
虾马之后又火一个!OpenHuman用20分钟了解你的一切,存成卡帕西式知识库
Agent赛道最近真是热闹,“虾”和“马”各领风骚,没想到半路又杀出个新物种——
OpenHuman
不过,它火起来的原因,可能恰恰是因为它走了条不一样的路。之前的“虾”和“马”,本质上还是用户在教AI做事:你得配置技能、编写提示词、调整工作流。说穿了,
你得先动,它们才动
OpenHuman的思路反了过来:它不用你教,而是主动来了解你。连接你的Gmail、GitHub、Slack、Notion、日历等上百种服务后,它能每20分钟自动抓取一次新数据,并压缩构建成一个
本地知识库
20分钟了解你的Agent
这个设计的灵感,其实有迹可循。之前Karpathy公开过一个叫
LLM Wiki
整个过程全靠手工
OpenHuman干的事,就是把卡帕西这套手工活,变成了
全自动流水线
第一步是连接。
第二步是抓取。
第三步是记忆。
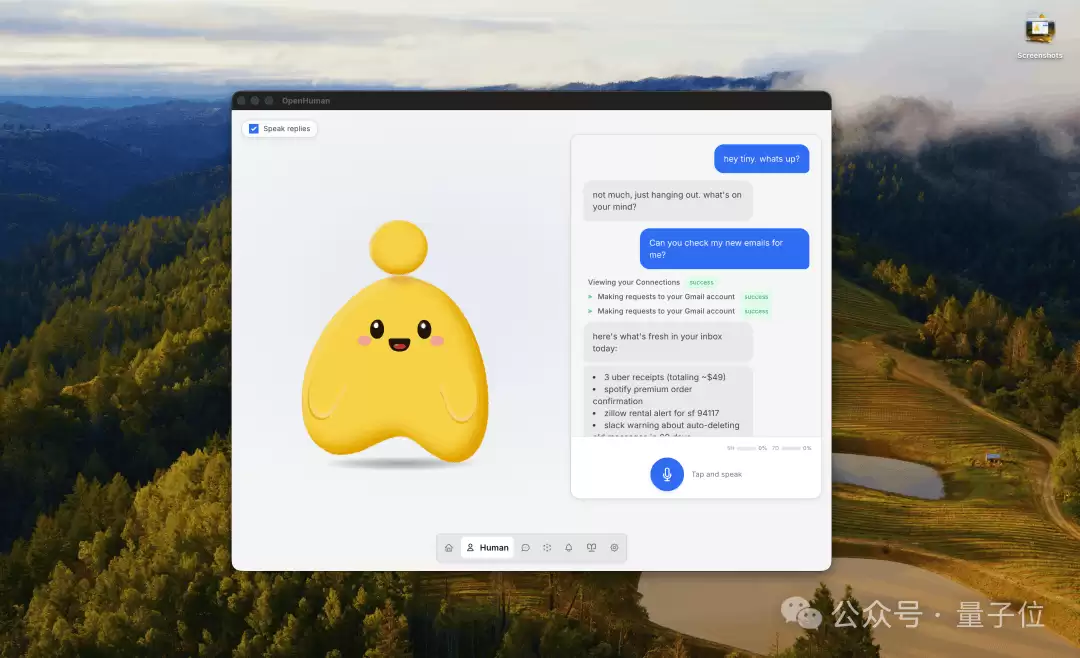
这棵树的本体是一个本地SQLite数据库。但同一份数据,还会同步生成.md文件,落地成一个完全兼容Obsidian的本地知识库。这意味着,你可以直接用Obsidian打开、浏览甚至编辑Agent的“记忆”。
除了记忆树,还有个挺实用的设计叫
TokenJuice
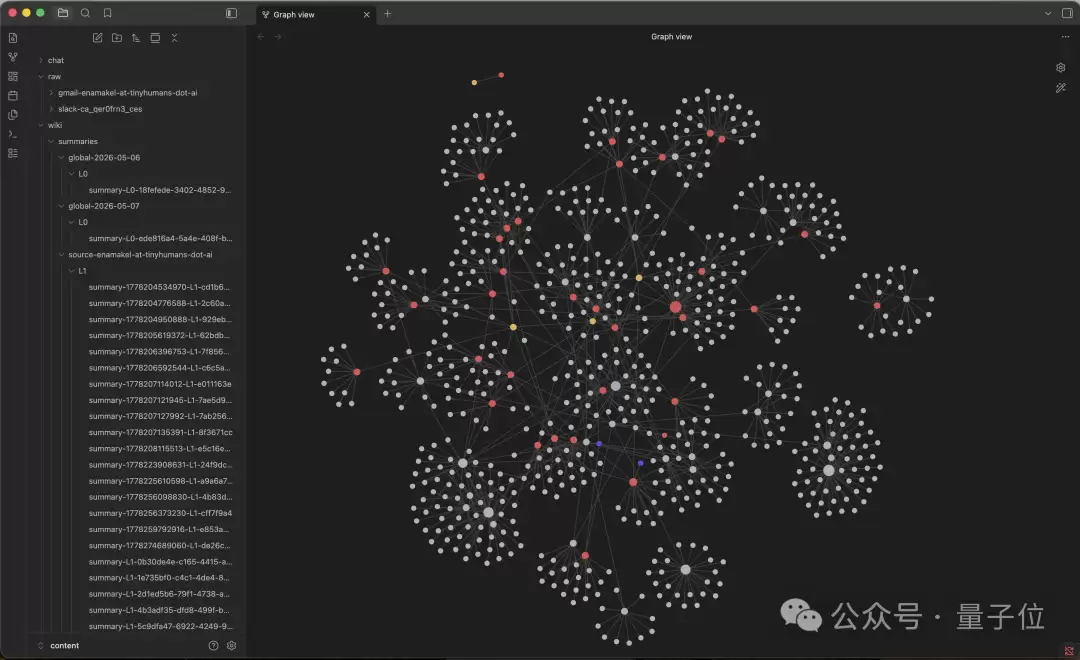
而且这套压缩规则用了三层叠加:内置默认规则、用户自定义规则、项目级规则,全都以JSON文件存储,修改后无需重新编译,灵活性很高。
此外,OpenHuman还有个有趣的Mascot功能,一个“会说话”的虚拟形象可以作为独立参会者加入Google Meet会议。你开会,它旁听并记录要点;你离开电脑,它则在后台继续执行待办任务。这得益于其
潜意识循环
懂你,还得Human来
如果横向对比一下,OpenHuman与Claude Cowork、OpenClaw、Hermes Agent等主流Agent相比,在上手门槛、成本、记忆能力、第三方集成、自动数据同步和模型调度等多个维度,都展现出一定的优势。

在“虾马”之后,OpenHuman还能引发关注,或许是因为它精准地踩中了开发者们的几个核心痛点:API密钥管理繁琐、各平台数据分散难以整合、上下文日益臃肿导致AI响应变慢。
而OpenHuman试图用一个账号搞定所有授权,免去反复注册和配置;内置上百种应用一键互联,自动将全平台数据同步至专属记忆树;整个过程在后台静默运行,并能通过压缩技术最高节省80%的Token消耗与响应延迟。
其实,这三个痛点分开看是功能问题,合起来看,反映的或许是更深层的问题:过去的许多Agent,心思大多花在“能干”上,但在“懂你”这个层面,始终差了口气。
“虾”解决了工具多的问题,“马”解决了能自学的问题,但真正试图去理解你、适应你节奏的,眼下看来,可能还得是这个新来的“Human”。





