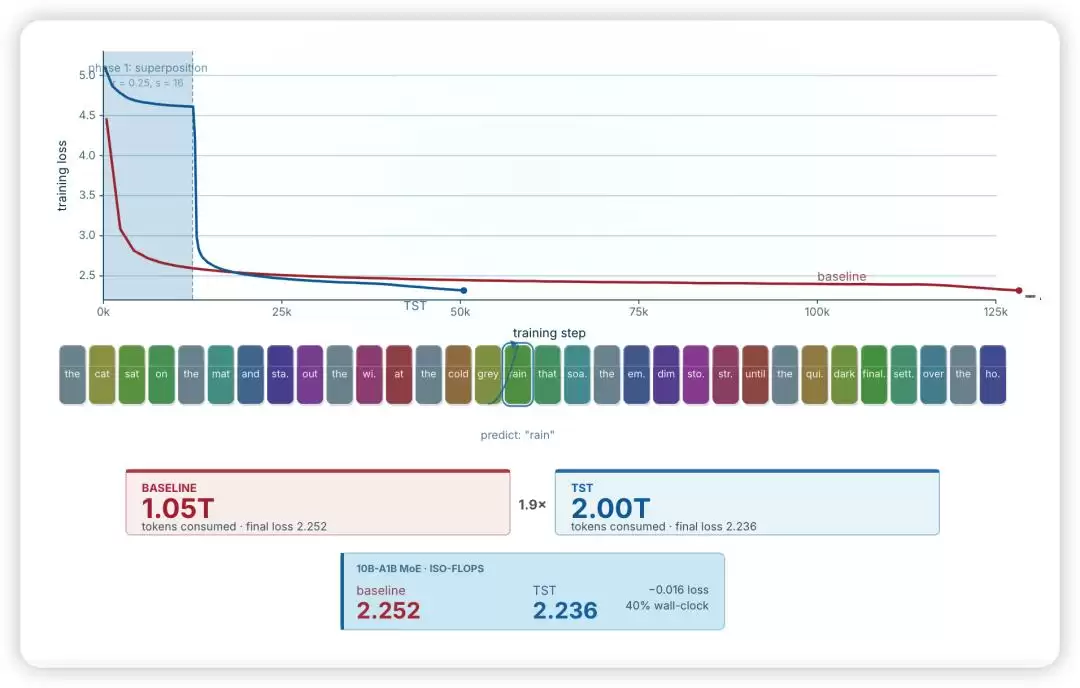
- 基线模型训练了1.05万亿个词元,消耗了12311个B200 GPU小时。
- 而采用TST方法的模型,训练了2万亿个词元,仅消耗了4768个B200 GPU小时,约为基线模型的38.7%。
- 与此同时,最终损失值从2.252降至2.236,在HellaSwag、ARC-E、ARC-C、MMLU等零样本评测基准上,性能也同步提升。
这意味着什么?TST方法只用了大约四成的GPU时间,不仅跑出了更低的损失值,还获得了更好的下游任务表现。换算一下,在达到相同最终损失的前提下,预训练时间被压缩到了原来的40%左右,提速约2.5倍。
如果说,此前在OpenRouter排行榜上超越Claude 3.5 Sonnet的Hermes Agent,证明了Nous Research团队不仅擅长训练模型,还能通过Agent技术将模型能力调校到极致;那么这次提出的TST,则是将视线从“模型怎么用”拉回到了能力的源头,直指预训练过程本身的效率优化。
业界常将Nous Research与DeepSeek相提并论,不仅因为两者都长期坚守开源阵营,更因为它们在降低训练成本的路径选择上截然不同。
DeepSeek代表的是系统级的重构路线,无论是MoE架构、MLA注意力,还是各种稀疏化与并行优化技术,核心都是通过底层工程来极致压榨算力效率。这种提升往往伴随着额外的工程复杂度。
而Nous Research的TST,则选择重写模型在预训练早期的学习路径。它不触碰模型架构本身,而是从模型学习词元的方式下手,切口更轻巧,理论上也更容易落地集成到现有训练流程中。
TST:让模型先“粗读”,再“精读”
TST:让模型先“粗读”,再“精读”
要理解TST,得从预训练最基础的任务说起:下一个词元预测。
在标准训练中,模型看到前面的一系列词元,然后预测紧接着的下一个词元是什么。这个机制简单而强大,过去几年绝大多数主流大语言模型都是在这个范式下堆砌出来的。
但TST提出了一个很根本的疑问:
模型在预训练的最初阶段,真的有必要逐词元地进行“精读”吗?
Nous Research的答案是否定的。他们将预训练过程拆解为两个阶段。
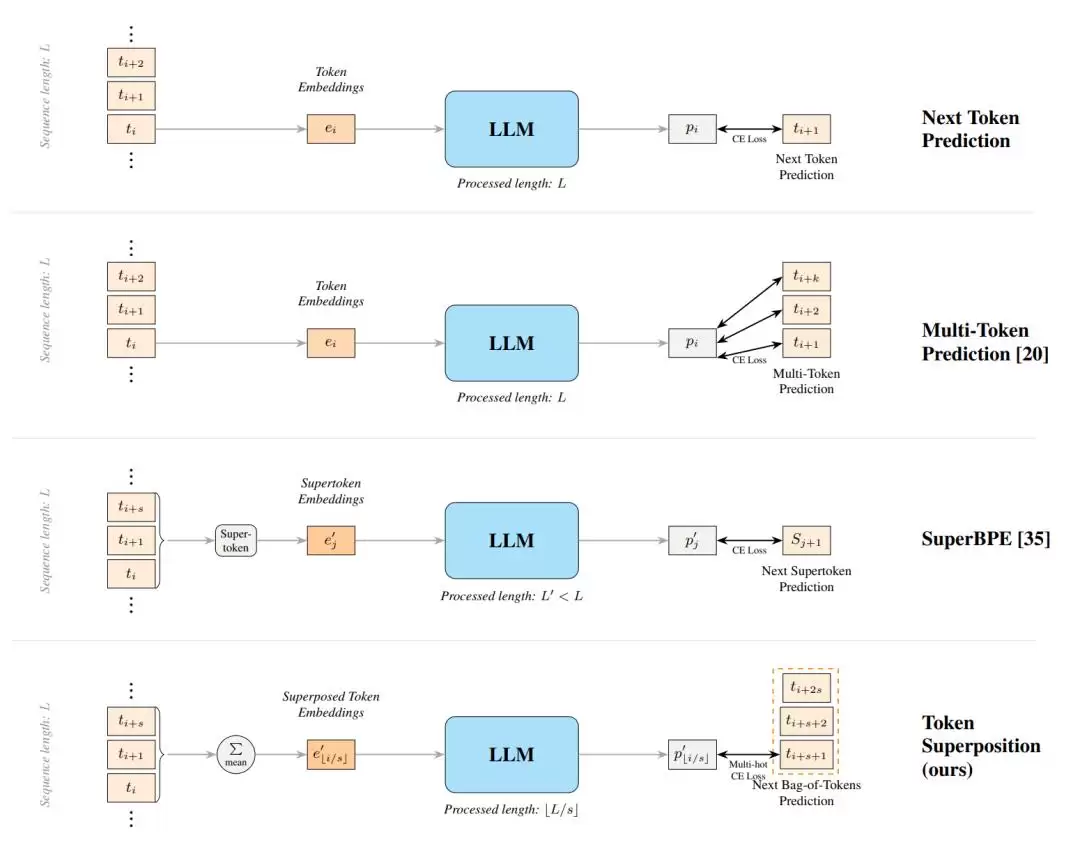
第一阶段称为“叠加阶段”。在训练前期,模型不再逐个处理词元,而是将连续多个词元打包成一个“袋”。例如,当袋大小为8时,就把连续的8个词元视为一组。
在输入侧,模型会将这一组词元的向量表示求平均,压缩成一个单一的“叠加词元”。在输出侧,模型的预测目标也随之改变:不再是预测下一个具体的词元,而是预测接下来这一组词元中可能会出现哪些词元(一个多标签分类问题)。
第二阶段则是“恢复阶段”。当训练进行到一定比例(例如总步数的20%-40%)后,TST机制被移除,模型切换回标准的“下一个词元预测”训练。也就是说,训练的后半程完全按照普通大语言模型的方式进行,目的是将前期“粗粒度学习”获得的语义表示,精细化为可生成、可部署的自回归模型。
论文将TST称为一种“即插即用”的预训练方法,关键就在于此:它不需要修改并行策略、优化器、分词器、训练数据或最终的模型架构。
真正改变的,只是训练早期输入数据的粒度和监督学习的目标。
这也让它与许多训练提效方案区别开来:
TST只改变训练过程,不改变最终的推理模型。
当然,全程使用TST训练是不可行的。论文明确指出,如果模型自始至终都使用TST,它会输出多个未来词元的混合概率,导致生成结果混乱。因此,
后期切换回标准自回归训练是必不可少的步骤。
这也就解释了,为什么TST更适合被理解为一种“阶段化的训练策略”,而非对“下一个词元预测”范式的彻底替代。
说得更直白些,TST做的事情,有点像让模型在预训练早期先进行“粗读”:快速掌握局部语义、词汇共现和粗粒度的概率分布。等到模型建立起基础的语言表示之后,再切换回“精读”模式,通过标准的逐词元训练来补全精确的生成能力。
为什么能节省GPU?关键在于每一步都“吃”进更多文本
为什么能节省GPU?关键在于每一步都“吃”进更多文本
TST带来的提速效果并非玄学,其核心是一种资源上的权衡:
用更粗糙的词元表示,换取更高的数据吞吐量。
这里的数据吞吐量,对应论文中的“单位浮点运算所能处理的原始文本量”。简单来说,不是GPU突然变快了,而是在进行同样一次计算时,模型能“看到”的文本内容变多了。
在标准训练中,模型序列的每个位置处理一个词元。假设序列长度为L,Transformer就需要处理L个向量表示。
但在TST的叠加阶段,连续的s个词元被合成一个叠加词元。此时,模型内部需要处理的序列长度变短了,但每个位置所对应的原始文本信息量却变成了原来的s倍。因为模型是在更粗粒度的表示上进行计算,所以在消耗相同浮点运算量的前提下,它可以处理s倍数量的原始数据词元。
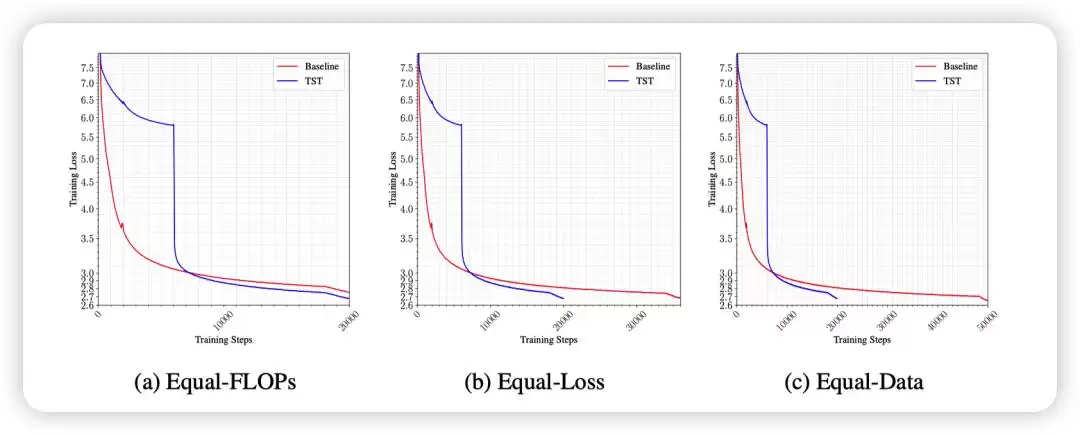
传统的预训练好比逐字精读,而TST的早期训练则像是先快速浏览段落大意,抓住主题和关键词。这种“粗读”当然有代价——它会丢失“袋”内词元的顺序信息,因此不能全程使用。但在模型刚刚接触语言统计规律的初期,这种低分辨率的输入反而够用且高效。
论文将此定义为一种“由粗到细”的策略:先让模型在简单、高吞吐的设定下学习粗粒度的统计结构,再恢复全分辨率的语言建模精度。
这与当前主流的其他效率提升路线形成了鲜明对比:
MoE
稀疏注意力
多词元预测
TST
它不是让模型体积变小,也不是直接让推理变快,而是让预训练早期的每一步计算都变得更“值钱”。
这一点对开发者至关重要。预训练从来不是一锤子买卖,而是一个不断试错、调整配方和超参数的过程。早期训练越快进入有效区间,就意味着数据混合策略、超参数设置等关键实验能越早得到验证。
说白了,
TST省下的不只是一次成功训练所消耗的GPU小时,更是整个研发周期中宝贵的试错成本和时间。
最大收益出现在百亿参数模型
最大收益出现在百亿参数模型
论文的实验并未局限于小模型,而是在270M、600M、3B的稠密模型,以及一个总参数量约100亿、每词元激活参数量约10亿的MoE模型上进行了验证。这个百亿级MoE模型,正是开篇提到的、收益最为显著的案例。
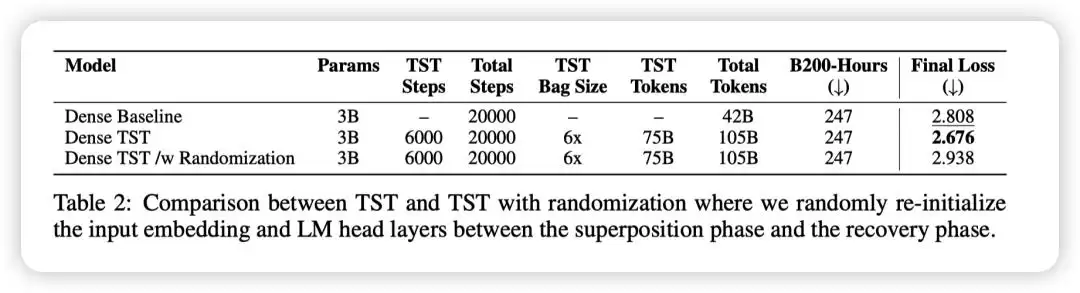
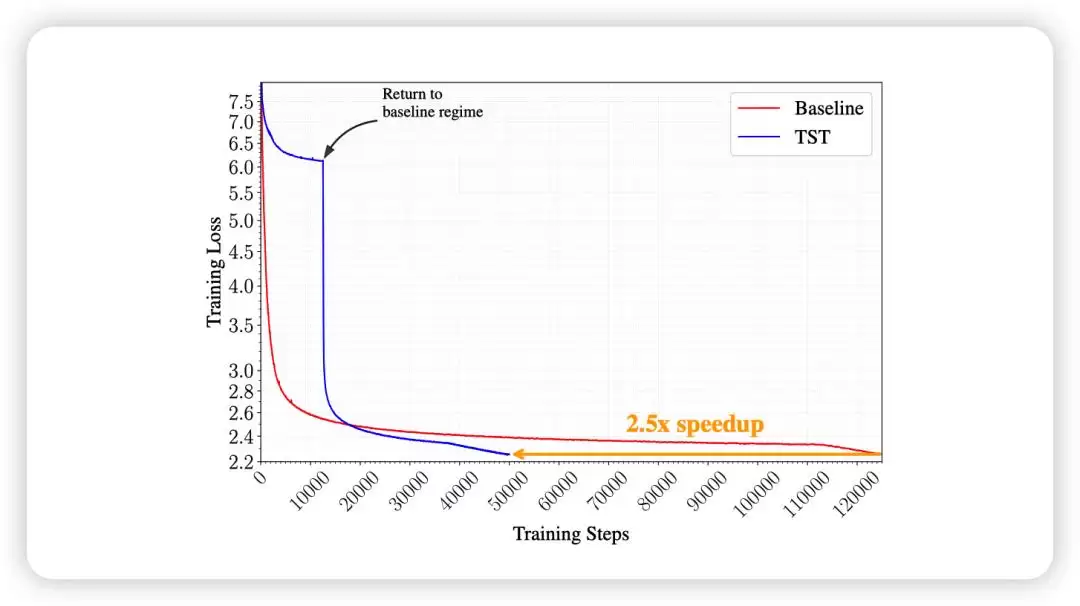
实验数据显示,TST方法消耗了更多的数据词元,但却用更少的GPU时间达到了更优的结果。在达到相同损失值的条件下,TST实现了约2.5倍的训练提速。
这个数字足以让任何进行大规模预训练的团队心动。因为在模型研发中,最昂贵的往往不是那一次最终成功的训练,而是成功之前所有的探索和试错。
一次实验就能节省一半以上的GPU时间,意味着同样的预算下,可以多尝试几组数据配方、多调试几轮超参数、多验证几个模型尺寸的可行性。
论文还进行了多组超参数扫描实验,观察不同“袋”大小和叠加阶段训练步数比例的影响。结论是,在合理范围内,TST对超参数的选择相对稳健:袋大小在4到8之间,叠加训练步数比例在0.2到0.4时,通常能取得较好的效果。
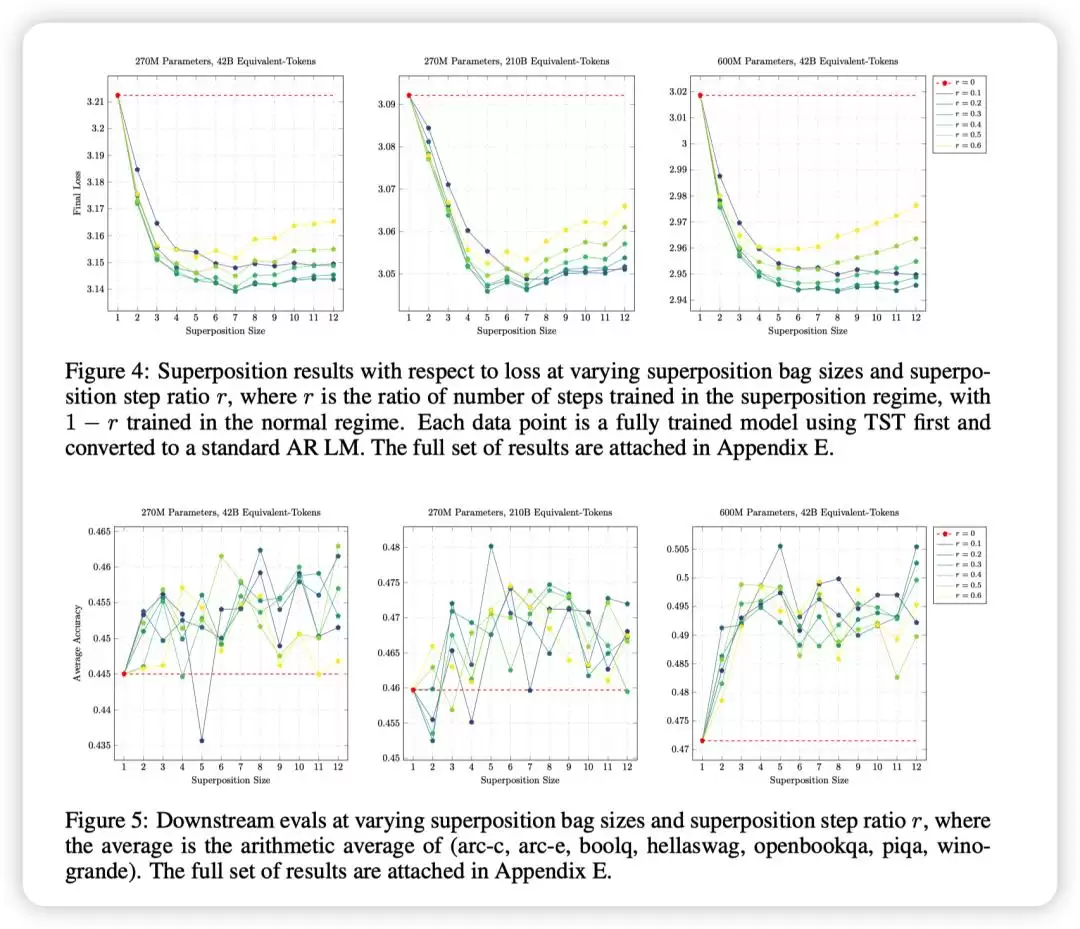
此外,TST的收益并非单一机制所致。论文通过消融实验发现,单独使用输入侧的“叠加”或输出侧的“多标签预测”,都能优于基线,但两者结合(即完整的TST)效果最佳。这表明,
TST是两个机制的协同作用:输入侧改变了信息粒度,降低了单位信息的计算成本;输出侧改变了预测目标,提供了更密集的监督信号。
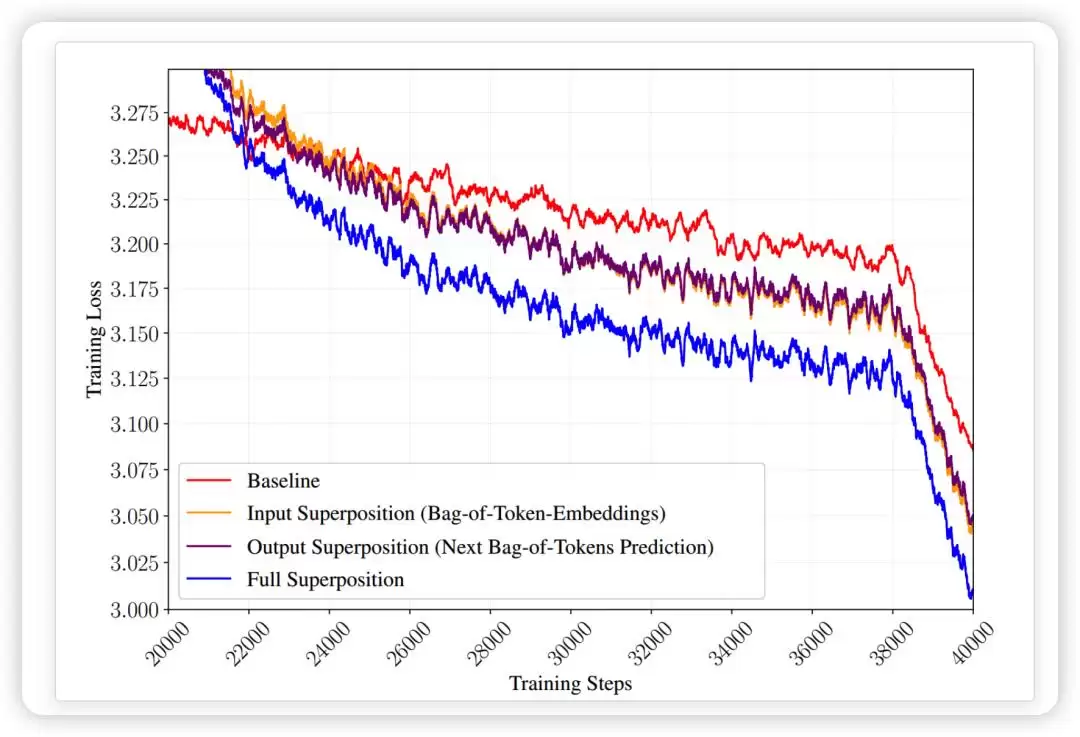
这套机制的启发在于,输入侧在训练早期给了模型一个低分辨率视野,让它以更低成本接触更多文本;输出侧则像是把监督问题从“下一个词是什么”改成了“接下来这一小段大概会包含哪些词”。前者提高了数据吞吐,后者提高了学习效率。
这也正是TST与单纯的多词元预测技术本质上的不同。后者是在同一位置额外预测多个未来词元;而TST则是同时改变了输入和输出的粒度。
一个是增加了监督任务的数量,一个是改变了学习任务的分辨率。
训练降本的新思路:转向学习路径优化
训练降本的新思路:转向学习路径优化
TST最值得玩味的地方,不在于它设计了多么复杂的架构,而在于它揭示了一个趋势:
训练降本增效,未必总要盯着模型结构大动干戈。
过去一提降低成本,行业本能反应往往是增加算力、修改架构、优化并行、进行知识蒸馏。这些都是系统级的“重体力活”,没有雄厚工程实力的团队很难承接。但TST提供了一个轻量得多的切入点:
只调整预训练早期的学习路径和训练目标。
这意味着什么?对于广大开发者而言,同样规模的GPU预算下,可以进行更多轮的实验;对于专注于1B到10B参数规模的垂直领域模型团队来说,试错成本有望显著下降。
这比盲目追逐前沿的千亿参数模型,要务实得多。
当然,TST也并非免费的午餐。它本质上是“用数据吞吐量置换GPU计算时间”。
对于算力紧张但拥有高质量数据集的团队,这无疑是一剂良方。
但这并不影响其方向性的价值。TST把一个被默认太久的问题重新摆上了台面:
模型学习语言的顺序和方式,其本身就可能成为一个重要的效率杠杆。
当模型训练变得越来越昂贵,真正有价值的创新可能不只是如何把模型做得更大,而是如何让模型“更会学习”。更准确地说,是如何让训练过程中的每一步计算,都产生更高的价值。
参考链接:
论文:http://arxiv.org/abs/2605.06546




